Canberra distance
The Canberra distance is a numerical measure of the distance between pairs of points in a vector space, introduced in 1966[1] and refined in 1967[2] by G. N. Lance and W. T. Williams. It is a weighted version of L₁ (Manhattan) distance.[3] The Canberra distance has been used as a metric for comparing ranked lists[3] and for intrusion detection in computer security.[4]
Definition
The Canberra distance d between vectors p and q in an n-dimensional real vector space is given as follows:
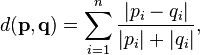
where
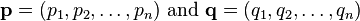
are vectors.
See also
- Normed vector space
- Metric
- Manhattan distance
Notes
- ↑ Lance, G. N.; Williams, W. T. (1966). "Computer programs for hierarchical polythetic classification ("similarity analysis").". Computer Journal 9 (1): 60–64. doi:10.1093/comjnl/9.1.60.
- ↑ Lance, G. N.; Williams, W. T. (1967). "Mixed-data classificatory programs I.) Agglomerative Systems". Australian Computer Journal: 15–20.
- ↑ 3.0 3.1 Jurman G, Riccadonna S, Visintainer R, Furlanello C: Canberra Distance on Ranked Lists. In Proceedings, Advances in Ranking – NIPS 09 Workshop Edited by Agrawal S, Burges C, Crammer K. 2009, 22–27.
- ↑ Syed Masum Emran and Nong Ye (2002). Robustness of chi-square and Canberra distance metrics for computer intrusion detection. Quality and Reliability Engineering International 18:19–28.
References
- Schulz, Jan. "Canberra distance". Code 10. Retrieved 18 October 2011.