Star height problem
The star height problem in formal language theory is the question whether all regular languages can be expressed using regular expressions of limited star height, i.e. with a limited nesting depth of Kleene stars. Specifically, is a nesting depth of one always sufficient? If not, is there an algorithm to determine how many are required? The problem was raised by Eggan (1963).
Families of regular languages with unbounded star height
The first question was answered in the negative when in 1963, Eggan gave examples of regular languages of star height n for every n. Here, the star height h(L) of a regular language L is defined as the minimum star height among all regular expressions representing L. The first few languages found by Eggan (1963) are described in the following, by means of giving a regular expression for each language:

The construction principle for these expressions is that expression  is obtained by concatenating two copies of
is obtained by concatenating two copies of 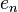 , appropriately renaming the letters of the second copy using fresh alphabet symbols, concatenating the result with another fresh alphabet symbol, and then by surrounding the resulting expression with a Kleene star. The remaining, more difficult part, is to prove that for there is no equivalent regular expression of star height less than n; a proof is given in (Eggan 1963).
, appropriately renaming the letters of the second copy using fresh alphabet symbols, concatenating the result with another fresh alphabet symbol, and then by surrounding the resulting expression with a Kleene star. The remaining, more difficult part, is to prove that for there is no equivalent regular expression of star height less than n; a proof is given in (Eggan 1963).
However, Eggan's examples use a large alphabet, of size 2n-1 for the language with star height n. He thus asked whether we can also find examples over binary alphabets. This was proved to be true shortly afterwards by Dejean & Schützenberger (1966).
Their examples can be described by an inductively defined family of regular expressions over the binary alphabet 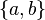 as follows–cf. Salomaa (1981):
as follows–cf. Salomaa (1981):

Again, a rigorous proof is needed for the fact that does not admit an equivalent regular expression of lower star height. Proofs are given by (Dejean & Schützenberger 1966) and by (Salomaa 1981).
Computing the star height of regular languages
In contrast, the second question turned out to be much more difficult, and the question became a famous open problem in formal language theory for over two decades (Brzozowski 1980). For years, there was only little progress. The pure-group languages were the first interesting family of regular languages for which the star height problem was proved to be decidable (McNaughton 1967). But the general problem remained open for more than 25 years until it was settled by Hashiguchi, who in 1988 published an algorithm to determine the star height of any regular language. The algorithm wasn't at all practical, being of non-elementary complexity. To illustrate the immense resource consumptions of that algorithm, Lombardy and Sakarovitch (2002) give some actual numbers:
| “ |
[The procedure described by Hashiguchi] leads to computations that are by far impossible, even for very small examples. For instance, if L is accepted by a 4 state automaton of loop complexity 3 (and with a small 10 element transition monoid), then a very low minorant of the number of languages to be tested with L for equality is:
|
” |
| —S. Lombardy and J. Sakarovitch, Star Height of Reversible Languages and Universal Automata, LATIN 2002 | ||

Notice that alone the number 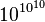 has 10 billion zeros when written down in decimal notation, and is already by far larger than the number of atoms in the observable universe.
has 10 billion zeros when written down in decimal notation, and is already by far larger than the number of atoms in the observable universe.
A much more efficient algorithm than Hashiguchi's procedure was devised by Kirsten in 2005. This algorithm runs, for a given nondeterministic finite automaton as input, within double-exponential space. Yet the resource requirements of this algorithm still greatly exceed the margins of what is considered practically feasible.
See also
References
- Eggan, Lawrence C. (1963). "Transition graphs and the star-height of regular events". Michigan Mathematical Journal 10 (4): 385–397. doi:10.1307/mmj/1028998975. Zbl 0173.01504.
- Dejean, Françoise; Schützenberger, Marcel-Paul (1966). "On a Question of Eggan". Information and Control 9 (1): 23–25. doi:10.1016/S0019-9958(66)90083-0.
- McNaughton, Robert (1967). "The Loop Complexity of Pure-Group Events". Information and Control 11 (1–2): 167–176. doi:10.1016/S0019-9958(67)90481-0.
- Brzozowski, Janusz A. (1980). "Open problems about regular languages". In Book, Ronald V. Formal language theory—Perspectives and open problems. New York: Academic Press. pp. 23–47. ISBN 0-12-115350-9. (technical report version)
- Salomaa, Arto (1981). Jewels of Formal Language Theory. Melbourne: Pitman Publishing. ISBN 0-273-08522-0. Zbl 0487.68063.
- Hashiguchi, Kosaburo (1982). "Regular languages of star height one". Information and Control 53 (2): 199–210. doi:10.1016/S0019-9958(82)91028-2.
- Hashiguchi, Kosaburo (1988). "Algorithms for Determining Relative Star Height and Star Height". Information and Computation 78 (2): 124–169. doi:10.1016/0890-5401(88)90033-8.
- Lombardy, Sylvain; Sakarovitch, Jacques (2002). "Star Height of Reversible Languages and Universal Automata". 5th Latin American Symposium on Theoretical Informatics (LATIN) 2002, vol. 2286 of LNCS (Springer).
- Kirsten, Daniel (2005). "Distance Desert Automata and the Star Height Problem". RAIRO - Informatique Théorique et Applications 39 (3): 455–509. doi:10.1051/ita:2005027.
- Sakarovitch, Jacques (2009). Elements of automata theory. Translated from the French by Reuben Thomas. Cambridge: Cambridge University Press. ISBN 978-0-521-84425-3. Zbl 1188.68177.