Additive smoothing
In statistics, additive smoothing, also called Laplace smoothing[1] (not to be confused with Laplacian smoothing), or Lidstone smoothing, is a technique used to smooth categorical data. Given an observation x = (x1, …, xd) from a multinomial distribution with N trials and parameter vector θ = (θ1, …, θd), a "smoothed" version of the data gives the estimator:
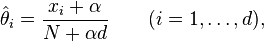
where α > 0 is the smoothing parameter (α = 0 corresponds to no smoothing). Additive smoothing is a type of shrinkage estimator, as the resulting estimate will be between the empirical estimate xi / N, and the uniform probability 1/d. Using Laplace's rule of succession, some authors have argued that α should be 1 (in which case the term add-one smoothing[2][3] is also used), though in practice a smaller value is typically chosen.
From a Bayesian point of view, this corresponds to the expected value of the posterior distribution, using a symmetric Dirichlet distribution with parameter α as a prior.
History
Laplace came up with this smoothing technique when he tried to estimate the chance that the sun will rise tomorrow. His rationale was that even given a large sample of days with the rising sun, we still can not be completely sure that the sun will still rise tomorrow (known as the sunrise problem).[4]
Generalized to the case of known incidence rates
Often you are testing the bias of an unknown trial population against a control population with known parameters (incidence rates) μ = (μ1, …, μd). In this case the uniform probability 1/d should be replaced by the known incidence rate of the control population μi to calculate the smoothed estimator :
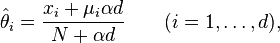
As a consistency check, if the empirical estimator happens to equal the incidence rate, i.e. μi = xi / N, the smoothed estimator is independent of α and also equals the incidence rate.
Applications
Classification
Additive smoothing is commonly a component of naive Bayes classifiers.
Statistical language modelling
In a bag of words model of natural language processing and information retrieval, the data consists of the number of occurrences of each word in a document. Additive smoothing allows the assignment of non-zero probabilities to words which do not occur in the sample.
See also
- Bayesian average
- Pseudocount
References
- ↑ C.D. Manning, P. Raghavan and M. Schütze (2008). Introduction to Information Retrieval. Cambridge University Press, p. 260.
- ↑ Jurafsky, Daniel; Martin, James H. (June 2008). Speech and Language Processing (2nd ed.). Prentice Hall. p. 132. ISBN 978-0-13-187321-6.
- ↑ Russell, Stuart; Norvig, Peter (2010). Artificial Intelligence: A Modern Approach (2nd ed.). Pearson Education, Inc. p. 863.
- ↑ Lecture 5 | Machine Learning (Stanford) at 1h10m into the lecture
External links
- SF Chen, J Goodman (1996). "An empirical study of smoothing techniques for language modeling". Proceedings of the 34th annual meeting on Association for Computational Linguistics.