Comparison of programming paradigms
This article attempts to set out the various similarities and differences between the various programming paradigms as a summary in both graphical and tabular format with links to the separate discussions concerning these similarities and differences in extant Wikipedia articles.
Main paradigm approaches
The following are considered the main programming paradigms. There is inevitably some overlap in these paradigms but the main features or identifiable differences are summarized in the following table:
- Imperative programming – defines computation as statements that change a program state
- Procedural programming, structured programming – specifies the steps the program must take to reach the desired state.
- Declarative programming – defines computation logic without defining its control flow.
- Functional programming – treats computation as the evaluation of mathematical functions and avoids state and mutable data
- Object-oriented programming (OOP) – organizes programs as objects: data structures consisting of datafields and methods together with their interactions.
- Event-driven programming – the flow of the program is determined by events, such as sensor outputs or user actions (mouse clicks, key presses) or messages from other programs or threads.
- Automata-based programming – a program, or part, is treated as a model of a finite state machine or any other formal automata.
None of the main programming paradigms have a precise, globally unanimous definition, let alone an official international standard. Nor is there any agreement on which paradigm constitutes the best approach to developing software. The subroutines that actually implement OOP methods might be ultimately coded in an imperative, functional or procedural style that might, or might not, directly alter state on behalf of the invoking program.
| Paradigm | Description | Main characteristics | Related paradigm(s) | Critics | Examples |
|---|---|---|---|---|---|
| Imperative | Computation as statements that directly change a program state (datafields) | Direct assignments, common data structures, global variables | Edsger W. Dijkstra, Michael A. Jackson | C, C++, Java, PHP, Python | |
| Structured | A style of imperative programming with more logical program structure | Structograms, indentation, either no, or limited use of, goto statements | Imperative | C, C++, Java, Python | |
| Procedural | Derived from structured programming, based on the concept of modular programming or the procedure call | Local variables, sequence, selection, iteration, and modularization | Structured, imperative | C, C++, Lisp, PHP, Python | |
| Functional | Treats computation as the evaluation of mathematical functions avoiding state and mutable data | Lambda calculus, compositionality, formula, recursion, referential transparency, no side effects | Declarative | Erlang, Haskell, Lisp, Clojure, Scala, SML, F#, SequenceL, Python | |
| Event-driven including time driven | Program flow is determined mainly by events, such as mouse clicks or interrupts including timer | Main loop, event handlers, asynchronous processes | Procedural, dataflow | ActionScript | |
| Object-oriented | Treats datafields as objects manipulated through pre-defined methods only | Objects, methods, message passing, information hiding, data abstraction, encapsulation, polymorphism, inheritance, serialization-marshalling | See here and[1][2][3] | Common Lisp, C++, C#, Eiffel, Java, PHP, Python, Ruby, Scala | |
| Declarative | Defines computation logic without defining its detailed control flow | 4GLs, spreadsheets, report program generators | SQL, regular expressions, CSS, Prolog | ||
| Automata-based programming | Treats programs as a model of a finite state machine or any other formal automata | State enumeration, control variable, state changes, isomorphism, state transition table | Imperative, event-driven | AsmL |
Differences in terminology
Despite multiple (types of) programming paradigms existing in parallel (with sometimes apparently conflicting definitions), many of the underlying fundamental components remain more or less the same (constants, variables, datafields, subroutines, calls etc.) and must somehow therefore inevitably be incorporated into each separate paradigm with equally similar attributes or functions. The table above is not intended as a guide to precise similarities, but more an index of where to look for more information - based on the different naming of these entities - within each paradigm. Non-standardized implementations of each paradigm in numerous programming languages further complicate the overall picture, especially those languages that support multiple paradigms, each with its own jargon.
| “ | "You can know the name of a bird in all the languages of the world, but when you're finished, you'll know absolutely nothing whatever about the bird... So let's look at the bird and see what it's doing-- that's what counts. I learned very early the difference between knowing the name of something and knowing something. | ” |
Language support
Syntactic sugar is the sweetening of program functionality by introducing language features that facilitate particular usage, even if the end result could be achieved without them. One example of syntactic sugar may arguably be classes in C++ (and in Java, C#, etc.). The C language can support object-oriented programming via its facilities of function pointers, type casting, and structures. However, languages such as C++ aim to make object-oriented programming more convenient by introducing syntax specific to this coding style. Moreover, the specialized syntax works to emphasize the object-oriented approach. Similarly, functions and looping syntax in C (and other procedural and structured programming languages) could be considered syntactic sugar. Assembly language can support procedural or structured programming via its facilities for modifying register values and branching execution depending on program state. However, languages such as C introduced syntax specific to these coding styles to make procedural and structured programming more convenient. Features of the C# (C Sharp) programming language, such as properties and interfaces, similarly do not enable new functionality, but are designed to make good programming practices more prominent and natural.
Some programmers feel that these features are unimportant or even frivolous. For example, Alan Perlis once quipped, in a reference to bracket-delimited languages, that "syntactic sugar causes cancer of the semicolon" (see Epigrams on Programming).
An extension of this is the syntactic saccharin, or gratuitous syntax that does not make programming easier.[4]
Performance comparison
Purely in terms of total instruction path length, a program coded in an imperative style, without using any subroutines at all, would have the lowest count. However, the binary size of such a program might be larger than the same program coded using subroutines (as in functional and procedural programming) and would reference more "non-local" physical instructions that may increase cache misses and increase instruction fetch overhead in modern processors.
The paradigms that use subroutines extensively (including functional, procedural and object-oriented) and do not also use significant inlining (via compiler optimizations) will, consequently, use a greater percentage of total resources on the subroutine linkages themselves. Object oriented programs that do not deliberately alter program state directly, instead using mutator methods (or "setters") to encapsulate these state changes, will, as a direct consequence, have a greater overhead. This is due to the fact that message passing is essentially a subroutine call, but with three more additional overheads: dynamic memory allocation, parameter copying and dynamic dispatch. Obtaining memory from the heap and copying parameters for message passing may involve significant resources that far exceed those required for the state change itself. Accessors (or "getters") that merely return the values of private member variables also depend upon similar message passing subroutines, instead of using a more direct assignment (or comparison), adding to total path length.
Managed code
For programs executing in a managed code environment, such as the .NET Framework, many issues affect performance that are significantly affected by the programming language paradigm and various language features used.[5]
Pseudocode examples comparing various paradigms
A pseudocode comparison of imperative, procedural, and object oriented approaches used to calculate the area of a circle (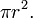 ), assuming no subroutine inlining, no macro preprocessors, register arithmetic and weighting each instruction 'step' as just 1 instruction - as a crude measure of instruction path length - is presented below. The instruction step that is conceptually performing the actual state change is highlighted in bold typeface in each case. Note that the actual arithmetic operations used to compute the area of the circle are the same in all three paradigms, with the difference being that the procedural and object-oriented paradigms wrap those operations in a subroutine call that makes the computation general and reusable. The same effect could be achieved in a purely imperative program using a macro preprocessor at just the cost of increased program size (only at each macro invocation site) without a corresponding pro rata runtime cost (proportional to n invocations - that may be situated within an inner loop for instance). Conversely, subroutine inlining by a compiler could reduce procedural programs to something similar in size to the purely imperative code. However, for object-oriented programs, even with inlining, messages still have to be built (from copies of the arguments) for processing by the object-oriented methods. The overhead of calls, virtual or otherwise, is not dominated by the control flow alteration itself - but by the surrounding calling convention costs, like prologue and epilogue code, stack setup and argument passing[6] (see here[7] for more realistic instruction path length, stack and other costs associated with calls on an x86 platform). See also here[8] for a slide presentation by Eric S. Roberts ("The Allocation of Memory to Variables", chapter 7)[9] - illustrating the use of stack and heap memory usage when summing three rational numbers in the Java object-oriented language.
), assuming no subroutine inlining, no macro preprocessors, register arithmetic and weighting each instruction 'step' as just 1 instruction - as a crude measure of instruction path length - is presented below. The instruction step that is conceptually performing the actual state change is highlighted in bold typeface in each case. Note that the actual arithmetic operations used to compute the area of the circle are the same in all three paradigms, with the difference being that the procedural and object-oriented paradigms wrap those operations in a subroutine call that makes the computation general and reusable. The same effect could be achieved in a purely imperative program using a macro preprocessor at just the cost of increased program size (only at each macro invocation site) without a corresponding pro rata runtime cost (proportional to n invocations - that may be situated within an inner loop for instance). Conversely, subroutine inlining by a compiler could reduce procedural programs to something similar in size to the purely imperative code. However, for object-oriented programs, even with inlining, messages still have to be built (from copies of the arguments) for processing by the object-oriented methods. The overhead of calls, virtual or otherwise, is not dominated by the control flow alteration itself - but by the surrounding calling convention costs, like prologue and epilogue code, stack setup and argument passing[6] (see here[7] for more realistic instruction path length, stack and other costs associated with calls on an x86 platform). See also here[8] for a slide presentation by Eric S. Roberts ("The Allocation of Memory to Variables", chapter 7)[9] - illustrating the use of stack and heap memory usage when summing three rational numbers in the Java object-oriented language.
| Imperative | Procedural | Object-oriented |
|---|---|---|
|
|
|
The advantages of procedural abstraction and object-oriented-style polymorphism are not well illustrated by a small example like the one above. This example is designed principally to illustrate some intrinsic performance differences, not abstraction or code re-use.
Subroutine, method call overhead
The presence of a (called) subroutine in a program contributes nothing extra to the functionality of the program regardless of paradigm, but may contribute greatly to the structuring and generality of the program, making it much easier to write, modify, and extend.[10] The extent to which different paradigms utilize subroutines (and their consequent memory requirements) influences the overall performance of the complete algorithm, although as Guy Steele pointed out in a 1977 paper, a well-designed programming language implementation can have very low overheads for procedural abstraction (but laments, in most implementations, that they seldom achieve this in practice - being "rather thoughtless or careless in this regard"). In the same paper, Steele also makes a considered case for automata-based programming (utilizing procedure calls with tail recursion) and concludes that "we should have a healthy respect for procedure calls" (because they are powerful) but suggested "use them sparingly"[10]
In terms of the frequency of subroutine calls:
- for procedural programming, the granularity of the code is largely determined by the number of discrete procedures or modules.
- for functional programming, frequent calls to library subroutines are commonplace (but may be frequently inlined by the optimizing compiler)
- for object-oriented programming, the number of method calls invoked is also partly determined by the granularity of the data structures and may therefore include many read-only accesses to low level objects that are encapsulated (and therefore accessible in no other, more direct, way). Since increased granularity is a prerequisite for greater code reuse, the tendency is towards fine-grained data structures, and a corresponding increase in the number of discrete objects (and their methods) and, consequently, subroutine calls. The creation of god objects is actively discouraged. Constructors also add to the count as they are also subroutine calls (unless they are inlined). Performance problems caused by excessive granularity may not become apparent until scalability becomes an issue.
- for other paradigms, where a mixture of the above paradigms may be employed, subroutine usage is less predictable.
Allocation of dynamic memory for message and object storage
Uniquely, the object-oriented paradigm involves dynamic allocation of memory from heap storage for both object creation and message passing. A 1994 benchmark - "Memory Allocation Costs in Large C and C++ Programs" conducted by Digital Equipment Corporation on a variety of software, using an instruction-level profiling tool, measured how many instructions were required per dynamic storage allocation. The results showed that the lowest absolute number of instructions executed averaged around 50 but others reached as high as 611.[11] See also "Heap:Pleasures and pains" by Murali R. Krishnan[12] that states "Heap implementations tend to stay general for all platforms, and hence have heavy overhead". The 1996 IBM paper "Scalability of Dynamic Storage Allocation Algorithms" by Arun Iyengar of IBM [13] demonstrates various dynamic storage algorithms and their respective instruction counts. Even the recommended MFLF I algorithm (H.S. Stone, RC 9674) shows instruction counts in a range between 200 and 400. The above pseudocode example does not include a realistic estimate of this memory allocation pathlength or the memory prefix overheads involved and the subsequent associated garbage collection overheads. Suggesting strongly that heap allocation is a non-trivial task, one open source microallocator, by game developer John W. Ratcliff, consists of nearly 1,000 lines of code.[14]
Dynamically dispatched message calls v. direct procedure call overheads
In their Abstract "Optimization of Object-Oriented Programs Using Static Class Hierarchy Analysis",[15] Jeffrey Dean, David Grove, and Craig Chambers of the Department of Computer Science and Engineering, at the University of Washington, claim that "Heavy use of inheritance and dynamically-bound messages is likely to make code more extensible and reusable, but it also imposes a significant performance overhead, compared to an equivalent but non-extensible program written in a non-object-oriented manner. In some domains, such as structured graphics packages, the performance cost of the extra flexibility provided by using a heavily object-oriented style is acceptable. However, in other domains, such as basic data structure libraries, numerical computing packages, rendering libraries, and trace-driven simulation frameworks, the cost of message passing can be too great, forcing the programmer to avoid object-oriented programming in the “hot spots” of their application."
Serialization of objects
Serialization imposes quite considerable overheads when passing objects from one system to another, especially when the transfer is in human-readable formats such as XML and JSON. This contrasts with compact binary formats for non object-oriented data. Both encoding and decoding of the objects data value and its attributes are involved in the serialization process (that also includes awareness of complex issues such as inheritance, encapsulation and data hiding).
Parallel computing
Carnegie-Mellon University Professor Robert Harper in March 2011 wrote: "This semester Dan Licata and I are co-teaching a new course on functional programming for first-year prospective CS majors... Object-oriented programming is eliminated entirely from the introductory curriculum, because it is both anti-modular and anti-parallel by its very nature, and hence unsuitable for a modern CS curriculum. A proposed new course on object-oriented design methodology will be offered at the sophomore level for those students who wish to study this topic."[16]
See also
- Comparison of programming languages
- Comparison of programming languages (basic instructions)
- Granularity
- Message passing
- Subroutine
References
- ↑ Shelly, Asaf (2008-08-22). "Flaws of Object-oriented Modeling". Intel Software Network. Retrieved 2010-07-04.
- ↑ Yegge, Steve (2006-03-30). "Execution in the Kingdom of Nouns". steve-yegge.blogspot.com. Retrieved 2010-07-03.
- ↑
- ↑ "The Jargon File v4.4.7: "syntactic sugar"".
- ↑ Gray, Jan (June 2003). "Writing Faster Managed Code: Know What Things Cost". MSDN. Microsoft.
- ↑ "The True Cost of Calls". wordpress.com. 2008-12-30.
- ↑ http://en.wikibooks.org/wiki/X86_Disassembly/Functions_and_Stack_Frames
- ↑ Roberts, Eric S. (2008). "Art and Science of Java; Chapter 7: Objects and Memory". Stanford University.
- ↑ Roberts, Eric S. (2008). Art and Science of Java. Addison-Wesley. ISBN 978-0-321-48612-7.
- ↑ 10.0 10.1 Guy Lewis Steele, Jr. "Debunking the 'Expensive Procedure Call' Myth, or, Procedure Call Implementations Considered Harmful, or, Lambda: The Ultimate GOTO". MIT AI Lab. AI Lab Memo AIM-443. October 1977.
- ↑ Detlefs, David; Dosser, Al; Zorn, Benjamin (June 1994). "Memory Allocation Costs in Large C and C++ Programs; Page 532". SOFTWARE—PRACTICE AND EXPERIENCE 24 (6): 527–542. CiteSeerX: 10
.1 ..1 .30 .3073 - ↑ Krishnan, Murali R. (February 1999). "Heap: Pleasures and pains". microsoft.com.
- ↑ "Scalability of Dynamic Storage Allocation Algorithms". CiteSeerX: 10
.1 ..1 .3 .3759 - ↑ "MicroAllocator.h". Google Code. Google. Retrieved 2012-01-29.
- ↑ Dean, Jeffrey; Grove, David; Chambers, Craig. "Optimization of Object-Oriented Programs Using Static Class Hierarchy Analysis". University of Washington. doi:10.1007/3-540-49538-X_5. CiteSeerX: 10
.1 ..1 .117 .2420 - ↑ Teaching FP to Freshmen, from Harper's blog about teaching introductory computer science.
Further reading
- "A Memory Allocator" by Doug Lea
- "Dynamic Memory Allocation and Linked Data Structures" by (Scottish Qualifications Authority)
- "Inside A Storage Allocator" by Dr. Newcomer Ph.D
External links
- Comparing Programming Paradigms by Dr Rachel Harrison and Mr Lins Samaraweera
- Comparing Programming Paradigms: an Evaluation of Functional and Object-Oriented Programs by Harrison, R., Samaraweera, L. G., Dobie, M. R. and Lewis, P. H. (1996) pp. 247–254. ISSN 0268-6961
- "The principal programming paradigms" By Peter Van Roy
- "Concepts, Techniques, and Models of Computer Programming" (2004) by Peter Van Roy & Seif Haridi, ISBN 0-262-22069-5
- The True Cost of Calls- from "Harder, Better, Faster, Stronger" blog by computer scientist Steven Pigeon