Weighted arithmetic mean
The weighted mean is similar to an arithmetic mean (the most common type of average), where instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics.
If all the weights are equal, then the weighted mean is the same as the arithmetic mean. While weighted means generally behave in a similar fashion to arithmetic means, they do have a few counterintuitive properties, as captured for instance in Simpson's paradox.
Examples
Basic example
Given two school classes, one with 20 students, and one with 30 students, the grades in each class on a test were:
- Morning class = 62, 67, 71, 74, 76, 77, 78, 79, 79, 80, 80, 81, 81, 82, 83, 84, 86, 89, 93, 98
- Afternoon class = 81, 82, 83, 84, 85, 86, 87, 87, 88, 88, 89, 89, 89, 90, 90, 90, 90, 91, 91, 91, 92, 92, 93, 93, 94, 95, 96, 97, 98, 99
The straight average for the morning class is 80 and the straight average of the afternoon class is 90. The straight average of 80 and 90 is 85, the mean of the two class means. However, this does not account for the difference in number of students in each class (20 versus 30); hence the value of 85 does not reflect the average student grade (independent of class). The average student grade can be obtained by averaging all the grades, without regard to classes (add all the grades up and divide by the total number of students):

Or, this can be accomplished by weighting the class means by the number of students in each class (using a weighted mean of the class means):

Thus, the weighted mean makes it possible to find the average student grade in the case where only the class means and the number of students in each class are available.
Convex combination example
Since only the relative weights are relevant, any weighted mean can be expressed using coefficients that sum to one. Such a linear combination is called a convex combination.
Using the previous example, we would get the following:



Mathematical definition
Formally, the weighted mean of a non-empty set of data

with non-negative weights
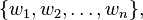
is the quantity

which means:

Therefore data elements with a high weight contribute more to the weighted mean than do elements with a low weight. The weights cannot be negative. Some may be zero, but not all of them (since division by zero is not allowed).
The formulas are simplified when the weights are normalized such that they sum up to  , i.e.
, i.e. 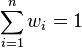 . For such normalized weights the weighted mean is simply
. For such normalized weights the weighted mean is simply
 .
.
Note that one can always normalize the weights by making the following transformation on the weights  . Using the normalized weight yields the same results as when using the original weights. Indeed,
. Using the normalized weight yields the same results as when using the original weights. Indeed,
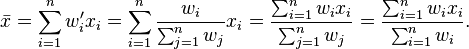
The common mean 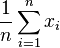 is a special case of the weighted mean where all data have equal weights,
is a special case of the weighted mean where all data have equal weights,  . When the weights are normalized then
. When the weights are normalized then 
Statistical properties
The weighted sample mean,  , with normalized weights (weights summing to one) is itself a random variable. Its expected value and standard deviation are related to the expected values and standard deviations of the observations as follows,
, with normalized weights (weights summing to one) is itself a random variable. Its expected value and standard deviation are related to the expected values and standard deviations of the observations as follows,
If the observations have expected values

then the weighted sample mean has expectation

Particularly, if the expectations of all observations are equal,  , then the expectation of the weighted sample mean will be the same,
, then the expectation of the weighted sample mean will be the same,

For uncorrelated observations with standard deviations  , the weighted sample mean has standard deviation
, the weighted sample mean has standard deviation
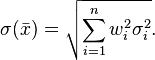
Consequently, when the standard deviations of all observations are equal, 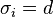 , the weighted sample mean will have standard deviation
, the weighted sample mean will have standard deviation  . Here
. Here 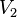 is the quantity
is the quantity

such that  . It attains its minimum value for equal weights, and its maximum when all weights except one are zero. In the former case we have
. It attains its minimum value for equal weights, and its maximum when all weights except one are zero. In the former case we have 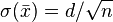 , which is related to the central limit theorem.
, which is related to the central limit theorem.
Note that due to the fact that one can always transform non-normalized weights to normalized weights all formula in this section can be adapted to non-normalized weights by replacing all  by
by  .
.
Dealing with variance
For the weighted mean of a list of data for which each element 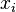 comes from a different probability distribution with known variance
comes from a different probability distribution with known variance 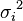 , one possible choice for the weights is given by:
, one possible choice for the weights is given by:
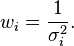
The weighted mean in this case is:

and the variance of the weighted mean is:

which reduces to  , when all
, when all 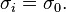
The significance of this choice is that this weighted mean is the maximum likelihood estimator of the mean of the probability distributions under the assumption that they are independent and normally distributed with the same mean.
Correcting for over- or under-dispersion
Weighted means are typically used to find the weighted mean of experimental data, rather than theoretically generated data. In this case, there will be some error in the variance of each data point. Typically experimental errors may be underestimated due to the experimenter not taking into account all sources of error in calculating the variance of each data point. In this event, the variance in the weighted mean must be corrected to account for the fact that  is too large. The correction that must be made is
is too large. The correction that must be made is

where  is divided by the number of degrees of freedom, in this case n − 1. This gives the variance in the weighted mean as:
is divided by the number of degrees of freedom, in this case n − 1. This gives the variance in the weighted mean as:

when all data variances are equal,  , they cancel out in the weighted mean variance,
, they cancel out in the weighted mean variance,  , which then reduces to the standard error of the mean (squared),
, which then reduces to the standard error of the mean (squared),  , in terms of the sample standard deviation (squared),
, in terms of the sample standard deviation (squared),  .
.
Weighted sample variance
Typically when a mean is calculated it is important to know the variance and standard deviation about that mean. When a weighted mean  is used, the variance of the weighted sample is different from the variance of the unweighted sample. The biased weighted sample variance is defined similarly to the normal biased sample variance:
is used, the variance of the weighted sample is different from the variance of the unweighted sample. The biased weighted sample variance is defined similarly to the normal biased sample variance:

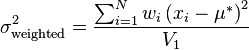
where 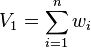 , which is 1 for normalized weights.
, which is 1 for normalized weights.
For small samples, it is customary to use an unbiased estimator for the population variance. In normal unweighted samples, the N in the denominator (corresponding to the sample size) is changed to N − 1. While this is simple in unweighted samples, it is not straightforward when the sample is weighted.
If each  is drawn from a Gaussian distribution with variance
is drawn from a Gaussian distribution with variance 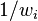 , the unbiased estimator of a weighted population variance is given by:[1]
, the unbiased estimator of a weighted population variance is given by:[1]

where 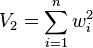 as introduced previously.
as introduced previously.
Note: If the weights are not integral frequencies (for instance, if they have been standardized to sum to 1 or if they represent the variance of each observation's measurement) as in this case, then all information is lost about the total sample size n, whence it is not possible to use an unbiased estimator because it is impossible to estimate the Bessel correction factor 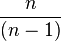 .
.
The degrees of freedom of the weighted, unbiased sample variance vary accordingly from N − 1 down to 0.
The standard deviation is simply the square root of the variance above.
If all of the are drawn from the same distribution and the integer weights indicate the number of occurrences ("repeat") of an observation in the sample, then the unbiased estimator of the weighted population variance is given by

If all are unique, then  counts the number of unique values, and
counts the number of unique values, and 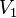 counts the number of samples.
counts the number of samples.
For example, if values  are drawn from the same distribution, then we can treat this set as an unweighted sample, or we can treat it as the weighted sample
are drawn from the same distribution, then we can treat this set as an unweighted sample, or we can treat it as the weighted sample 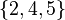 with corresponding weights
with corresponding weights 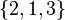 , and we should get the same results.
, and we should get the same results.
As a side note, other approaches have been described to compute the weighted sample variance.[2]
Weighted sample covariance
In a weighted sample, each row vector  (each set of single observations on each of the K random variables) is assigned a weight
(each set of single observations on each of the K random variables) is assigned a weight  . Without loss of generality, assume that the weights are normalized:
. Without loss of generality, assume that the weights are normalized:

If they are not, divide the weights by their sum:

Then the weighted mean vector  is given by
is given by

(if the weights are not normalized, an equivalent formula to compute the weighted mean is:)
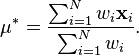
and an approximation of the unbiased weighted covariance matrix 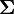 (but without Bessel correction) is
(but without Bessel correction) is

If all weights are the same, with  , then the weighted mean and covariance reduce to the sample mean and covariance above.
, then the weighted mean and covariance reduce to the sample mean and covariance above.
There is no unbiased (with Bessel correction) equation to compute the weighted covariance matrix in this case because if, as in the case above, the weights are not integral frequencies (for instance, if they have been standardized to sum to 1 or if they represent the variance of each observation's measurement), then all information is lost about the total sample size n, whence it is impossible to estimate precisely the Bessel correction factor .
Alternatively, if each weight assigns a number of occurrences for one observation value, so (sometimes called the number of "repeats") and is unnormalized so that  with
with  being the sample size (total number of observations), then the biased weighted sample covariance matrix is given by:[4]
being the sample size (total number of observations), then the biased weighted sample covariance matrix is given by:[4]
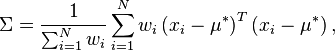
and the correctly unbiased weighted sample covariance matrix is given by applying the Bessel correction (since  which is the real sample size):
which is the real sample size):

Vector-valued estimates
The above generalizes easily to the case of taking the mean of vector-valued estimates. For example, estimates of position on a plane may have less certainty in one direction than another. As in the scalar case, the weighted mean of multiple estimates can provide a maximum likelihood estimate. We simply replace  by the covariance matrix:[5]
by the covariance matrix:[5]

The weighted mean in this case is:
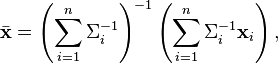
and the covariance of the weighted mean is:

For example, consider the weighted mean of the point [1 0] with high variance in the second component and [0 1] with high variance in the first component. Then
![{\mathbf {x}}_{1}:=[10]^{\top },\qquad \Sigma _{1}:={\begin{bmatrix}1&0\\0&100\end{bmatrix}}](/2014-wikipedia_en_all_02_2014/I/media/8/8/6/7/88671b5420f0eb2c9a0a413cd1d712fd.png)
![{\mathbf {x}}_{2}:=[01]^{\top },\qquad \Sigma _{2}:={\begin{bmatrix}100&0\\0&1\end{bmatrix}}](/2014-wikipedia_en_all_02_2014/I/media/c/2/5/4/c25422b48da0e7c638f63ab5a1e8bb88.png)
then the weighted mean is:
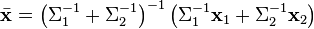
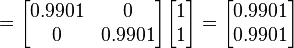
which makes sense: the [1 0] estimate is "compliant" in the second component and the [0 1] estimate is compliant in the first component, so the weighted mean is nearly [1 1].
Accounting for correlations
In the general case, suppose that ![{\mathbf {X}}=[x_{1},\dots ,x_{n}]](/2014-wikipedia_en_all_02_2014/I/media/2/6/3/6/2636af2ccd97baf04c3d1bb68299694e.png) ,
,  is the covariance matrix relating the quantities , is the common mean to be estimated, and
is the covariance matrix relating the quantities , is the common mean to be estimated, and  is the design matrix [1, ..., 1] (of length
is the design matrix [1, ..., 1] (of length  ). The Gauss–Markov theorem states that the estimate of the mean having minimum variance is given by:
). The Gauss–Markov theorem states that the estimate of the mean having minimum variance is given by:

and

Decreasing strength of interactions
Consider the time series of an independent variable  and a dependent variable
and a dependent variable  , with observations sampled at discrete times
, with observations sampled at discrete times 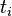 . In many common situations, the value of at time depends not only on but also on its past values. Commonly, the strength of this dependence decreases as the separation of observations in time increases. To model this situation, one may replace the independent variable by its sliding mean
. In many common situations, the value of at time depends not only on but also on its past values. Commonly, the strength of this dependence decreases as the separation of observations in time increases. To model this situation, one may replace the independent variable by its sliding mean  for a window size
for a window size  .
.
| Range (1–5) | Weighted mean equivalence |
|---|---|
| 3.34–5.00 | Strong |
| 1.67–3.33 | Satisfactory |
| 0.00–1.66 | Weak |
Exponentially decreasing weights
In the scenario described in the previous section, most frequently the decrease in interaction strength obeys a negative exponential law. If the observations are sampled at equidistant times, then exponential decrease is equivalent to decrease by a constant fraction  at each time step. Setting
at each time step. Setting  we can define normalized weights by
we can define normalized weights by
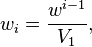
where is the sum of the unnormalized weights. In this case is simply

approaching  for large values of .
for large values of .
The damping constant  must correspond to the actual decrease of interaction strength. If this cannot be determined from theoretical considerations, then the following properties of exponentially decreasing weights are useful in making a suitable choice: at step
must correspond to the actual decrease of interaction strength. If this cannot be determined from theoretical considerations, then the following properties of exponentially decreasing weights are useful in making a suitable choice: at step  , the weight approximately equals
, the weight approximately equals  , the tail area the value
, the tail area the value  , the head area
, the head area 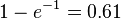 . The tail area at step is
. The tail area at step is  . Where primarily the closest observations matter and the effect of the remaining observations can be ignored safely, then choose such that the tail area is sufficiently small.
. Where primarily the closest observations matter and the effect of the remaining observations can be ignored safely, then choose such that the tail area is sufficiently small.
Weighted averages of functions
The concept of weighted average can be extended to functions.[6] Weighted averages of functions play an important role in the systems of weighted differential and integral calculus.[7]
See also
- Average
- Mean
- Summary statistics
- Central tendency
- Weight function
- Weighted least squares
- Weighted average cost of capital
- Weighting
- Weighted geometric mean
- Weighted harmonic mean
- Weighted median
- Standard deviation
Notes
- ↑ http://www.gnu.org/software/gsl/manual/html_node/Weighted-Samples.html
- ↑ Weighted Standard Error and its Impact on Significance Testing (WinCross vs. Quantum & SPSS), Dr. Albert Madansky
- ↑ Mark Galassi, Jim Davies, James Theiler, Brian Gough, Gerard Jungman, Michael Booth, and Fabrice Rossi. GNU Scientific Library - Reference manual, Version 1.15, 2011. Sec. 21.7 Weighted Samples
- ↑ George R. Price, Ann. Hum. Genet., Lond, pp485-490, Extension of covariance selection mathematics, 1972.
- ↑ James, Frederick (2006). Statistical Methods in Experimental Physics (2nd ed.). Singapore: World Scientific. p. 324. ISBN 981-270-527-9.
- ↑ G. H. Hardy, J. E. Littlewood, and G. Pólya. Inequalities (2nd ed.), Cambridge University Press, ISBN 978-0-521-35880-4, 1988.
- ↑ Jane Grossman, Michael Grossman, Robert Katz. [http://books.google.com/books?as_brr=0&q=%22The+First+Systems+of+Weighted+Differential+and+Integral+Calculus%E2%80%8E%22&btnG=Search+Books,The First Systems of Weighted Differential and Integral Calculus], ISBN 0-9771170-1-4, 1980.
Further reading
- Bevington, Philip R (1969). Data Reduction and Error Analysis for the Physical Sciences. New York, N.Y.: McGraw-Hill. OCLC 300283069.
External links
- David Terr, "Weighted Mean", MathWorld.
- Weighted Mean Calculation