Choice model simulation
Although the concept choice models is widely understood and practiced these days, it is often difficult to acquire hands-on knowledge in simulating choice models. While many stat packages provide useful tools to simulate, researchers attempting to test and simulate new choice models with data often encounter problems from as simple as scaling parameter to misspecification. This article goes beyond simply defining discrete choice models. Rather, it aims at providing a comprehensive overview of how to simulate such models in computer.
Defining choice set
When a researcher has some consumer choice data in his/her hand and tries to construct a choice model and simulate it against the data, he/she needs to first define a choice set. A Choice Set in discrete choice models is defined to be finite, exhaustive, and mutually exclusive. For instance, consider households' choice of how many laptops to own. The researcher can define the choice set depending on the nature of the data and the interpretation they wish to draw, as long as it satisfies three properties mentioned above. Some examples of choice sets that meet the categories are the following:
- 0 , 1, More than 1 laptop
- 0 , 1 , 2 , More than 2 laptops
- Less than 2 , 2 , 3 , 4 , More than 4 laptops
Defining consumer utility
Suppose a student is trying to decide which pub he/she should go for a beer after his/her last final exam. Suppose there are two pubs in the town of the college: an Irish pub and an American pub. The researcher wishes to predict which pub he/she will choose based on the price (P) of beer and the distance (D) to each pub, assuming they are known to the researcher. Then, the consumer utilities for choosing the Irish pub and the American pub can be defined:
-
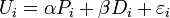 (1)
(1)
-
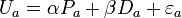 (2)
(2)
where  captures unobserved variables that affect consumer utilities.
captures unobserved variables that affect consumer utilities.
Defining choice probabilities
Once the consumer utilities have been specified, the researcher can derive choice probabilities. Namely, the probability of the student choosing the Irish pub over the American pub is
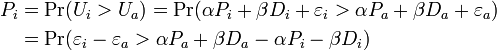
Denoting the observed portion of the utility function as V,
-
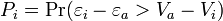 (3)
(3)
In the end, discrete choice modeling comes down to specifying the distribution of (or 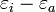 ) and solving the integral over the range of to calculate
) and solving the integral over the range of to calculate 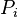 . Extending this to more general situations with
. Extending this to more general situations with
- N consumers (n = 1, 2, …, N),
- J choices of consumption (j = 1, 2, … , J),
The choice probability of consumer n choosing j can be written as
-
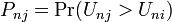 (4)
(4)
for all i other than j
Identification
1. What's irrelevant
From equation (4), it's obvious that 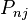 does not change as long as the inequality in the probability argument on the right side stays the same. In other words, adding or multiplying by a constant to all
does not change as long as the inequality in the probability argument on the right side stays the same. In other words, adding or multiplying by a constant to all 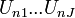 does not change the choice probably, thus no change in interpretation.
does not change the choice probably, thus no change in interpretation.
2. Alternative-specific constants
Unlike adding a constant to all the utilities, adding alternative-specific constants does alter the choice probabilities. Suppose alternative-specific constants Ci and Ca are added to (1) and (2):
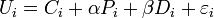
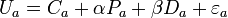
Then, depending on the value of the estimated alternative-specific constants, the choice probability may change. Also, if we write the choice probability in the format of (3),
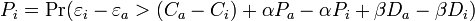
only the difference between 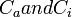 affects the choice probability (i.e. our estimation can only identify the difference). So it's convenient to normalize all the alternative-specific constants to one of the alternatives. If we normalize to
affects the choice probability (i.e. our estimation can only identify the difference). So it's convenient to normalize all the alternative-specific constants to one of the alternatives. If we normalize to 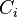 , then we estimate the following model:
, then we estimate the following model:
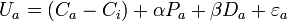
When there are more than 2 choices in the choice set, we can pick any choice i and normalize the alternative-specific constants to that choice by subtracting from all other alternative-specific constants.
3. Sociodemographic variables
In deciding between the Irish pub and the American pub, if the researcher has access to additional sociodemographic variables such as income, they can enter the consumer utility equation in various ways. Denote the student's income as Y. If the researcher believes that the income affects the utility linearly, then
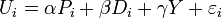
If the researcher believes that the sociodemographic variable interacts with other variable such as price, then the utility can be written as
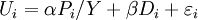
General models
As mentioned earlier, calculation and justification of choice probabilities rely on the properties of the error (i.e. the unobservables) distribution function the researcher specifies. Here is the quick overview of frequently used models that each differs in specification
1. Logit:
- Assumes unobserved factors have the same variance with zero correlation across alternatives.
- iid extreme value unobserved factors
- The cumulative distribution of difference in extreme values is Logistics function
- Logistics function has a closed form solution => No simulation necessary.
2. GEV (Generalized extreme value distribution)
- Allows correlation in unobserved factors across alternatives.
- iid extreme value unobserved factors
- The cumulative distribution of difference in extreme values is Logistics function
- Logistics function has a closed form solution => No simulation necessary.
3. Probit
- Unobserved factors have a jointly normal distribution.
- No closed form for the cumulative distribution of normal distribution. Simulation necessary.
4. Mixed logit
- Allows any distribution in unobserved factors
- No closed form for the cumulative distribution of normal distribution. Simulation necessary.
References
- A Nevo (2000). "Practitioners Guide to Estimation of Random Coefficients Logit Models of Demand," Journal of Economics & Management Strategy, 9(4), 513–548
- Kenneth E. Train, " Discrete Choice Methods with Simulation", Massachusetts: Cambridge University Press, 2003.