Trace (linear algebra)
- For other uses, see Trace
In linear algebra, the trace of an n-by-n square matrix A is defined to be the sum of the elements on the main diagonal (the diagonal from the upper left to the lower right) of A, i.e.,

where ajk denotes the entry on the j-th row and k-th column of A. The trace of a matrix is the sum of the (complex) eigenvalues, and it is invariant with respect to a change of basis. This characterization can be used to define the trace of a linear operator in general. Note that the trace is only defined for a square matrix (i.e., n × n).
Geometrically, the trace can be interpreted as the infinitesimal change in volume (as the derivative of the determinant), which is made precise in Jacobi's formula.
The term trace is a calque from the German Spur (cognate with the English spoor), which, as a function in mathematics, is often abbreviated to "tr".
Example
Let T be a linear operator represented by the matrix
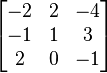 .
.
Then tr(T) = −2 + 1 − 1 = −2.
Properties
Basic properties
The trace is a linear mapping. That is,
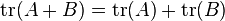 ,
,
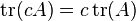 .
.
for all square matrices A and B, and all scalars c.
A matrix and its transpose have the same trace:
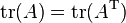 .
.
This follows immediately from the fact that transposing a square matrix does not affect elements along the main diagonal.
Trace of a product
The trace of a product can be rewritten as the sum of entry-wise products of elements:
 .
.
This means that the trace of a product of matrices functions similarly to a dot product of vectors. For this reason, generalizations of vector operations to matrices (e.g. in matrix calculus and statistics) often involve a trace of matrix products.
The trace of a product can also be written in the following forms:
|
|
|
|
|
|

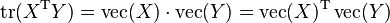
The matrices in a trace of a product can be switched: If A is an m×n matrix and B is an n×m matrix, then
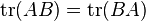 .[1]
.[1]
Equivalently, the trace is invariant under cyclic permutations, i.e.,
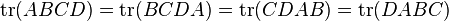 .
.
This is known as the cyclic property.
Note that arbitrary permutations are not allowed: in general,
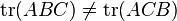 .
.
However, if products of three symmetric matrices are considered, any permutation is allowed. (Proof: tr(ABC) = tr(AT BT CT) = tr(AT(CB)T) = tr((CB)TAT) = tr((ACB)T) = tr(ACB), where the last equality is because the traces of a matrix and its transpose are equal.) For more than three factors this is not true.
Unlike the determinant, the trace of the product is not the product of traces. What is true is that the trace of the tensor product of two matrices is the product of their traces:
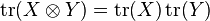 .
.
Other properties
The following three properties:
- ,
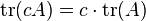 ,
,- ,
characterize the trace completely in the sense as follows. Let f be a linear functional on the space of square matrices satisfying f(x y) = f(y x). Then f and tr are proportional.[2]
The trace is similarity-invariant, which means that A and P−1AP have the same trace. This is because
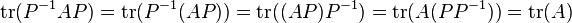 .
.
If A is symmetric and B is antisymmetric, then
 .
.
The trace of the identity matrix is the dimension of the space; this leads to generalizations of dimension using trace. The trace of an idempotent matrix A (for which A2 = A) is the rank of A. The trace of a nilpotent matrix is zero.
More generally, if f(x) = (x − λ1)d1···(x − λk)dk is the characteristic polynomial of a matrix A, then
 .
.
When both A and B are n-by-n, the trace of the (ring-theoretic) commutator of A and B vanishes: tr([A, B]) = 0; one can state this as "the trace is a map of Lie algebras 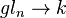 from operators to scalars", as the commutator of scalars is trivial (it is an abelian Lie algebra). In particular, using similarity invariance, it follows that the identity matrix is never similar to the commutator of any pair of matrices.
from operators to scalars", as the commutator of scalars is trivial (it is an abelian Lie algebra). In particular, using similarity invariance, it follows that the identity matrix is never similar to the commutator of any pair of matrices.
Conversely, any square matrix with zero trace is a linear combinations of the commutators of pairs of matrices.[3] Moreover, any square matrix with zero trace is unitarily equivalent to a square matrix with diagonal consisting of all zeros.
The trace of any power of a nilpotent matrix is zero. When the characteristic of the base field is zero, the converse also holds: if 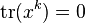 for all
for all  , then
, then  is nilpotent.
is nilpotent.
- The trace of a projection matrix is the dimension of the target space. If
-
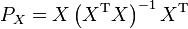 ,
,
-
- then
-
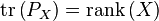 .
.
-
Exponential trace
Expressions like exp(tr(A)), where A is a square matrix, occur so often in some fields (e.g. multivariate statistical theory), that a shorthand notation has become common:
 .
.
This is sometimes referred to as the exponential trace function; it is used in the Golden–Thompson inequality.
Trace of a linear operator
Given some linear map f : V → V (V is a finite-dimensional vector space) generally, we can define the trace of this map by considering the trace of matrix representation of f, that is, choosing a basis for V and describing f as a matrix relative to this basis, and taking the trace of this square matrix. The result will not depend on the basis chosen, since different bases will give rise to similar matrices, allowing for the possibility of a basis-independent definition for the trace of a linear map.
Such a definition can be given using the canonical isomorphism between the space End(V) of linear maps on V and V ⊗ V*, where V* is the dual space of V. Let v be in V and let f be in V*. Then the trace of the decomposable element v ⊗ f is defined to be f(v); the trace of a general element is defined by linearity. Using an explicit basis for V and the corresponding dual basis for V*, one can show that this gives the same definition of the trace as given above.
Eigenvalue relationships
If A is a square n-by-n matrix with real or complex entries and if λ1,...,λn are the eigenvalues of A (listed according to their algebraic multiplicities), then
 .
.
This follows from the fact that A is always similar to its Jordan form, an upper triangular matrix having λ1,...,λn on the main diagonal. In contrast, the determinant of 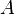 is the product of its eigenvalues; i.e.,
is the product of its eigenvalues; i.e.,
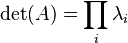 .
.
More generally,
 .
.
Derivatives
The trace corresponds to the derivative of the determinant: it is the Lie algebra analog of the (Lie group) map of the determinant. This is made precise in Jacobi's formula for the derivative of the determinant.
As a particular case, at the identity, the derivative of the determinant actually amounts to the trace: 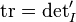 . From this (or from the connection between the trace and the eigenvalues), one can derive a connection between the trace function, the exponential map between a Lie algebra and its Lie group (or concretely, the matrix exponential function), and the determinant:
. From this (or from the connection between the trace and the eigenvalues), one can derive a connection between the trace function, the exponential map between a Lie algebra and its Lie group (or concretely, the matrix exponential function), and the determinant:
 .
.
For example, consider the one-parameter family of linear transformations given by rotation through angle θ,
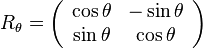 .
.
These transformations all have determinant 1, so they preserve area. The derivative of this family at θ = 0 is the antisymmetric matrix
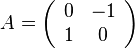
which clearly has trace zero, indicating that this matrix represents an infinitesimal transformation which preserves area.
A related characterization of the trace applies to linear vector fields. Given a matrix A, define a vector field F on ℝn by F(x) = A x. The components of this vector field are linear functions (given by the rows of A). Its divergence div F is a constant function, whose value is equal to tr(A). By the divergence theorem, one can interpret this in terms of flows: if F(x) represents the velocity of a fluid at location x and U is a region in ℝn, the net flow of the fluid out of U is given by tr(A) · vol(U), where vol(U) is the volume of U.
The trace is a linear operator, hence it commutes with the derivative:
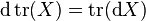 .
.
Applications
The trace of a 2-by-2 complex matrix is used to classify Möbius transformations. First the matrix is normalized to make its determinant equal to one. Then, if the square of the trace is 4, the corresponding transformation is parabolic. If the square is in the interval [0,4), it is elliptic. Finally, if the square is greater than 4, the transformation is loxodromic. See classification of Möbius transformations.
The trace is used to define characters of group representations. Two representations 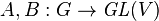 of a group G are equivalent (up to change of basis on V) if
of a group G are equivalent (up to change of basis on V) if  for all g ∈ G.
for all g ∈ G.
The trace also plays a central role in the distribution of quadratic forms.
Lie algebra
The trace is a map of Lie algebras 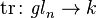 from the Lie algebra gln of operators on a n-dimensional space (n × n matrices) to the Lie algebra k of scalars; as k is abelian (the Lie bracket vanishes), the fact that this is a map of Lie algebras is exactly the statement that the trace of a bracket vanishes:
from the Lie algebra gln of operators on a n-dimensional space (n × n matrices) to the Lie algebra k of scalars; as k is abelian (the Lie bracket vanishes), the fact that this is a map of Lie algebras is exactly the statement that the trace of a bracket vanishes: ![\operatorname {tr}([A,B])=0](/2014-wikipedia_en_all_02_2014/I/media/1/a/0/2/1a027f1a7065eb78796a60d1f14ede19.png) .
.
The kernel of this map, a matrix whose trace is zero, is often said to be traceless or tracefree, and these matrices form the simple Lie algebra sln, which is the Lie algebra of the special linear group of matrices with determinant 1. The special linear group consists of the matrices which do not change volume, while the special linear algebra is the matrices which infinitesimally do not change volume.
In fact, there is an internal direct sum decomposition  of operators/matrices into traceless operators/matrices and scalars operators/matrices. The projection map onto scalar operators can be expressed in terms of the trace, concretely as:
of operators/matrices into traceless operators/matrices and scalars operators/matrices. The projection map onto scalar operators can be expressed in terms of the trace, concretely as:
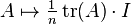 .
.
Formally, one can compose the trace (the counit map) with the unit map 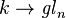 of "inclusion of scalars" to obtain a map
of "inclusion of scalars" to obtain a map 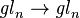 mapping onto scalars, and multiplying by n. Dividing by n makes this a projection, yielding the formula above.
mapping onto scalars, and multiplying by n. Dividing by n makes this a projection, yielding the formula above.
In terms of short exact sequences, one has

which is analogous to

for Lie groups. However, the trace splits naturally (via  times scalars) so
times scalars) so 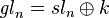 , but the splitting of the determinant would be as the nth root times scalars, and this does not in general define a function, so the determinant does not split and the general linear group does not decompose:
, but the splitting of the determinant would be as the nth root times scalars, and this does not in general define a function, so the determinant does not split and the general linear group does not decompose: 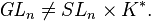
Bilinear forms
The bilinear form
![B(x,y)=\operatorname {tr}(\operatorname {ad}(x)\operatorname {ad}(y)){\text{ where }}\operatorname {ad}(x)y=[x,y]=xy-yx](/2014-wikipedia_en_all_02_2014/I/media/2/a/8/d/2a8db95ada7f9ea3923f6e07d710b34d.png)
is called the Killing form, which is used for the classification of Lie algebras.
The trace defines a bilinear form:
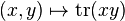
(x, y square matrices).
The form is symmetric, non-degenerate[4] and associative in the sense that:
![\operatorname {tr}(x[y,z])=\operatorname {tr}([x,y]z)](/2014-wikipedia_en_all_02_2014/I/media/0/1/7/8/0178c6e946b88191d4305e37ebd58828.png) .
.
In a simple Lie algebra (e.g., 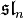 ), every such bilinear form is proportional to each other; in particular, to the Killing form.
), every such bilinear form is proportional to each other; in particular, to the Killing form.
Two matrices x and y are said to be trace orthogonal if
-
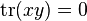 .
.
Inner product
For an m-by-n matrix A with complex (or real) entries and * being the conjugate transpose, we have

with equality if and only if A = 0. The assignment
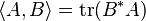
yields an inner product on the space of all complex (or real) m-by-n matrices.
The norm induced by the above inner product is called the Frobenius norm. Indeed it is simply the Euclidean norm if the matrix is considered as a vector of length m n.
It follows that if A and B are positive semi-definite matrices of the same size then
-
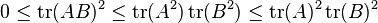 .[5]
.[5]
Generalization
The concept of trace of a matrix is generalised to the trace class of compact operators on Hilbert spaces, and the analog of the Frobenius norm is called the Hilbert–Schmidt norm.
The partial trace is another generalization of the trace that is operator-valued.
If A is a general associative algebra over a field k, then a trace on A is often defined to be any map tr: A → k which vanishes on commutators: tr([a, b]) = 0 for all a, b in A. Such a trace is not uniquely defined; it can always at least be modified by multiplication by a nonzero scalar.
A supertrace is the generalization of a trace to the setting of superalgebras.
The operation of tensor contraction generalizes the trace to arbitrary tensors.
Coordinate-free definition
We can identify the space of linear operators on a vector space V with the space 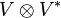 , where
, where 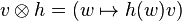 . We also have a canonical bilinear function
. We also have a canonical bilinear function  that consists of applying an element w* of V* to an element v of V to get an element of F, in symbols
that consists of applying an element w* of V* to an element v of V to get an element of F, in symbols 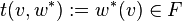 . This induces a linear function on the tensor product (by its universal property)
. This induces a linear function on the tensor product (by its universal property)  , which, as it turns out, when that tensor product is viewed as the space of operators, is equal to the trace.
, which, as it turns out, when that tensor product is viewed as the space of operators, is equal to the trace.
This also clarifies why and why  , as composition of operators (multiplication of matrices) and trace can be interpreted as the same pairing. Viewing
, as composition of operators (multiplication of matrices) and trace can be interpreted as the same pairing. Viewing 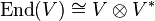 , one may interpret the composition map
, one may interpret the composition map 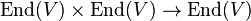 as
as
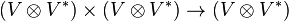
coming from the pairing 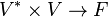 on the middle terms. Taking the trace of the product then comes from pairing on the outer terms, while taking the product in the opposite order and then taking the trace just switches which pairing is applied first. On the other hand, taking the trace of A and the trace of B corresponds to applying the pairing on the left terms and on the right terms (rather than on inner and outer), and is thus different.
on the middle terms. Taking the trace of the product then comes from pairing on the outer terms, while taking the product in the opposite order and then taking the trace just switches which pairing is applied first. On the other hand, taking the trace of A and the trace of B corresponds to applying the pairing on the left terms and on the right terms (rather than on inner and outer), and is thus different.
In coordinates, this corresponds to indexes: multiplication is given by 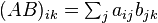 , so
, so 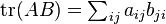 and
and 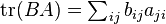 which is the same, while
which is the same, while 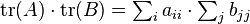 , which is different.
, which is different.
For  finite-dimensional, with basis
finite-dimensional, with basis 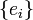 and dual basis
and dual basis 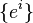 , then
, then 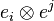 is the ij'-entry of the matrix of the operator with respect to that basis. Any operator is therefore a sum of the form
is the ij'-entry of the matrix of the operator with respect to that basis. Any operator is therefore a sum of the form  . With
. With 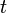 defined as above,
defined as above, 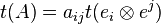 . The latter, however, is just the Kronecker delta, being 1 if i = j and 0 otherwise. This shows that
. The latter, however, is just the Kronecker delta, being 1 if i = j and 0 otherwise. This shows that 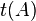 is simply the sum of the coefficients along the diagonal. This method, however, makes coordinate invariance an immediate consequence of the definition.
is simply the sum of the coefficients along the diagonal. This method, however, makes coordinate invariance an immediate consequence of the definition.
Dual
Further, one may dualize this map, obtaining a map  . This map is precisely the inclusion of scalars, sending 1 ∈ F to the identity matrix: "trace is dual to scalars". In the language of bialgebras, scalars are the unit, while trace is the counit.
. This map is precisely the inclusion of scalars, sending 1 ∈ F to the identity matrix: "trace is dual to scalars". In the language of bialgebras, scalars are the unit, while trace is the counit.
One can then compose these, 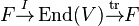 , which yields multiplication by n, as the trace of the identity is the dimension of the vector space.
, which yields multiplication by n, as the trace of the identity is the dimension of the vector space.
See also
- Characteristic function
- Field trace
- Golden–Thompson inequality
- Specht's theorem
- Trace class
- Trace inequalities
- von Neumann's trace inequality
Notes
- ↑ This is immediate from the definition of the matrix product:
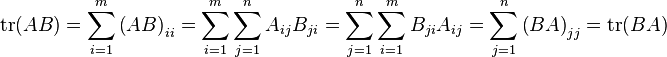 .
.
- ↑ Proof:
 if and only if
if and only if  and
and 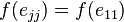 (with the standard basis
(with the standard basis 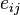 ),
),
![f(A)=\sum _{{i,j}}[A]_{{ij}}f(e_{{ij}})=\sum _{i}[A]_{{ii}}f(e_{{11}})=f(e_{{11}})\operatorname {tr}(A)](/2014-wikipedia_en_all_02_2014/I/media/a/f/8/4/af848639548e3600bf90af38bd90713e.png) .
.
, as tr(AB) = tr(BA) (equivalently, ) defines the trace on sln, which has complement the scalar matrices, and leaves one degree of freedom: any such map is determined by its value on scalars, which is one scalar parameter and hence all are multiple of the trace, a non-zero such map. - ↑ Proof: is a semisimple Lie algebra and thus every element in it is a linear combination of commutators of some pairs of elements, otherwise the derived algebra would be a proper ideal.
- ↑ This follows from the fact that
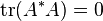 if and only if
if and only if 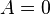
- ↑ Can be proven with the Cauchy–Schwarz inequality.
External links
- Hazewinkel, Michiel, ed. (2001), "Trace of a square matrix", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4