Automatic vectorization
Automatic vectorization, in parallel computing, is a special case of automatic parallelization, where a computer program is converted from a scalar implementation, which processes a single pair of operands at a time, to a vector implementation, which processes one operation on multiple pairs of operands at once. For example, modern conventional computers, including specialized supercomputers, typically have vector operations that simultaneously perform operations such as the following four additions:
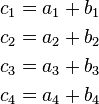
However, in most programming languages one typically writes loops that sequentially perform additions of many numbers. Here is an example of such a loop, written in C:
for (i=0; i<n; i++) c[i] = a[i] + b[i];
A vectorizing compiler transforms such loops into sequences of vector operations. These vector operations perform additions on length-four (in our example) blocks of elements from the arrays a, b and c. Automatic vectorization is a major research topic in computer science.
Background
Early computers generally had one logic unit that sequentially executed one instruction on one operand pair at a time. Computer programs and programming languages were accordingly designed to execute sequentially. Modern computers can do many things at once. Many optimizing compilers feature auto-vectorization, a compiler feature where particular parts of sequential programs are transformed into equivalent parallel ones, to produce code which will well utilize a vector processor. For a compiler to produce such efficient code for a programming language intended for use on a vector-processor would be much simpler, but, as much real-world code is sequential, the optimization is of great utility.
Loop vectorization converts procedural loops that iterate over multiple pairs of data items and assigns a separate processing unit to each pair. Most programs spend most of their execution times within such loops. Vectorizing loops can lead to significant performance gains without programmer intervention, especially on large data sets. Vectorization can sometimes instead slow execution because of pipeline synchronization, data movement timing and other issues.
Intel's MMX, SSE, AVX and Power Architecture's AltiVec and ARM's NEON instruction sets support such vectorized loops.
Many constraints prevent or hinder vectorization. Loop dependence analysis identifies loops that can be vectorized, relying on the data dependence of the instructions inside loops.
Guarantees
Automatic vectorization, like any loop optimization or other compile-time optimization, must exactly preserve program behavior.
Data dependencies
All dependencies must be respected during execution to prevent incorrect results.
In general, loop invariant dependencies and lexically forward dependencies can be easily vectorized, and lexically backward dependencies can be transformed into lexically forward dependencies. However, these transformations must be done safely, in order to ensure that the dependence between all statements remain true to the original.
Cyclic dependencies must be processed independently of the vectorized instructions.
Data precision
Integer precision (bit-size) must be kept during vector instruction execution. The correct vector instruction must be chosen based on the size and behavior of the internal integers. Also, with mixed integer types, extra care must be taken to promote/demote them correctly without losing precision. Special care must be taken with sign extension (because multiple integers are packed inside the same register) and during shift operations, or operations with carry bits that would otherwise be taken into account.
Floating-point precision must be kept as well, unless IEEE-754 compliance is turned off, in which case operations will be faster but the results may vary slightly. Big variations, even ignoring IEEE-754 usually means programmer error. The programmer can also force constants and loop variables to single precision (default is normally double) to execute twice as many operations per instruction.
Theory
To vectorize a program, the compiler's optimizer must first understand the dependencies between statements and re-align them, if necessary. Once the dependencies are mapped, the optimizer must properly arrange the implementing instructions changing appropriate candidates to vector instructions, which operate on multiple data items.
Building the dependency graph
The first step is to build the dependency graph, identifying which statements depend on which other statements. This involves examining each statement and identifying every data item that the statement accesses, mapping array access modifiers to functions and checking every access' dependency to all others in all statements. Alias analysis can be used to certify that the different variables access (or intersects) the same region in memory.
The dependency graph contains all local dependencies with distance not greater than the vector size. So, if the vector register is 128 bits, and the array type is 32 bits, the vector size is 128/32 = 4. All other non-cyclic dependencies should not invalidate vectorization, since there won't be any concurrent access in the same vector instruction.
Suppose the vector size is the same as 4 ints:
for (i = 0; i < 128; i++) { a[i] = a[i-16]; // 16 > 4, safe to ignore a[i] = a[i-1]; // 1 < 4, stays on dependency graph }
Clustering
Using the graph, the optimizer can then cluster the strongly connected components (SCC) and separate vectorizable statements from the rest.
For example, consider a program fragment containing three statement groups inside a loop: (SCC1+SCC2), SCC3 and SCC4, in that order, in which only the second group (SCC3) can be vectorized. The final program will then contain three loops, one for each group, with only the middle one vectorized. The optimizer cannot join the first with the last without violating statement execution order, which would invalidate the necessary guarantees.
Detecting idioms
Some non-obvious dependencies can be further optimized based on specific idioms.
For instance, the following self-data-dependencies can be vectorized because the value of the right-hand values (RHS) are fetched and then stored on the left-hand value, so there is no way the data will change within the assignment.
a[i] = a[i] + a[i+1];
Self-dependence by scalars can be vectorized by variable elimination.
General framework
The general framework for loop vectorization is split into four stages:
- Prelude: Where the loop-independent variables are prepared to be used inside the loop. This normally involves moving them to vector registers with specific patterns that will be used in vector instructions. This is also the place to insert the run-time dependence check. If the check decides vectorization is not possible, branch to Cleanup.
- Loop(s): All vectorized (or not) loops, separated by SCCs clusters in order of appearance in the original code.
- Postlude: Return all loop-independent variables, inductions and reductions.
- Cleanup: Implement plain (non-vectorized) loops for iterations at the end of a loop that are not a multiple of the vector size or for when run-time checks prohibit vector processing.
Run-time vs. compile-time
Some vectorizations cannot be fully checked at compile time. Compile-time optimization requires an explicit array index. Library functions can also defeat optimization if the data they process is supplied by the caller. Even in these cases, run-time optimization can still vectorize loops on-the-fly.
This run-time check is made in the prelude stage and directs the flow to vectorized instructions if possible, otherwise reverting to standard processing, depending on the variables that are being passed on the registers or scalar variables.
The following code can easily be vectorized on compile time, as it doesn't have any dependence on external parameters. Also, the language guarantees that neither will occupy the same region in memory as any other variable, as they are local variables and live only in the execution stack.
int a[128]; int b[128]; // initialize b for (i = 0; i<128; i++) a[i] = b[i] + 5;
On the other hand, the code below has no information on memory positions, because the references are pointers and the memory they point to lives in the heap.
int *a = malloc(128*sizeof(int)); int *b = malloc(128*sizeof(int)); // initialize b for (i = 0; i<128; i++, a++, b++) *a = *b + 5; // ... // ... // ... free(b); free(a);
A quick run-time check on the address of both a and b, plus the loop iteration space (128) is enough to tell if the arrays overlap or not, thus revealing any dependencies.
There exist some tools to dynamically analyze existing applications to assess the inherent latent potential for SIMD parallelism, exploitable through further compiler advances and/or via manual code changes. [1]
Techniques
An example would be a program to multiply two vectors of numeric data. A scalar approach would be something like:
for (i = 0; i < 1024; i++) C[i] = A[i]*B[i];
This could be vectorized to look something like:
for (i = 0; i < 1024; i+=4) C[i:i+3] = A[i:i+3]*B[i:i+3];
Here, C[i:i+3] represents the four array elements from C[i] to C[i+3] and the vector processor can perform four operations for a single vector instruction. Since the four vector operations complete in roughly the same time as one scalar instruction, the vector approach can run up to four times faster than the original code.
There are two distinct compiler approaches: one based on the conventional vectorization technique and the other based on loop unrolling.
Loop-level automatic vectorization
This technique, used for conventional vector machines, tries to find and exploit SIMD parallelism at the loop level. It consists of two major steps as follows.
- Find an innermost loop that can be vectorized
- Transform the loop and generate vector codes
In the first step, the compiler looks for obstacles that can prevent vectorization. A major obstacle for vectorization is true data dependency shorter than the vector length. Other obstacles include function calls and short iteration counts.
Once the loop is determined to be vectorizable, the loop is stripmined by the vector length and each scalar instruction within the loop body is replaced with the corresponding vector instruction. Below, the component transformations for this step are shown using the above example.
- After stripmining
for (i = 0; i < 1024; i+=4) for (ii = 0; ii < 4; ii++) C[i+ii] = A[i+ii]*B[i+ii];
- After loop distribution using temporary arrays
for (i = 0; i < 1024; i+=4) { for (ii = 0; ii < 4; ii++) tA[ii] = A[i+ii]; for (ii = 0; ii < 4; ii++) tB[ii] = B[i+ii]; for (ii = 0; ii < 4; ii++) tC[ii] = tA[ii]*tB[ii]; for (ii = 0; ii < 4; ii++) C[i+ii] = tC[ii]; }
- After replacing with vector codes
for (i = 0; i < 1024; i+=4) { vA = vec_ld( &A[i] ); vB = vec_ld( &B[i] ); vC = vec_mul( vA, vB ); vec_st( vC, &C[i] ); }
Basic block level automatic vectorization
This relatively new technique specifically targets modern SIMD architectures with short vector lengths.[2] Although loops can be unrolled to increase the amount of SIMD parallelism in basic blocks, this technique exploits SIMD parallelism within basic blocks rather than loops. The two major steps are as follows.
- The innermost loop is unrolled by a factor of the vector length to form a large loop body.
- Isomorphic scalar instructions (that perform the same operation) are packed into a vector instruction if dependencies do not prevent doing so.
To show step-by-step transformations for this approach, the same example is used again.
- After loop unrolling (by the vector length, assumed to be 4 in this case)
for (i = 0; i < 1024; i+=4) { sA0 = ld( &A[i+0] ); sB0 = ld( &B[i+0] ); sC0 = sA0 * sB0; st( sC0, &C[i+0] ); ... sA3 = ld( &A[i+3] ); sB3 = ld( &B[i+3] ); sC3 = sA3 * sB3; st( sC3, &C[i+3] ); }
- After packing
for (i = 0; i < 1024; i+=4) { (sA0,sA1,sA2,sA3) = ld( &A[i+0:i+3] ); (sB0,sB1,sB2,sB3) = ld( &B[i+0:i+3] ); (sC0,sC1,sC2,sC3) = (sA0,sA1,sA2,sA3) * (sB0,sB1,sB2,sB3); st( (sC0,sC1,sC2,sC3), &C[i+0:i+3] ); }
- After code generation
for (i = 0; i < 1024; i+=4) { vA = vec_ld( &A[i] ); vB = vec_ld( &B[i] ); vC = vec_mul( vA, vB ); vec_st( vC, &C[i] ); }
Here, sA1, sB1, ... represent scalar variables and vA, vB, and vC represent vector variables.
Most automatically vectorizing commercial compilers use the conventional loop-level approach except the IBM XL Compiler,[3] which uses both.
In the presence of control flow
The presence of if-statements in the loop body requires the execution of instructions in all control paths to merge the multiple values of a variable. One general approach is to go through a sequence of code transformations: predication → vectorization(using one of the above methods) → remove vector predicates → remove scalar predicates.[4] If the following code is used as an example to show these transformations;
for (i = 0; i < 1024; i++) if (A[i] > 0) C[i] = B[i]; else D[i] = D[i-1];
- After predication
for (i = 0; i < 1024; i++) { P = A[i] > 0; NP = !P; C[i] = B[i]; (P) D[i] = D[i-1]; (NP) }
where (P) denotes a predicate guarding the statement.
- After vectorization
for (i = 0; i < 1024; i+=4) { vP = A[i:i+3] > (0,0,0,0); vNP = vec_not(vP); C[i:i+3] = B[i:i+3]; (vP) (NP1,NP2,NP3,NP4) = vNP; D[i+3] = D[i+2]; (NP4) D[i+2] = D[i+1]; (NP3) D[i+1] = D[i]; (NP2) D[i] = D[i-1]; (NP1) }
- After removing vector predicates
for (i = 0; i < 1024; i+=4) { vP = A[i:i+3] > (0,0,0,0); vNP = vec_not(vP); C[i:i+3] = vec_sel(C[i:i+3],B[i:i+3],vP); (NP1,NP2,NP3,NP4) = vNP; D[i+3] = D[i+2]; (NP4) D[i+2] = D[i+1]; (NP3) D[i+1] = D[i]; (NP2) D[i] = D[i-1]; (NP1) }
- After removing scalar predicates
for (i = 0; i < 1024; i+=4) { vP = A[i:i+3] > (0,0,0,0); vNP = vec_not(vP); C[i:i+3] = vec_sel(C[i:i+3],B[i:i+3],vP); (NP1,NP2,NP3,NP4) = vNP; if (NP4) D[i+3] = D[i+2]; if (NP3) D[i+2] = D[i+1]; if (NP2) D[i+1] = D[i]; if (NP1) D[i] = D[i-1]; }
Reducing vectorization overhead in the presence of control flow
Having to execute the instructions in all control paths in vector code has been one of the major factors that slow down the vector code with respect to the scalar baseline. The more complex the control flow becomes and the more instructions are bypassed in the scalar code the larger the vectorization overhead grows. To reduce this vectorization overhead, vector branches can be inserted to bypass vector instructions similar to the way scalar branches bypass scalar instructions.[5] Below, AltiVec predicates are used to show how this can be achieved.
- Scalar baseline (original code)
for (i = 0; i < 1024; i++) { if (A[i] > 0) { C[i] = B[i]; if (B[i] < 0) D[i] = E[i]; } }
- After vectorization in the presence of control flow
for (i = 0; i < 1024; i+=4) { vPA = A[i:i+3] > (0,0,0,0); C[i:i+3] = vec_sel(C[i:i+3],B[i:i+3],vPA); vT = B[i:i+3] < (0,0,0,0); vPB = vec_sel((0,0,0,0), vT, vPA); D[i:i+3] = vec_sel(D[i:i+3],E[i:i+3],vPB); }
- After inserting vector branches
for (i = 0; i < 1024; i+=4) if (vec_any_gt(A[i:i+3],(0,0,0,0))) { vPA = A[i:i+3] > (0,0,0,0); C[i:i+3] = vec_sel(C[i:i+3],B[i:i+3],vPA); vT = B[i:i+3] < (0,0,0,0); vPB = vec_sel((0,0,0,0), vT, vPA); if (vec_any_ne(vPB,(0,0,0,0))) D[i:i+3] = vec_sel(D[i:i+3],E[i:i+3],vPB); }
There are two things to note in the final code with vector branches; First, the predicate defining instruction for vPA is also included within the body of the outer vector branch by using vec_any_gt. Second, the profitability of the inner vector branch for vPB depends on the conditional probability of vPB having false values in all fields given vPA has false values in all fields.
Consider an example where the outer branch in the scalar baseline is always taken, bypassing most instructions in the loop body. The intermediate case above, without vector branches, executes all vector instructions. The final code, with vector branches, executes both the comparison and the branch in vector mode, potentially gaining performance over the scalar baseline.
See also
References
- ↑
- ↑ Larsen, S.; Amarasinghe, S. (2000). "Proceedings of the ACM SIGPLAN conference on Programming language design and implementation". ACM SIGPLAN Notices 35 (5): 145–156. doi:10.1145/358438.349320.
|chapter=ignored (help) - ↑
- ↑ Shin, J.; Hall, M. W.; Chame, J. (2005). "Proceedings of the international symposium on Code generation and optimization". pp. 165–175. doi:10.1109/CGO.2005.33. ISBN 0-7695-2298-X.
|chapter=ignored (help) - ↑ Shin, J. (2007). "Proceedings of the 16th International Conference on Parallel Architecture and Compilation Techniques". pp. 280–291. doi:10.1109/PACT.2007.41.
|chapter=ignored (help)