Visual hull
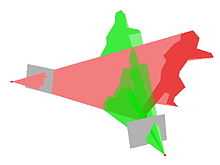

A visual hull is a geometric entity created by shape-from-silhouette 3D reconstruction technique introduced by A. Laurentini. This technique assumes the foreground object in an image can be separated from the background. Under this assumption, the original image can be thresholded into a foreground/background binary image, which we call a silhouette image. The foreground mask, known as a silhouette, is the 2D projection of the corresponding 3D foreground object. Along with the camera viewing parameters, the silhouette defines a back-projected generalized cone that contains the actual object. This cone is called a silhouette cone. The upper right thumbnail shows two such cones produced from two silhouette images taken from different viewpoints. The intersection of the two cones is called a visual hull,[1] which is a bounding geometry of the actual 3D object (see the bottom right thumbnail).
In two dimensions
A technique used in some modern touchscreen devices employs cameras placed in the corners situated opposite infrared LEDs. The one-dimensional projection (shadow) of objects on the surface may be used to reconstruct the convex hull of the object.
See also
References
- ↑ A. Laurentini (February 1994). "The visual hull concept for silhouette-based image understanding". IEEE Trans. Pattern Analysis and Machine Intelligence. pp. 150–162.