Caltech 101
Caltech 101 is a data set of digital images created in September 2003 and compiled by Fei-Fei Li, Marco Andreetto, Marc 'Aurelio Ranzato and Pietro Perona at the California Institute of Technology. It is intended to facilitate Computer Vision research and techniques and is most applicable to techniques involving image recognition classification and categorization. Caltech 101 contains a total of 9,146 images, split between 101 distinct object categories (faces, watches, ants, pianos, etc.) and a background category. Provided with the images are a set of annotations describing the outlines of each image, along with a Matlab script for viewing.
Purpose
Most Computer Vision and Machine Learning algorithms function by training on example inputs. They require a large and varied set of training data to work effectively. For example, the real-time face detection method used by Paul Viola and Michael J. Jones was trained on 4,916 hand-labeled faces.[1]
Cropping, re-sizing and hand-marking points of interest is tedious and time-consuming.
Historically, most data sets used in computer vision research have been tailored to the specific needs of the project being worked on.A large problem in comparing computer vision techniques is the fact that most groups use their own data sets. Each set may have different properties that make reported results from different methods harder to compare directly. For example, differences in image size, image quality, relative location of objects within the images and level of occlusion and clutter present can lead to varying results.[2]
The Caltech 101 data set aims at alleviating many of these common problems.
- The images are cropped and re-sized.
- Many categories are represented, which suits both single and multiple class recognition algorithms.
- Detailed object outlines are marked.
- Available for general use, Caltech 101 acts as a common standard by which to compare different algorithms without bias due to different data sets.
However, a recent study [3] demonstrates that tests based on uncontrolled natural images (like the Caltech 101 data set) can be seriously misleading, potentially guiding progress in the wrong direction.
Data set
Images
The Caltech 101 data set consists of a total of 9,146 images, split between 101 different object categories, as well as an additional background/clutter category.
Each object category contains between 40 and 800 images. Common and popular categories such as faces tend to have a larger number of images than others.
Each image is about 300x200 pixels. Images of oriented objects such as airplanes and motorcycles were mirrored to be left to right aligned and vertically oriented structures such as buildings were rotated to be off axis.
Annotations
A set of annotations is provided for each image. Each set of annotations contains two pieces of information: the general bounding box in which the object is located and a detailed human-specified outline enclosing the object.
A Matlab script is provided with the annotations. It loads an image and its corresponding annotation file and displays them as a Matlab figure.
Uses
The Caltech 101 data set was used to train and test several computer vision recognition and classification algorithms. The first paper to use Caltech 101 was an incremental Bayesian approach to one shot learning,[4] an attempt to classify an object using only a few examples, by building on prior knowledge of other classes.
The Caltech 101 images, along with the annotations, were used for another one shot learning paper at Caltech. [5]
Other Computer Vision papers that report using the Caltech 101 data set include:
- Shape Matching and Object Recognition using Low Distortion Correspondence. Alexander C. Berg, Tamara L. Berg, Jitendra Malik. CVPR 2005
- The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features. K. Grauman and T. Darrell. International Conference on Computer Vision (ICCV), 2005 [6]
- Combining Generative Models and Fisher Kernels for Object Class Recognition. Holub, AD. Welling, M. Perona, P. International Conference on Computer Vision (ICCV), 2005 [7]
- Object Recognition with Features Inspired by Visual Cortex. T. Serre, L. Wolf and T. Poggio. Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), IEEE Computer Society Press, San Diego, June 2005.[8]
- SVM-KNN: Discriminative Nearest Neighbor Classification for Visual Category Recognition. Hao Zhang, Alex Berg, Michael Maire, Jitendra Malik. CVPR, 2006[9]
- Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce. CVPR, 2006[10]
- Empirical Study of Multi-Scale Filter Banks for Object Categorization. M.J. Mar韓-Jim閚ez, and N. P閞ez de la Blanca. December 2005[11]
- Multiclass Object Recognition with Sparse, Localized Features. Jim Mutch and David G. Lowe., pg. 11-18, CVPR 2006, IEEE Computer Society Press, New York, June 2006[12]
- Using Dependent Regions or Object Categorization in a Generative Framework. G. Wang, Y. Zhang, and L. Fei-Fei. IEEE Comp. Vis. Patt. Recog. 2006[13]
Analysis and comparison
Advantages
Caltech 101 has several advantages over other similar data sets:
- Uniform size and presentation:
- Almost all the images within each category are uniform in image size and in the relative position of interest objects. Caltech 101 users generally do not need to crop or scale images before they can be used.
- Low level of clutter/occlusion:
- Algorithms concerned with recognition usually function by storing features unique to the object. However, most images taken have varying degrees of background clutter, which means algorithms may build incorrectly.
- Detailed annotations
Weaknesses
Weaknesses to the Caltech 101 data set[3][14] may be conscious trade-offs, but others are limitations of the data set. Papers that rely solely on Caltech 101 are frequently rejected.
Weaknesses include:
- The data set is too clean:
- Images are very uniform in presentation, aligned from left to right, and usually not occluded. As a result, the images are not always representative of practical inputs that the algorithm might later expect to see. Under practical conditions, images are more cluttered, occluded and display greater variance in relative position and orientation of interest objects. The uniformity allows concepts to be derived using the average of a category, which is unrealistic.
- Limited number of categories:
- The Caltech 101 data set represents only a small fraction of possible object categories.
- Some categories contain few images:
- Certain categories are not represented as well as others, containing as few as 31 images.
- This means that
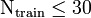 . The number of images used for training must be less than or equal to 30, which is not sufficient for all purposes.
. The number of images used for training must be less than or equal to 30, which is not sufficient for all purposes.
- Aliasing and artifacts due to manipulation:
Other data sets
- Caltech 256 is another image data set created at the in 2007, It is a successor to Caltech 101. It is intended to address some of the weaknesses of Caltech 101. Overall, it is a more difficult data set than Caltech 101, but it suffers from comparable problems. It includes[3]
- 30,607 images, covering a larger number of categories
- Minimum number of images per category raised to 80
- Images are not left-right aligned
- More variation in image presentation
- LabelMe is an open, dynamic data set created at MIT Computer Science and Artificial Intelligence Laboratory (CSAIL). LabelMe takes a different approach to the problem of creating a large image data set, with different trade-offs.
- 106,739 images, 41,724 annotated images, and 203,363 labeled objects.
- Users may add images to the data set by upload, and add labels or annotations to existing images.
- Due to its open nature, LabelMe has many more images covering a much wider scope than Caltech 101. However, since each person decides what images to upload, and how to label and annotate each image, the images are less consistent.
- VOC 2008 is a European effort to collect images for benchmarking visual categorization methods. Compared to Caltech 101/256, a smaller number of categories (about 20) are collected. The number of images in each category, however, is larger.
- Overhead Imagery Research Data Set (OIRDS) is an annotated library of imagery and tools.[15] OIRDS v1.0 is composed of passenger vehicle objects annotated in overhead imagery. Passenger vehicles in the OIRDS include cars, trucks, vans, etc. In addition to the object outlines, the OIRDS includes subjective and objective statistics that quantify the vehicle within the image's context. For example, subjective measures of image clutter, clarity, noise, and vehicle color are included along with more objective statistics such as ground sample distance (GSD), time of day, and day of year.
- ~900 images, containing ~1800 annotated images
- ~30 annotations per object
- ~60 statistical measures per object
- Wide variation in object context
- Limited to passenger vehicles in overhead imagery
- MICC-Flickr 101 is an image data set created at the Media Integration and Communication Center (MICC), University of Florence, in 2012. It is based on Caltech 101 and is collected from Flickr. MICC-Flickr 101[16] corrects the main drawback of Caltech 101, i.e. its low inter-class variability and provides social annotations through user tags. It builds on a standard and widely used data set composed of a manageable number of categories (101) and therefore can be used to compare object categorization performance in a constrained scenario (Caltech 101) and object categorization "in the wild" (MICC-Flickr 101) on the same 101 categories.
See also
References
- ↑ P. Viola and M. J. Jones, Robust Real-Time Object Detection, , IJCV 2004
- ↑ Oertel, C., Colder, B., Colombe, J., High, J., Ingram, M., Sallee, P., Current Challenges in Automating Visual Perception. Proceedings of IEEE Advanced Imagery Pattern Recognition Workshop 2008
- ↑ 3.0 3.1 3.2 Why is Real-World Visual Object Recognition Hard? Pinto N, Cox DD, DiCarlo JJ PLoS Computational Biology Vol. 4, No. 1, e27 doi:10.1371/journal.pcbi.0040027
- ↑ L. Fei-Fei, R. Fergus and P. Perona. Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. IEEE. CVPR 2004, Workshop on Generative-Model Based Vision. 2004
- ↑ L. Fei-Fei, R. Fergus and P. Perona. One-Shot learning of object categories. IEEE Trans. Pattern Analysis and Machine Intelligence, Vol28(4), 594 - 611, 2006.
- ↑ The Pyramid Match Kernel:Discriminative Classification with Sets of Image Features. K. Grauman and T. Darrell. International Conference on Computer Vision (ICCV), 2005
- ↑ Combining Generative Models and Fisher Kernels for Object Class Recognition. Holub, AD. Welling, M. Perona, P. International Conference on Computer Vision (ICCV), 2005
- ↑ Object Recognition with Features Inspired by Visual Cortex. T. Serre, L. Wolf and T. Poggio. Proceedings of 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), IEEE Computer Society Press, San Diego, June 2005
- ↑ SVM-KNN: Discriminative Nearest Neighbor Classification for Visual Category Recognition. Hao Zhang, Alex Berg, Michael Maire, Jitendra Malik. CVPR, 2006
- ↑ Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories. Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce. CVPR, 2006
- ↑ Empirical study of multi-scale filter banks for object categorization, M.J. Mar韓-Jim閚ez, and N. P閞ez de la Blanca. December 2005
- ↑ Multiclass Object Recognition with Sparse, Localized Features, Jim Mutch and David G. Lowe. , pg. 11-18, CVPR 2006, IEEE Computer Society Press, New York, June 2006
- ↑ Using Dependent Regions or Object Categorization in a Generative Framework, G. Wang, Y. Zhang, and L. Fei-Fei. IEEE Comp. Vis. Patt. Recog. 2006
- ↑ Dataset Issues in Object Recognition. J. Ponce, T. L. Berg, M. Everingham, D. A. Forsyth, M. Hebert, S. Lazebnik, M. Marszalek, C. Schmid, B. C. Russell, A. Torralba, C. K. I. Williams, J. Zhang, and A. Zisserman. Toward Category-Level Object Recognition, Springer-Verlag Lecture Notes in Computer Science. J. Ponce, M. Hebert, C. Schmid, and A. Zisserman (eds.), 2006
- ↑ F. Tanner, B. Colder, C. Pullen, D. Heagy, C. Oertel, & P. Sallee, Overhead Imagery Research Data Set (OIRDS) – an annotated data library and tools to aid in the development of computer vision algorithms, June 2009, <http://sourceforge.net/apps/mediawiki/oirds/index.php?title=Documentation> (28 December 2009)
- ↑ L. Ballan, M. Bertini, A. Del Bimbo, A.M. Serain, G. Serra, B.F. Zaccone. Combining Generative and Discriminative Models for Classifying Social Images from 101 Object Categories. Int. Conference on Pattern Recognition (ICPR), 2012.
External links
- http://www.vision.caltech.edu/Image_Datasets/Caltech101/ -Caltech 101 Homepage (Includes download)
- http://www.vision.caltech.edu/Image_Datasets/Caltech256/ -Caltech 256 Homepage (Includes download)
- http://labelme.csail.mit.edu/ -LabelMe Homepage
- http://www2.it.lut.fi/project/visiq/ -Randomized Caltech 101 download page (Includes download)
- http://www.micc.unifi.it/vim/datasets/micc-flickr-101/ -MICC-Flickr101 Homepage (Includes download)