Classifier chains
Classifier chains is a machine learning method for problem transformation in multi-label classification. It combines computational efficiency of Binary Relevance method and possibility to use dependencies between labels for classification.[1]
Problem transformation
Problem transformation methods transform a multi-label classification problem in one or more single-label classification problems.[2] In such a way existing single-label classification algorithms such as SVM and Naive Bayes can be used without modification.
Several problem transformation methods exist. One of them is Binary Relevance method (BR). Given a set of labels 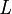 and a data set with instances of the form
and a data set with instances of the form 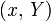 where
where 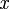 is a feature vector and
is a feature vector and 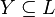 is a set of labels assigned to the instance. BR transforms the data set into
is a set of labels assigned to the instance. BR transforms the data set into 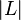 data sets and learns binary classifiers
data sets and learns binary classifiers  for each label
for each label 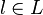 . During this process the information about dependencies between labels is not preserved. This can lead to a situation where a set of labels is assigned to an instance although these labels never co-occur together in the data set. Thus, information about label co-occurrence can help to assign correct label combinations. Loss of this information can in some cases lead to decrease of the classification performance.[3]
. During this process the information about dependencies between labels is not preserved. This can lead to a situation where a set of labels is assigned to an instance although these labels never co-occur together in the data set. Thus, information about label co-occurrence can help to assign correct label combinations. Loss of this information can in some cases lead to decrease of the classification performance.[3]
Other approach, which takes into account label correlations is Label Powerset method (LP). Each different combination of labels in a data set is considered to be a single label. After transformation a single-label classifier 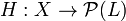 is trained where
is trained where 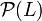 is the power set of all labels in . The main drawback of this approach is that the number of label combinations grows exponentionally with the number of labels. For example, a multi-label data set with 10 labels can have up to
is the power set of all labels in . The main drawback of this approach is that the number of label combinations grows exponentionally with the number of labels. For example, a multi-label data set with 10 labels can have up to 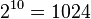 label combinations. This increases the run-time of classification.
label combinations. This increases the run-time of classification.
Classifier Chains method is based on the BR method and it is efficient even on a big number of labels. Furthermore, it considers dependencies between labels.
Method description
For a given a set of labels Classifier Chain model (CC) learns classifiers as in Binary Relevance method. All classifiers are linked in a chain through feature space.
Given a data set where 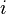 -th instance has the form
-th instance has the form 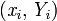 where
where 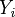 is a subset of labels,
is a subset of labels, 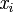 is a set of features. The data set is transformed in data sets where instances of the
is a set of features. The data set is transformed in data sets where instances of the 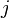 -th data set has the form
-th data set has the form 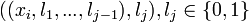 . If the -th label was assigned to the instance then
. If the -th label was assigned to the instance then 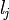 is
is 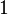 , otherwise it is
, otherwise it is 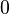 . Thus, classifiers build a chain where each of them learns binary classification of a single label. The features given to each classifier are extended with binary values that indicate which of previous labels were assigned to the instance.
. Thus, classifiers build a chain where each of them learns binary classification of a single label. The features given to each classifier are extended with binary values that indicate which of previous labels were assigned to the instance.
By classifying new instances the labels are again predicted by building a chain of classifiers. The classification begins with first classifier 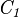 and processes to the last one
and processes to the last one 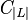 by passing label information between classifiers through the feature space. Hence, the inter-label dependency is preserved. However, the result can vary for different order of chains. For example, if a label often co-occur with some other label only instances of one of the labels, which comes later in the label order, will have information about other one in its feature vector. In order to solve this problem and increase accuracy it is possible to use ensemble of classifiers.[4]
by passing label information between classifiers through the feature space. Hence, the inter-label dependency is preserved. However, the result can vary for different order of chains. For example, if a label often co-occur with some other label only instances of one of the labels, which comes later in the label order, will have information about other one in its feature vector. In order to solve this problem and increase accuracy it is possible to use ensemble of classifiers.[4]
In Ensemble of Classifier Chains (ECC) several CC classifiers can be trained with random order of chains (i.e. random order of labels) on a random subset of data set. Labels of a new instance are predicted by each classifier separately. After that, the total number of predictions or "votes" is counted for each label. The label is accepted if it was predicted by a percentage of classifiers that is bigger than some threshold value.
References
- ↑ Read, Jesse; Bernhard Pfahringer; Geoff Holmes; Eibe Frank (2009). "Classifier Chains for Multi-label Classification". Proc 13th European Conference on Principles and Practice of Knowledge Discovery in Databases and 20th European Conference on Machine Learning 2009.
- ↑ Tsoumakas, Grigorios; Ioannis Katakis (2007). "Multi-label classification: An overview". Int J Data Warehousing and Mining 2007: 1–13.
- ↑ Dembczynski, Krzysztof; Willem Waegeman; Weiwei Cheng; Eyke Hüllermeier (2010). "On label dependence in multi-label classification". Workshop Proceedings of Learning from Multi-Label Data 2010: 5–12.
- ↑ Rokach, Lior (2010). "Ensemble-based classifiers". Artif. Intell. Rev. (Norwell, MA, USA: ACM) 33: 1–39.
External links
- Better Classifier Chains for Multi-label Classification Presentation on Classifier Chains by Jesse Read and Fernando Pérez Cruz
- MEKA Open-Source Implementation of methods for multi-label classification including Classifier Chains
- Mulan Open Source Java Library for multi-label learning, includes an implementation of Classifier Chains