Canadian traveller problem
In computer science and graph theory, the Canadian Traveller Problem (CTP) is a generalization of the shortest path problem to graphs that are partially observable. In other words, the graph is revealed while it is being explored, and explorative edges are charged even if they do not contribute to the final path.
This optimization problem was introduced by Christos Papadimitriou and Mihalis Yannakakis in 1989 and a number of variants of the problem have been studied since. The name supposedly originates from conversations of the authors who learned of the difficulty Canadian drivers had with snowfall randomly blocking roads. The stochastic version, where each edge is associated with a probability of independently being in the graph, has been given considerable attention in operations research under the name "the Stochastic Shortest Path Problem with Recourse" (SSPPR).
Problem description
For a given instance, there are a number of possibilities, or realizations, of how the hidden graph may look. Given an instance, a description of how to follow the instance in the best way is called a policy. The CTP task is to compute the expected cost of the optimal policies. To compute an actual description of an optimal policy may be a harder problem.
Given an instance and policy for the instance, every realization produces its own (deterministic) walk in the graph. Note that the walk is not necessarily a path since the best strategy may be to, e.g., visit every vertex of a cycle and return to the start. This differs from the shortest path problem (with strictly positive weights), where repetitions in a walk implies that a better solution exists.
Variants
There are primarily five parameters distinguishing the number of variants of the Canadian Traveller Problem. The first parameter is how to value the walk produced by a policy for a given instance and realization. In the Stochastic Shortest Path Problem with Recourse, the goal is simply to minimize the cost of the walk (defined as the sum over all edges of the cost of the edge times the number of times that edge was taken). For the Canadian Traveller Problem, the task is to minimize the competitive ratio of the walk; i.e., to minimize the number of times longer the produced walk is to the shortest path in the realization.
The second parameter is how to evaluate a policy with respect to different realizations consistent with the instance under consideration. In the Canadian Traveller Problem, one wishes to study the worst case and in SSPPR, the average case. For average case analysis, one must furthermore specify an a priori distribution over the realizations.
The third parameter is restricted to the stochastic versions and is about what assumptions we can make about the distribution of the realizations and how the distribution is represented in the input. In the Stochastic Canadian Traveller Problem and in the Edge-independent Stochastic Shortest Path Problem (i-SSPPR), each uncertain edge (or cost) has an associated probability of being in the realization and the event that an edge is in the graph is independent of which other edges are in the realization. Even though this is a considerable simplification, the problem is still #P-hard. Another variant is to make no assumption on the distribution but require that each realization with non-zero probability be explicitly stated (such as “Probability 0.1 of edge set { {3,4},{1,2} }, probability 0.2 of...”). This is called the Distribution Stochastic Shortest Path Problem (d-SSPPR or R-SSPPR) and is NP-complete. The first variant is harder than the second because the former can represent in logarithmic space some distributions that the latter represents in linear space.
The fourth and final parameter is how the graph changes over time. In CTP and SSPPR, the realization is fixed but not known. In the Stochastic Shortest Path Problem with Recourse and Resets or the Expected Shortest Path problem, a new realization is chosen from the distribution after each step taken by the policy. This problem can be solved in polynomial time by reducing it to a Markov decision process with polynomial horizon. The Markov generalization, where the realization of the graph may influence the next realization, is known to be much harder.
An additional parameter is how new knowledge is being discovered on the realization. In traditional variants of CTP, the agent uncovers the exact weight (or status) of an edge upon reaching an adjacent vertex. A new variant was recently suggested where an agent also has the ability to perform remote sensing from any location on the realization. In this variant, the task is to minimize the travel cost plus the cost of sensing operations.
Formal definition
We define the variant studied in the paper from 1989. That is, the goal is to minimize the competitive ratio in the worst case. It is necessary that we begin by introducing certain terms.
Consider a given graph and the family of undirected graphs that can be constructed by adding one or more edges from a given set. Formally, let 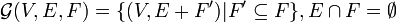 where we think of E as the edges that must be in the graph and of F as the edges that may be in the graph. We say that
where we think of E as the edges that must be in the graph and of F as the edges that may be in the graph. We say that 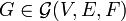 is a realization of the graph family. Furthermore, let W be an associated cost matrix where
is a realization of the graph family. Furthermore, let W be an associated cost matrix where 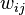 is the cost of going from vertex i to vertex j, assuming that this edge is in the realization.
is the cost of going from vertex i to vertex j, assuming that this edge is in the realization.
For any vertex v in V, we call 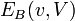 its incident edges with respect to the edge set B on V. Furthermore, for a realization , let
its incident edges with respect to the edge set B on V. Furthermore, for a realization , let 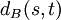 be the cost of the shortest path in the graph from s to t. This is called the off-line problem because an algorithm for such a problem would have complete information of the graph.
be the cost of the shortest path in the graph from s to t. This is called the off-line problem because an algorithm for such a problem would have complete information of the graph.
We say that a strategy 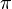 to navigate such a graph is a mapping from
to navigate such a graph is a mapping from 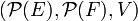 to
to 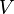 , where
, where 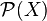 denotes the powerset of X. We define the cost
denotes the powerset of X. We define the cost 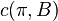 of a strategy with respect to a particular realization
of a strategy with respect to a particular realization 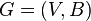 as follows.
as follows.
- Let
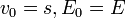 and
and 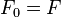 .
. - For
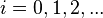 , define
, define
-
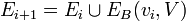 ,
, -
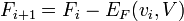 , and
, and -
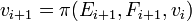 .
.
-
- If there exists a T such that
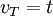 , then
, then 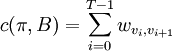 ; otherwise let
; otherwise let 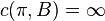 .
.
In other words, we evaluate the policy based on the edges we currently know are in the graph (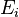 ) and the edges we know might be in the graph (
) and the edges we know might be in the graph (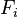 ). When we take a step in the graph, the edges incident to our new location become known to us. Those edges that are in the graph are added to , and regardless of whether the edges are in the graph or not, they are removed from the set of unknown edges, . If the goal is never reached, we say that we have an infinite cost. If the goal is reached, we define the cost of the walk as the sum of the costs of all of the edges traversed, with cardinality.
). When we take a step in the graph, the edges incident to our new location become known to us. Those edges that are in the graph are added to , and regardless of whether the edges are in the graph or not, they are removed from the set of unknown edges, . If the goal is never reached, we say that we have an infinite cost. If the goal is reached, we define the cost of the walk as the sum of the costs of all of the edges traversed, with cardinality.
Finally, we define the Canadian traveller problem.
- Given a CTP instance
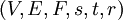 , decide whether there exists a policy such that for every realization
, decide whether there exists a policy such that for every realization 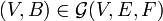 , the cost of the policy is no more than r times the off-line optimal, .
, the cost of the policy is no more than r times the off-line optimal, .
Papadimitriou and Yannakakis noted that this defines a two-player game, where the players compete over the cost of their respective paths and the edge set is chosen by the second player (nature).
Complexity
The original paper analysed the complexity of the problem and reported it to be PSPACE-complete. It was also shown that finding an optimal path in the case where each edge has an associated probability of being in the graph (i-SSPPR) is a PSPACE-easy but #P-hard problem.[1] It is an open problem to bridge this gap.
The directed version of the stochastic problem is known in operations research as the Stochastic Shortest Path Problem with Recourse.
Applications
The problem is said to have applications in operations research, transportation planning, artificial intelligence, machine learning, communication networks, and routing. A variant of the problem has been studied for robot navigation with probabilistic landmark recognition.[2]
Open problems
Despite the age of the problem and its many potential applications, many natural questions still remain open. Is there a constant-factor approximation or is the problem APX-hard? Is i-SSPPR #P-complete? An even more fundamental question has been left unanswered: is there a polynomial-size description of an optimal policy, setting aside for a moment the time necessary to compute the description? [3]
See also
- Expected Shortest Path problem
- Shortest path problem
- Stochastic Shortest Path Problem with Recourse
- Hitting time
- Graph traversal
Notes
- ↑ Papadimitriou and Yannakakis, 1989, p. 148
- ↑ Amy J. Briggs; "Carrick Detweiler, Daniel Scharstein (2004). "Expected shortest paths for landmark-based robot navigation". "International Journal of Robotics Research" 23 (7–8): 717–718. doi:10.1177/0278364904045467.
- ↑ Karger and Nikolova, 2008, p. 1
References
- C.H. Papadimitriou; M. Yannakakis (1989). "Shortest paths without a map". Lecture notes in computer science. Proc. 16th ICALP 372. Springer-Verlag. pp. 610–620.
- David Karger; Evdokia Nikolova (2008). "Exact Algorithms for the Canadian Traveller Problem on Paths and Trees".
- Zahy Bnaya; Ariel Felner; Solomon Eyal Shimony (2009). "Canadian Traveller Problem with remote sensing".