Basic Linear Algebra Subprograms
The Basic Linear Algebra Subprograms (BLAS) are a specified set of low-level subroutines that perform common linear algebra operations such as copying, vector scaling, vector dot products, linear combinations, and matrix multiplication. They were first published as a Fortran library in 1979[1] and are still used as a building block in higher-level math programming languages and libraries, including LINPACK, LAPACK, MATLAB,[2] GNU Octave, Mathematica,[3] NumPy[4] and R.
BLAS subroutines are a de facto standard API for linear algebra libraries and routines. Several BLAS library implementations have been tuned for specific computer architectures. Highly optimized implementations have been developed by hardware vendors such as Intel and AMD, as well as by other authors, e.g. GotoBLAS and ATLAS (a portable self-optimizing BLAS). The LINPACK and HPL benchmarks rely heavily on DGEMM, a BLAS subroutine, for its performance measurements.
Background
With the advent of numerical programming, sophisticated subroutine libraries became useful. These libraries would contain common mathematical operations such as root finding, matrix inversion, and solving systems of equations. The language of choice was FORTRAN. An early example of such a library was IBM's Scientific Subroutine Package (SSP). These subroutine libraries allowed programmers to concentrate on their specific problems and avoid re-implementing well-known algorithms. The library routines would also be better than average implementations; matrix algorithms, for example, might use full pivoting to get better numerical accuracy. The library routines would also have more efficient routines. For example, a library may include a program to solve a matrix that is upper triangular. The libraries would include single-precision and double-precision versions of some algorithms.
Initially, these subroutines used hard-coded loops. If a subroutine need to perform a matrix multiplication, there would be three nested DO loops. Linear algebra programs have many common low-level ("kernel") operations.[5] Between 1973 and 1977, several of these kernel operations were identified.[6] These kernel operations became defined subroutines that math libraries could call. The kernel calls had advantages over hard-coded loops: the library routine would be more readable, there were fewer chances for bugs, and the kernel implementation could be optimized for speed. A specification for these kernel operations using scalars and vectors, the level-1 Basic Linear Algebra Subroutines (BLAS), was published in 1979.[7] BLAS was used to implement LINPACK.
The BLAS abstraction allows customization for high performance. For example, LINPACK is a general purpose library that can be used on many different machines without modification. LINPACK could use a generic version of BLAS. To gain performance, different machines might use tailored versions of BLAS. As computer architectures became more sophisticated, vector machines appeared. BLAS for a vector machine could use the machine's fast vector operations.
Other machine features became available and could also be exploited. Consequently, BLAS was augmented from 1984 to 1986 with level-2 kernel operations that concerned vector-matrix operations. Memory hierarchy was also recognized as something to exploit. Many computers have cache memory that is much faster than main memory; keeping matrix manipulations localized allows better usage of the cache. In 1987 and 1988, the level 3 BLAS were identified to do matrix-matrix operations. The level 3 BLAS encouraged block-partitioned algorithms. The LAPACK library uses level 3 BLAS.[8]
The original BLAS concerned densely stored vectors and matrices. Further extensions to BLAS, such as to sparse matrices, have been addressed.[9]
Reference implementation
A reference implementation in Fortran provides a platform independent implementation of BLAS but without any attempt at optimizing performance.
ATLAS
Automatically Tuned Linear Algebra Software (ATLAS) attempts to make a BLAS implementation with higher performance. ATLAS defines many BLAS operations in terms of some core routines and then tries to automatically tailor the core routines to have good performance. A search is performed to choose good block sizes. The block sizes may depend on the computer's cache size and architecture. Tests are also made to see if copying arrays and vectors improves performance. For example, it may be advantageous to copy arguments so that they are cache-line aligned so user-supplied routines can use SIMD instructions.
Functionality
BLAS functionality is divided into three levels: 1, 2 and 3.
Level 1
This level contains vector operations on strided arrays: dot products, vector norms, a generalized vector addition of the form
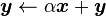
(called "axpy") and several other operations. The original presentation of BLAS described only level-1 operations.[1]
Level 2
This level contains matrix-vector operations including a generalized matrix-vector multiplication (GEMV):
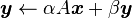
as well as a solver for 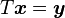 for
for 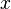 with
with 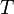 being triangular, among other things. Design of the Level 2 BLAS started in 1984, with results published in 1988.[10] The Level 2 subroutines are especially intended to improve performance of programs using BLAS on vector processors, where Level 1 BLAS are suboptimal "because they hide the matrix-vector nature of the operations from the compiler."[10]
being triangular, among other things. Design of the Level 2 BLAS started in 1984, with results published in 1988.[10] The Level 2 subroutines are especially intended to improve performance of programs using BLAS on vector processors, where Level 1 BLAS are suboptimal "because they hide the matrix-vector nature of the operations from the compiler."[10]
Level 3
This level, formally published in 1990,[11] contains matrix-matrix operations, including a "general matrix multiplication" (GEMM), of the form
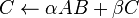
where 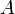 and
and 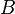 can optionally be transposed inside the routine and all three matrices may be strided. (The ordinary matrix multiplication
can optionally be transposed inside the routine and all three matrices may be strided. (The ordinary matrix multiplication 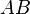 can be performed by setting
can be performed by setting 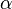 to one and
to one and 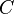 to an all-zeros matrix of the appropriate size.)
to an all-zeros matrix of the appropriate size.)
Also included in Level 3 are routines for solving 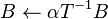 for triangular matrices , among other functionality.
for triangular matrices , among other functionality.
Due to the ubiquity of matrix multiplications in linear algebra, including for the implementation of the rest of Level 3 BLAS,[12] and because faster algorithms exist beyond the obvious repetition of matrix-vector multiplication, GEMM is a prime target of optimization for BLAS implementers. E.g., by decomposing one or both of 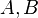 into block matrices, GEMM can be implemented recursively. This is one of the motivations for including the
into block matrices, GEMM can be implemented recursively. This is one of the motivations for including the 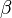 parameter, so the results of previous blocks can be accumulated. Note that this decomposition requires the special case
parameter, so the results of previous blocks can be accumulated. Note that this decomposition requires the special case 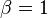 which many implementations optimize for, thereby eliminating one multiplication for each value of C. This decomposition allows for better locality of reference both in space and time of the data used in the product.
This, in turn, takes advantage of the cache on the system.[13] For systems with more than one level of cache,
the blocking can be applied a second time to the order in which the blocks are used in the computation.
Both of these levels of optimization are used in implementations such as ATLAS.
More recently, implementations by Kazushige Goto have shown that blocking only for the L2 cache, combined with careful amortizing of copying to contiguous memory to reduce TLB misses, is superior to ATLAS. A highly tuned implementation based on these ideas is part of the GotoBLAS.
which many implementations optimize for, thereby eliminating one multiplication for each value of C. This decomposition allows for better locality of reference both in space and time of the data used in the product.
This, in turn, takes advantage of the cache on the system.[13] For systems with more than one level of cache,
the blocking can be applied a second time to the order in which the blocks are used in the computation.
Both of these levels of optimization are used in implementations such as ATLAS.
More recently, implementations by Kazushige Goto have shown that blocking only for the L2 cache, combined with careful amortizing of copying to contiguous memory to reduce TLB misses, is superior to ATLAS. A highly tuned implementation based on these ideas is part of the GotoBLAS.
Implementations
- Accelerate
- Apple's framework for Mac OS X and iOS, which includes tuned versions of BLAS and LAPACK.
- ACML
- The AMD Core Math Library, supporting the AMD Athlon and Opteron CPUs under Linux and Windows.
- C++ AMP BLAS
- The C++ AMP BLAS Library is an open source implementation of BLAS for Microsoft's AMP language extension for Visual C++.
- ATLAS
- Automatically Tuned Linear Algebra Software, an open source implementation of BLAS APIs for C and Fortran 77.
- BLIS
- BLAS-like Library Instantiation Software framework for rapid instantiation.
- cuBLAS
- Optimized BLAS for NVIDIA based GPU cards.
- clBLAS
- An OpenCL implemenation of BLAS.
- Eigen BLAS
- A Fortran 77 and C BLAS library implemented on top of the open source Eigen library, supporting x86, x86 64, ARM (NEON), and PowerPC architectures. (Note: as of Eigen 3.0.3, the BLAS interface is not built by default and the documentation refers to it as "a work in progress which is far to be ready for use".)
- ESSL
- IBM's Engineering and Scientific Subroutine Library, supporting the PowerPC architecture under AIX and Linux.
- GotoBLAS
- Kazushige Goto's BSD-licensed implementation of BLAS, tuned in particular for Intel Nehalem/Atom, VIA Nanoprocessor, AMD Opteron.
- HP MLIB
- HP's Math library supporting IA-64, PA-RISC, x86 and Opteron architecture under HPUX and Linux.
- Intel MKL
- The Intel Math Kernel Library, supporting x86 32-bits and 64-bits. Includes optimizations for Intel Pentium, Core and Intel Xeon CPUs and Intel Xeon Phi; support for Linux, Windows and Mac OS X.
- MathKeisan
- NEC's math library, supporting NEC SX architecture under SUPER-UX, and Itanium under Linux
- Netlib BLAS
- The official reference implementation on Netlib, written in Fortran 77.
- Netlib CBLAS
- Reference C interface to the BLAS. It is also possible (and popular) to call the Fortran BLAS from C.
- OpenBLAS
- Optimized BLAS based on Goto BLAS hosted at GitHub, supporting Intel Sandy Bridge and MIPS_architecture Loongson processors.
- PDLIB/SX
- NEC's Public Domain Mathematical Library for the NEC SX-4 system.
- SCSL
- SGI's Scientific Computing Software Library contains BLAS and LAPACK implementations for SGI's Irix workstations.
- Sun Performance Library
- Optimized BLAS and LAPACK for SPARC, Core and AMD64 architectures under Solaris 8, 9, and 10 as well as Linux.
Other libraries offering BLAS-like functionality
- Armadillo
- Armadillo is a C++ linear algebra library aiming towards a good balance between speed and ease of use. It employs template classes, and has optional links to BLAS/ATLAS and LAPACK. It is sponsored by NICTA (in Australia) and is licensed under a free license. .
- clMath
- clMath, formerly AMD Accelerated Parallel Processing Math Libraries (APPML), is an open-source project that contains FFT and 3 Levels BLAS functions written in OpenCL. Designed to run on AMD GPUs supporting OpenCL also work on CPUs to facilitate multicore programming and debugging.
- CUDA SDK
- The NVIDIA CUDA SDK includes BLAS functionality for writing C programs that runs on GeForce 8 Series or newer graphics cards.
- Eigen
- The Eigen template library provides an easy to use highly generic C++ template interface to matrix/vector operations and related algorithms like solving algorithms, decompositions etc. It uses vector capabilities and is optimized for both fixed size and dynamic sized and sparse matrices.
- GSL
- The GNU Scientific Library Contains a multi-platform implementation in C which is distributed under the GNU General Public License.
- HASEM
- is a C++ template library, being able to solve linear equations and to compute eigenvalues. It is licensed under BSD License.
- LAMA
- The Library for Accelerated Math Applications (LAMA) is a C++ template library for writing numerical solvers targeting various hardwares (e.g. GPUs through CUDA or OpenCL) on distributed memory systems, hiding the hardware specific programming from the program developer
- Libflame
- FLAME project implementation of dense linear algebra library
- MAGMA
- Matrix Algebra on GPU and Multicore Architectures (MAGMA) project develops a dense linear algebra library similar to LAPACK but for heterogeneous and hybrid architectures including multicore systems accelerated with GPGPU graphics cards.
- MTL4
- The Matrix Template Library version 4 is a generic C++ template library providing sparse and dense BLAS functionality. MTL4 establishes an intuitive interface (similar to MATLAB) and broad applicability thanks to Generic programming.
- PLASMA
- The Parallel Linear Algebra for Scalable Multi-core Architectures (PLASMA) project is a modern replacement of LAPACK for multi-core architectures. PLASMA is a software framework for development of asynchronous operations and features out of order scheduling with a runtime scheduler called QUARK that may be used for any code that expresses its dependencies with a Directed acyclic graph.
- uBLAS
- A generic C++ template class library providing BLAS functionality. Part of the Boost library. It provides bindings to many hardware-accelerated libraries in a unifying notation. Moreover, uBLAS focuses on correctness of the algorithms using advanced C++ features.
The Sparse BLAS
Sparse extensions to the previously dense BLAS exist such as in ACML
See also
- Numerical linear algebra, the type of problem BLAS solves
- Math Kernel Library, math library optimized for the Intel architecture; includes BLAS, LAPACK
- List of numerical libraries
References
- ↑ 1.0 1.1
- Lawson, C. L.; Hanson, R. J.; Kincaid, D.; Krogh, F. T. (1979). "Basic Linear Algebra Subprograms for FORTRAN usage". ACM Trans. Math. Software 5: 308–323. doi:10.1145/355841.355847. Algorithm 539.
- ↑ Cleve Moler (2000). "MATLAB Incorporates LAPACK". MathWorks. Retrieved 26 October 2013.
- ↑ Douglas Quinney (2003). "So what’s new in Mathematica 5.0?" (PDF). MSOR Connections (The Higher Education Academy) 3 (4).
- ↑ Stéfan van der Walt, S. Chris Colbert and Gaël Varoquaux (2011). "The NumPy array: a structure for efficient numerical computation". Computing in Science and Engineering (IEEE).
- ↑ Even the SSP (which appeared around 1966) had some basic routines such as RADD (add rows), CADD (add columns), SRMA (scale row and add to another row), and RINT (row interchange). These routines apparently were not used as kernel operations to implement other routines such as matrix inversion. See IBM (1970), System/360 Scientific Subroutine Package, Version III, Programmer's Manual (5th ed.), International Business Machines, GH20-0205-4.
- ↑ BLAST Forum 2001, p. 1.
- ↑ Lawson et al. 1979.
- ↑ BLAST Forum 2001, pp. 1–2.
- ↑ BLAST Forum 2001, p. 2.
- ↑ 10.0 10.1 Jack J. Dongarra; Jeremy Du Croz; Sven Hammarling; Richard J. Hanson (1988). "An extended set of FORTRAN Basic Linear Algebra Subprograms". ACM Trans. Math. Soft. 14: 1–17. doi:10.1145/42288.42291.
- ↑ Dongarra, Jack J.; Du Croz, Jeremy; Hammarling, Sven; Duff, Iain S. (1990). "A set of level 3 basic linear algebra subprograms". ACM Transactions on Mathematical Software 16 (1): 1–17. doi:10.1145/77626.79170. ISSN 0098-3500.
- ↑ Goto, Kazushige and Robert van de Geijn (2008). "High-performance implementation of the level-3 BLAS" (PDF). ACM Transactions on Mathematical Software 35 (1).
- ↑ Golub, Gene H.; Van Loan, Charles F. (1996), Matrix Computations (3rd ed.), Johns Hopkins, ISBN 978-0-8018-5414-9
- BLAST Forum (21 August 2001), Basic Linear Algebra Subprograms Technical (BLAST) Forum Standard, Knoxville, TN: University of Tennessee
- Dodson, D. S.; Grimes, R. G. (1982), "Remark on algorithm 539: Basic Linear Algebra Subprograms for Fortran usage", ACM Trans. Math. Software 8: 403–404, doi:10.1145/356012.356020
- Dodson, D. S. (1983), "Corrigendum: Remark on "Algorithm 539: Basic Linear Algebra Subroutines for FORTRAN usage"", ACM Trans. Math. Software 9: 140, doi:10.1145/356022.356032
- J. J. Dongarra, J. Du Croz, S. Hammarling, and R. J. Hanson, Algorithm 656: An extended set of FORTRAN Basic Linear Algebra Subprograms, ACM Trans. Math. Soft., 14 (1988), pp. 18–32.
- J. J. Dongarra, J. Du Croz, I. S. Duff, and S. Hammarling, A set of Level 3 Basic Linear Algebra Subprograms, ACM Trans. Math. Soft., 16 (1990), pp. 1–17.
- J. J. Dongarra, J. Du Croz, I. S. Duff, and S. Hammarling, Algorithm 679: A set of Level 3 Basic Linear Algebra Subprograms, ACM Trans. Math. Soft., 16 (1990), pp. 18–28.
- New BLAS
- L. S. Blackford, J. Demmel, J. Dongarra, I. Duff, S. Hammarling, G. Henry, M. Heroux, L. Kaufman, A. Lumsdaine, A. Petitet, R. Pozo, K. Remington, R. C. Whaley, An Updated Set of Basic Linear Algebra Subprograms (BLAS), ACM Trans. Math. Soft., 28-2 (2002), pp. 135–151.
- J. Dongarra, Basic Linear Algebra Subprograms Technical Forum Standard, International Journal of High Performance Applications and Supercomputing, 16(1) (2002), pp. 1–111, and International Journal of High Performance Applications and Supercomputing, 16(2) (2002), pp. 115–199.
External links
- BLAS homepage on Netlib.org
- BLAS FAQ
- BLAS Quick Reference Guide from LAPACK Users' Guide
- Lawson Oral History One of the original authors of the BLAS discusses its creation in an oral history interview. Charles L. Lawson Oral history interview by Thomas Haigh, 6 and 7 November 2004, San Clemente, California. Society for Industrial and Applied Mathematics, Philadelphia, PA.
- Dongarra Oral History In an oral history interview, Jack Dongarra explores the early relationship of BLAS to LINPACK, the creation of higher level BLAS versions for new architectures, and his later work on the ATLAS system to automatically optimize BLAS for particular machines. Jack Dongarra, Oral history interview by Thomas Haigh, 26 April 2005, University of Tennessee, Knoxville TN. Society for Industrial and Applied Mathematics, Philadelphia, PA
- An Overview of the Sparse Basic Linear Algebra Subprograms: The New Standard from the BLAS Technical Forum
| ||||||||||||||||||