Competitive learning
Competitive learning is a form of unsupervised learning in artificial neural networks, in which nodes compete for the right to respond to a subset of the input data.[1] A variant of Hebbian learning, competitive learning works by increasing the specialization of each node in the network. It is well suited to finding clusters within data.
Models and algorithms based on the principle of competitive learning include vector quantization and self-organising maps (Kohonen maps).
Architecture and implementation

Competitive Learning is usually implemented with Neural Networks that contain a hidden layer which is commonly known as “competitive layer”.[2] Every competitive neuron i is described by a vector of weights 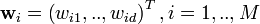 and calculates the similarity measure between the input data
and calculates the similarity measure between the input data 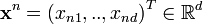 and the weight vector
and the weight vector 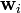 .
.
For every input vector, the competitive neurons “compete” with each other to see which one of them is the most similar to that particular input vector. The winner neuron m sets its output 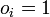 and all the other competitive neurons set their output
and all the other competitive neurons set their output 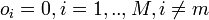 .
.
Usually, in order to measure similarity the inverse of the Euclidean distance is used: 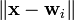 between the input vector
between the input vector 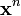 and the weight vector .
and the weight vector .
Example algorithm
Here is a simple competitive learning algorithm to find three clusters within some input data.
1. (Set-up.) Let a set of sensors all feed into three different nodes, so that every node is connected to every sensor. Let the weights that each node gives to its sensors be set randomly between 0.0 and 1.0. Let the output of each node be the sum of all its sensors, each sensor's signal strength being multiplied by its weight.
2. When the net is shown an input, the node with the highest output is deemed the winner. The input is classified as being within the cluster corresponding to that node.
3. The winner updates each of its weights, moving weight from the connections that gave it weaker signals to the connections that gave it stronger signals.
Thus, as more data are received, each node converges on the centre of the cluster that it has come to represent and activates more strongly for inputs in this cluster and more weakly for inputs in other clusters.
Also see
References
- ↑ Rumelhart, David; David Zipser; James L. McClelland et al. (1986). Parallel Distributed Processing, Vol. 1. MIT Press. pp. 151–193.
- ↑ Salatas, John (24 August 2011). "Implementation of Competitive Learning Networks for WEKA". ICT Research Blog. Retrieved 28 January 2012.
Further Information and Software
- Draft Report "Some Competitive Learning Methods" (contains descriptions of several related algos)
- DemoGNG - Java simulator for competitive learning methods