Unicity distance
In cryptography, unicity distance is the length of an original ciphertext needed to break the cipher by reducing the number of possible spurious keys to zero in a brute force attack. That is, after trying every possible key, there should be just one decipherment that makes sense, i.e. expected amount of ciphertext needed to determine the key completely, assuming the underlying message has redundancy.
Consider an attack on the ciphertext string "WNAIW" encrypted using a Vigenère cipher with a five letter key. Conceivably, this string could be deciphered into any other string — RIVER and WATER are both possibilities for certain keys. This is a general rule of cryptanalysis: with no additional information it is impossible to decode this message.
Of course, even in this case, only a certain number of five letter keys will result in English words. Trying all possible keys we will not only get RIVER and WATER, but SXOOS and KHDOP as well. The number of "working" keys will likely be very much smaller than the set of all possible keys. The problem is knowing which of these "working" keys is the right one; the rest are spurious.
Relation with key size and possible plaintexts
In general, given any particular assumptions about the size of the key and the number of possible messages, there is an average ciphertext length where there is only one key (on average) that will generate a readable message. In the example above we see only upper case Roman characters, so if we assume this is the input then there are 26 possible letters for each position in the string. Likewise if we assume five-character upper case keys, there are K=265 possible keys, of which the majority will not "work".
A tremendous number of possible messages, N, can be generated using even this limited set of characters: N = 26L, where L is the length of the message. However only a smaller set of them is readable plaintext due to the rules of the language, perhaps M of them, where M is likely to be very much smaller than N. Moreover M has a one-to-one relationship with the number of keys that work, so given K possible keys, only K × (M/N) of them will "work". One of these is the correct key, the rest are spurious.
Since N is dependent on the length of the message L, whereas M is dependent on the number of keys, K, there is some L where the number of spurious keys is zero. This L is the unicity distance.
Relation with key entropy and plaintext redundancy
The unicity distance can also be defined as the minimum amount of ciphertext-only required to permit a computationally unlimited adversary to recover the unique encryption key.
The expected unicity distance is accordingly:
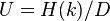
where U is the unicity distance, H(k) is the entropy of the key space (e.g. 128 for 2128 equiprobable keys, rather less if the key is a memorized pass-phrase).
D is defined as the plaintext redundancy in bits per character.
Now an alphabet of 32 characters can carry 5 bits of information per character (as 32 = 25). In general the number of bits of information is lg N, where N is the number of characters in the alphabet. So for English each character can convey log2(26) = 4.7 bits of information. See Binary logarithm for details on log2.
However the average amount of actual information carried per character in meaningful English text is only about 1.5 bits per character[citation needed]. So the plain text redundancy is D = 4.7 − 1.5 = 3.2.
Basically the bigger the unicity distance the better. For a one time pad, given the unbounded entropy of the key space, we have  , which is consistent with the one-time pad being theoretically unbreakable.
, which is consistent with the one-time pad being theoretically unbreakable.
Unicity distance of substitution cipher
For a simple substitution cipher, the number of possible keys is 26! = 4.0329 × 1026 = 288.4, the number of ways in which the alphabet can be permuted. Assuming all keys are equally likely, H(k) = log2(26!) = 88.4 bits. For English text D = 3.2, thus U = 88.4/3.2 = 28.
So given 28 characters of ciphertext it should be theoretically possible to work out an English plaintext and hence the key.
Practical application
Unicity distance is a useful theoretical measure, but it doesn't say much about the security of a block cipher when attacked by an adversary with real-world (limited) resources. Consider a block cipher with a unicity distance of three ciphertext blocks. Although there is clearly enough information for a computationally unbounded adversary to find the right key (simple exhaustive search), this may be computationally infeasible in practice.
The unicity distance can be increased by reducing the plaintext redundancy. One way to do this is to deploy data compression techniques prior to encryption, for example by removing redundant vowels while retaining readability. This is a good idea anyway, as it reduces the amount of data to be encrypted.
Another way to increase the unicity distance is to increase the number of possible valid sequences in the files as it is read. Since if for at least the first several blocks any bit pattern can effectively be part of a valid message then the unicity distance has not been reached. This is possible on long files when certain bijective string sorting permutations are used, such as the many variants of bijective BWT transforms.
Ciphertexts greater than the unicity distance can be assumed to have only one meaningful decryption. Ciphertexts shorter than the unicity distance may have multiple plausible decryptions. Unicity distance is not a measure of how much ciphertext is required for cryptanalysis, but how much ciphertext is required for there to be only one reasonable solution for cryptanalysis.
External links
- Bruce Schneier: How to Recognize Plaintext (Crypto-Gram Newsletter December 15, 1998)
- Unicity Distance computed for common ciphers