Brown clustering
In natural language processing, Brown clustering[1][2] or IBM clustering[3] is a form of hierarchical clustering of words based on the contexts in which they occur, proposed by Peter F. Brown of IBM in the context of language modeling.[4] The intuition behind the method is that a class-based language model (also called cluster n-gram model[3]), i.e. one where probabilities of words are based on the classes (clusters) of previous words, can overcome the data sparsity problem inherent in language modeling. Jurafsky and Martin give the example of a flight reservation system that needs to estimate the likelihood of the bigram "to Shanghai", without having seen this in a training set. The system can obtain a good estimate if it can cluster "Shanghai" with other city names, then make its estimate based on the likelihood of phrases such as "to London", "to Beijing" and "to Denver".[3]
Brown clustering is an agglomerative, bottom-up form of clustering that groups words (i.e., types) into a binary tree of classes, using a merging criterion based on the log-probability of a text under a class-based language model, i.e. a probability model that takes the clustering into account. This model has the same general form as a hidden Markov model.[1] That is, given cluster membership indicators cᵢ for the tokens wᵢ in a text, the probability of the wᵢ given wᵢ₋₁ is given by[3]
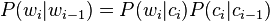
Finding the clustering which maximizes the likelihood of the data is computationally infeasible. The approach proposed by Brown is a greedy heuristic.
The cluster memberships of words resulting from Brown clustering can be used as features in a variety of machine-learned natural language processing tasks.[2]
See also
References
- ↑ 1.0 1.1 Percy Liang (2005). Semi-Supervised Learning for Natural Language (M. Eng.). MIT. pp. 44–52.
- ↑ 2.0 2.1 Joseph Turian; Lev Ratinov; Yoshua Bengio (2010). Word representations: a simple and general method for semi-supervised learning. Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.
- ↑ 3.0 3.1 3.2 3.3 Daniel Jurafsky; James H. Martin (2009). Speech and Language Processing. Pearson Education International. pp. 145–146.
- ↑ Peter F. Brown; Peter V. deSouza; Robert L. Mercer; Vincent J. Della Pietra; Jenifer C. Lai (1992). "Class-based n-gram models of natural language". Computational Linguistics 18 (4).