Standard deviation


In statistics and probability theory, the standard deviation (represented by the Greek letter sigma, σ) shows how much variation or dispersion from the average exists.[1] A low standard deviation indicates that the data points tend to be very close to the mean (also called expected value); a high standard deviation indicates that the data points are spread out over a large range of values.
The standard deviation of a random variable, statistical population, data set, or probability distribution is the square root of its variance. It is algebraically simpler though in practice less robust than the average absolute deviation.[2][3] A useful property of the standard deviation is that, unlike the variance, it is expressed in the same units as the data. Note, however, that for measurements with percentage as the unit, the standard deviation will have percentage points as the unit.
In addition to expressing the variability of a population, the standard deviation is commonly used to measure confidence in statistical conclusions. For example, the margin of error in polling data is determined by calculating the expected standard deviation in the results if the same poll were to be conducted multiple times. The reported margin of error is typically about twice the standard deviation – the half-width of a 95 percent confidence interval. In science, researchers commonly report the standard deviation of experimental data, and only effects that fall much farther than one standard deviation away from what would have been expected are considered statistically significant – normal random error or variation in the measurements is in this way distinguished from causal variation. The standard deviation is also important in finance, where the standard deviation on the rate of return on an investment is a measure of the volatility of the investment.
When only a sample of data from a population is available, the term standard deviation of the sample or sample standard deviation can refer to either the above-mentioned quantity as applied to those data or to a modified quantity that is a better estimate of the population standard deviation (the standard deviation of the entire population).
Basic examples
For a finite set of numbers, the standard deviation is found by taking the square root of the average of the squared differences of the values from their average value. For example, consider a population consisting of the following eight values:
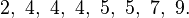
These eight data points have the mean (average) of 5:

First, calculate the difference of each data point from the mean, and square the result of each:
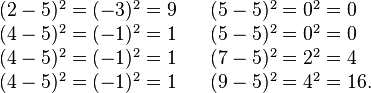
Next, calculate the mean of these values, and take the square root:
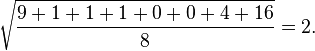
This quantity is the population standard deviation, and is equal to the square root of the variance. This formula is valid only if the eight values we began with form the complete population. If the values instead were a random sample drawn from some larger parent population, then we would have divided by 7 (which is n−1) instead of 8 (which is n) in the denominator of the last formula, and then the quantity thus obtained would be called the sample standard deviation. Dividing by n−1 gives a better estimate of the population standard deviation than dividing by n.
As a slightly more complicated real-life example, the average height for adult men in the United States is about 70 inches, with a standard deviation of around 3 inches. This means that most men (about 68 percent, assuming a normal distribution) have a height within 3 inches of the mean (67–73 inches) – one standard deviation – and almost all men (about 95%) have a height within 6 inches of the mean (64–76 inches) – two standard deviations. If the standard deviation were zero, then all men would be exactly 70 inches tall. If the standard deviation were 20 inches, then men would have much more variable heights, with a typical range of about 50–90 inches. Three standard deviations account for 99.7 percent of the sample population being studied, assuming the distribution is normal (bell-shaped).
Definition of population values
Let X be a random variable with mean value μ:
![\operatorname {E}[X]=\mu .\,\!](/2014-wikipedia_en_all_02_2014/I/media/f/d/d/f/fddf3e7c90b84e8aca0189247b2f1375.png)
Here the operator E denotes the average or expected value of X. Then the standard deviation of X is the quantity
![{\begin{aligned}\sigma &={\sqrt {\operatorname E[(X-\mu )^{2}]}}\\&={\sqrt {\operatorname E[X^{2}]+\operatorname E[(-2\mu X)]+\operatorname E[\mu ^{2}]}}={\sqrt {\operatorname E[X^{2}]-2\mu \operatorname E[X]+\mu ^{2}}}\\&={\sqrt {\operatorname E[X^{2}]-2\mu ^{2}+\mu ^{2}}}={\sqrt {\operatorname E[X^{2}]-\mu ^{2}}}\\&={\sqrt {\operatorname E[X^{2}]-(\operatorname E[X])^{2}}}\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/0/8/6/6/0866a824545c9cf44dc241fe4e7ab498.png)
(derived using the properties of expected value).
In other words the standard deviation σ (sigma) is the square root of the variance of X; i.e., it is the square root of the average value of (X − μ)2.
The standard deviation of a (univariate) probability distribution is the same as that of a random variable having that distribution. Not all random variables have a standard deviation, since these expected values need not exist. For example, the standard deviation of a random variable that follows a Cauchy distribution is undefined because its expected value μ is undefined.
Discrete random variable
In the case where X takes random values from a finite data set x1, x2, ..., xN, with each value having the same probability, the standard deviation is
![\sigma ={\sqrt {{\frac {1}{N}}\left[(x_{1}-\mu )^{2}+(x_{2}-\mu )^{2}+\cdots +(x_{N}-\mu )^{2}\right]}},{{\rm {\ \ where\ \ }}}\mu ={\frac {1}{N}}(x_{1}+\cdots +x_{N}),](/2014-wikipedia_en_all_02_2014/I/media/3/1/8/3/31830fa1f2f922edf6079209a51f8967.png)
or, using summation notation,
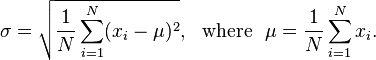
If, instead of having equal probabilities, the values have different probabilities, let x1 have probability p1, x2 have probability p2, ..., xN have probability pN. In this case, the standard deviation will be

Continuous random variable
The standard deviation of a continuous real-valued random variable X with probability density function p(x) is

and where the integrals are definite integrals taken for x ranging over the set of possible values of the random variable X.
In the case of a parametric family of distributions, the standard deviation can be expressed in terms of the parameters. For example, in the case of the log-normal distribution with parameters μ and σ2, the standard deviation is [(exp(σ2) − 1)exp(2μ + σ2)]1/2.
Estimation
One can find the standard deviation of an entire population in cases (such as standardized testing) where every member of a population is sampled. In cases where that cannot be done, the standard deviation σ is estimated by examining a random sample taken from the population and computing a statistic of the sample, which is used as an estimate of the population standard deviation. Such a statistic is called an estimator, and the estimator (or the value of the estimator, namely the estimate) is called a sample standard deviation, and is denoted by s (possibly with modifiers). However, unlike in the case of estimating the population mean, for which the sample mean is a simple estimator with many desirable properties (unbiased, efficient, maximum likelihood), there is no single estimator for the standard deviation with all these properties, and unbiased estimation of standard deviation is a very technical involved problem. Most often, the standard deviation is estimated using the corrected sample standard deviation (using N − 1), defined below, and this is often referred to as the "sample standard deviation", without qualifiers. However, other estimators are better in other respects: the uncorrected estimator (using N) yields lower mean squared error, while using N − 1.5 (for the normal distribution) almost completely eliminates bias.
Uncorrected sample standard deviation
Firstly, the formula for the population standard deviation (of a finite population) can be applied to the sample, using the size of the sample as the size of the population (though the actual population size from which the sample is drawn may be much larger). This estimator, denoted by sN, is known as the uncorrected sample standard deviation, or sometimes the standard deviation of the sample (considered as the entire population), and is defined as follows:[citation needed]
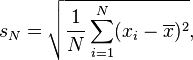
where  are the observed values of the sample items and
are the observed values of the sample items and  is the mean value of these observations, while the denominator N stands for the size of the sample.
is the mean value of these observations, while the denominator N stands for the size of the sample.
This is a consistent estimator (it converges in probability to the population value as the number of samples goes to infinity), and is the maximum-likelihood estimate when the population is normally distributed.[citation needed] However, this is a biased estimator, as the estimates are generally too low. The bias decreases as sample size grows, dropping off as 1/n, and thus is most significant for small or moderate sample sizes; for 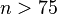 the bias is below 1%. Thus for very large sample sizes, the uncorrected sample standard deviation is generally acceptable. This estimator also has a uniformly smaller mean squared error than the corrected sample standard deviation.
the bias is below 1%. Thus for very large sample sizes, the uncorrected sample standard deviation is generally acceptable. This estimator also has a uniformly smaller mean squared error than the corrected sample standard deviation.
Corrected sample standard deviation
When discussing the bias, to be more precise, the corresponding estimator for the variance, the biased sample variance:
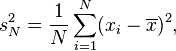
equivalently the second central moment of the sample (as the mean is the first moment), is a biased estimator of the variance (it underestimates the population variance). Taking the square root to pass to the standard deviation introduces further downward bias, by Jensen's inequality, due to the square root being a concave function. The bias in the variance is easily corrected, but the bias from the square root is more difficult to correct, and depends on the distribution in question.
An unbiased estimator for the variance is given by applying Bessel's correction, using N − 1 instead of N to yield the unbiased sample variance, denoted s2:
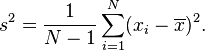
This estimator is unbiased if the variance exists and the sample values are drawn independently with replacement. N − 1 corresponds to the number of degrees of freedom in the vector of residuals, 
Taking square roots reintroduces bias, and yields the corrected sample standard deviation, denoted by s:
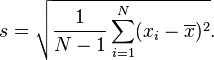
While s2 is an unbiased estimator for the population variance, s is a biased estimator for the population standard deviation, though markedly less biased than the uncorrected sample standard deviation. The bias is still significant for small samples (n less than 10), and also drops off as 1/n as sample size increases. This estimator is commonly used, and generally known simply as the "sample standard deviation".
Unbiased sample standard deviation
For unbiased estimation of standard deviation, there is no formula that works across all distributions, unlike for mean and variance. Instead, s is used as a basis, and is scaled by a correction factor to produce an unbiased estimate. For the normal distribution, an unbiased estimator is given by s/c4, where the correction factor (which depends on N) is given in terms of the Gamma function, and equals:
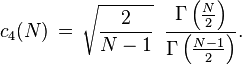
This arises because the sampling distribution of the sample standard deviation follows a (scaled) chi distribution, and the correction factor is the mean of the chi distribution.
An approximation is given by replacing N − 1 with N − 1.5, yielding:
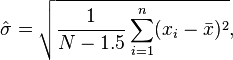
The error in this approximation decays quadratically (as 1/N2), and it is suited for all but the smallest samples or highest precision: for n = 3 the bias is equal to 1.3%, and for n = 9 the bias is already less than 0.1%.
For other distributions, the correct formula depends on the distribution, but a rule of thumb is to use the further refinement of the approximation:
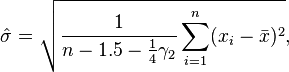
where γ2 denotes the population excess kurtosis. The excess kurtosis may be either known beforehand for certain distributions, or estimated from the data.
Confidence interval of a sampled standard deviation
The standard deviation we obtain by sampling a distribution is itself not absolutely accurate, both for mathematical reasons (explained here by the confidence interval) and for practical reasons of measurement (measurement error). The mathematical effect can be described by the confidence interval or CI. To show how a larger sample will increase the confidence interval, consider the following examples: For a small population of N=2, the 95% CI of the SD is from 0.45*SD to 31.9*SD. In other words, the standard deviation of the distribution in 95% of the cases can be larger by a factor of 31 or smaller by a factor of 2. For a larger population of N=10, the CI is 0.69*SD to 1.83*SD. So even with a sample population of 10, the actual SD can still be almost a factor 2 higher than the sampled SD. For a sample population N=100, this is down to 0.88*SD to 1.16*SD. To be more certain that the sampled SD is close to the actual SD we need to sample a large number of points.
Identities and mathematical properties
The standard deviation is invariant under changes in location, and scales directly with the scale of the random variable. Thus, for a constant c and random variables X and Y:
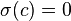

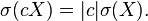
The standard deviation of the sum of two random variables can be related to their individual standard deviations and the covariance between them:

where  and
and  stand for variance and covariance, respectively.
stand for variance and covariance, respectively.
The calculation of the sum of squared deviations can be related to moments calculated directly from the data. The standard deviation of the sample can be computed as:
![\sigma (X)={\sqrt {E[(X-E(X))^{2}]}}={\sqrt {E[X^{2}]-(E[X])^{2}}}.](/2014-wikipedia_en_all_02_2014/I/media/2/9/d/e/29decca908054bca1bbabdcf6db0afaf.png)
The sample standard deviation can be computed as:
![\sigma (X)={\sqrt {{\frac {N}{N-1}}}}{\sqrt {E[(X-E(X))^{2}]}}.](/2014-wikipedia_en_all_02_2014/I/media/7/8/1/9/7819ea2d08e6cbf7d244bb20aa100f42.png)
For a finite population with equal probabilities at all points, we have
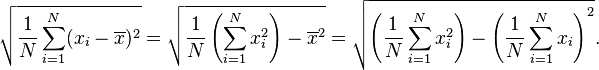
This means that the standard deviation is equal to the square root of (the average of the squares less the square of the average). See computational formula for the variance for proof, and for an analogous result for the sample standard deviation.
Interpretation and application

A large standard deviation indicates that the data points are far from the mean and a small standard deviation indicates that they are clustered closely around the mean.
For example, each of the three populations {0, 0, 14, 14}, {0, 6, 8, 14} and {6, 6, 8, 8} has a mean of 7. Their standard deviations are 7, 5, and 1, respectively. The third population has a much smaller standard deviation than the other two because its values are all close to 7. It will have the same units as the data points themselves. If, for instance, the data set {0, 6, 8, 14} represents the ages of a population of four siblings in years, the standard deviation is 5 years. As another example, the population {1000, 1006, 1008, 1014} may represent the distances traveled by four athletes, measured in meters. It has a mean of 1007 meters, and a standard deviation of 5 meters.
Standard deviation may serve as a measure of uncertainty. In physical science, for example, the reported standard deviation of a group of repeated measurements gives the precision of those measurements. When deciding whether measurements agree with a theoretical prediction, the standard deviation of those measurements is of crucial importance: if the mean of the measurements is too far away from the prediction (with the distance measured in standard deviations), then the theory being tested probably needs to be revised. This makes sense since they fall outside the range of values that could reasonably be expected to occur, if the prediction were correct and the standard deviation appropriately quantified. See prediction interval.
While the standard deviation does measure how far typical values tend to be from the mean, other measures are available. An example is the mean absolute deviation, which might be considered a more direct measure of average distance, compared to the root mean square distance inherent in the standard deviation.
Application examples
The practical value of understanding the standard deviation of a set of values is in appreciating how much variation there is from the average (mean).
Climate
As a simple example, consider the average daily maximum temperatures for two cities, one inland and one on the coast. It is helpful to understand that the range of daily maximum temperatures for cities near the coast is smaller than for cities inland. Thus, while these two cities may each have the same average maximum temperature, the standard deviation of the daily maximum temperature for the coastal city will be less than that of the inland city as, on any particular day, the actual maximum temperature is more likely to be farther from the average maximum temperature for the inland city than for the coastal one.
Particle physics
Particle physics uses a standard of "5 sigma" for the declaration of a discovery.[4] At five-sigma there is only one chance in nearly two million that a random fluctuation would yield the result. This level of certainty prompted the announcement that a particle consistent with the Higgs boson has been discovered in two independent experiments at CERN.[5]
Finance
In finance, standard deviation is often used as a measure of the risk associated with price-fluctuations of a given asset (stocks, bonds, property, etc.), or the risk of a portfolio of assets [6] (actively managed mutual funds, index mutual funds, or ETFs). Risk is an important factor in determining how to efficiently manage a portfolio of investments because it determines the variation in returns on the asset and/or portfolio and gives investors a mathematical basis for investment decisions (known as mean-variance optimization). The fundamental concept of risk is that as it increases, the expected return on an investment should increase as well, an increase known as the risk premium. In other words, investors should expect a higher return on an investment when that investment carries a higher level of risk or uncertainty. When evaluating investments, investors should estimate both the expected return and the uncertainty of future returns. Standard deviation provides a quantified estimate of the uncertainty of future returns.
For example, let's assume an investor had to choose between two stocks. Stock A over the past 20 years had an average return of 10 percent, with a standard deviation of 20 percentage points (pp) and Stock B, over the same period, had average returns of 12 percent but a higher standard deviation of 30 pp. On the basis of risk and return, an investor may decide that Stock A is the safer choice, because Stock B's additional two percentage points of return is not worth the additional 10 pp standard deviation (greater risk or uncertainty of the expected return). Stock B is likely to fall short of the initial investment (but also to exceed the initial investment) more often than Stock A under the same circumstances, and is estimated to return only two percent more on average. In this example, Stock A is expected to earn about 10 percent, plus or minus 20 pp (a range of 30 percent to −10 percent), about two-thirds of the future year returns. When considering more extreme possible returns or outcomes in future, an investor should expect results of as much as 10 percent plus or minus 60 pp, or a range from 70 percent to −50 percent, which includes outcomes for three standard deviations from the average return (about 99.7 percent of probable returns).
Calculating the average (or arithmetic mean) of the return of a security over a given period will generate the expected return of the asset. For each period, subtracting the expected return from the actual return results in the difference from the mean. Squaring the difference in each period and taking the average gives the overall variance of the return of the asset. The larger the variance, the greater risk the security carries. Finding the square root of this variance will give the standard deviation of the investment tool in question.
Population standard deviation is used to set the width of Bollinger Bands, a widely adopted technical analysis tool. For example, the upper Bollinger Band is given as x + nσx. The most commonly used value for n is 2; there is about a five percent chance of going outside, assuming a normal distribution of returns.
Unfortunately, financial time series are known to be non-stationary series, whereas the statistical calculations above, such as standard deviation, apply only to stationary series. Whatever apparent "predictive powers" or "forecasting ability" that may appear when applied as above is illusory. To apply the above statistical tools to non-stationary series, the series first must be transformed to a stationary series, enabling use of statistical tools that now have a valid basis from which to work.
Geometric interpretation
| It is requested that a diagram or diagrams be included in this article to improve its quality. Specific illustrations, plots or diagrams can be requested at the Graphic Lab. For more information, refer to discussion on this page and/or the listing at Wikipedia:Requested images. |
To gain some geometric insights and clarification, we will start with a population of three values, x1, x2, x3. This defines a point P = (x1, x2, x3) in R3. Consider the line L = {(r, r, r) : r ∈ R}. This is the "main diagonal" going through the origin. If our three given values were all equal, then the standard deviation would be zero and P would lie on L. So it is not unreasonable to assume that the standard deviation is related to the distance of P to L. And that is indeed the case. To move orthogonally from L to the point P, one begins at the point:

whose coordinates are the mean of the values we started out with. A little algebra shows that the distance between P and M (which is the same as the orthogonal distance between P and the line L) is equal to the standard deviation of the vector x1, x2, x3, multiplied by the square root of the number of dimensions of the vector (3 in this case.)
Chebyshev's inequality
An observation is rarely more than a few standard deviations away from the mean. Chebyshev's inequality ensures that, for all distributions for which the standard deviation is defined, the amount of data within a number of standard deviations of the mean is at least as much as given in the following table.
| Minimum population | Distance from mean |
|---|---|
| 50% | √2 |
| 75% | 2 |
| 89% | 3 |
| 94% | 4 |
| 96% | 5 |
| 97% | 6 |
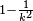 [7] [7] |  |
 |  |
Rules for normally distributed data
The central limit theorem says that the distribution of an average of many independent, identically distributed random variables tends toward the famous bell-shaped normal distribution with a probability density function of:

where μ is the expected value of the random variables, σ equals their distribution's standard deviation divided by n1/2, and n is the number of random variables. The standard deviation therefore is simply a scaling variable that adjusts how broad the curve will be, though it also appears in the normalizing constant.
If a data distribution is approximately normal, then the proportion of data values within z standard deviations of the mean is defined by:
- Proportion =

where 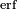 is the error function. If a data distribution is approximately normal then about 68 percent of the data values are within one standard deviation of the mean (mathematically, μ ± σ, where μ is the arithmetic mean), about 95 percent are within two standard deviations (μ ± 2σ), and about 99.7 percent lie within three standard deviations (μ ± 3σ). This is known as the 68-95-99.7 rule, or the empirical rule.
is the error function. If a data distribution is approximately normal then about 68 percent of the data values are within one standard deviation of the mean (mathematically, μ ± σ, where μ is the arithmetic mean), about 95 percent are within two standard deviations (μ ± 2σ), and about 99.7 percent lie within three standard deviations (μ ± 3σ). This is known as the 68-95-99.7 rule, or the empirical rule.
For various values of z, the percentage of values expected to lie in and outside the symmetric interval, CI = (−zσ, zσ), are as follows:
| zσ | Percentage within CI | Percentage outside CI | Fraction outside CI |
|---|---|---|---|
| 0.674490σ | 50% | 50% | 1 / 2 |
| 0.994458σ | 68% | 32% | 1 / 3.125 |
| 1σ | 68.2689492% | 31.7310508% | 1 / 3.1514872 |
| 1.281552σ | 80% | 20% | 1 / 5 |
| 1.644854σ | 90% | 10% | 1 / 10 |
| 1.959964σ | 95% | 5% | 1 / 20 |
| 2σ | 95.4499736% | 4.5500264% | 1 / 21.977895 |
| 2.575829σ | 99% | 1% | 1 / 100 |
| 3σ | 99.7300204% | 0.2699796% | 1 / 370.398 |
| 3.290527σ | 99.9% | 0.1% | 1 / 1000 |
| 3.890592σ | 99.99% | 0.01% | 1 / 10000 |
| 4σ | 99.993666% | 0.006334% | 1 / 15787 |
| 4.417173σ | 99.999% | 0.001% | 1 / 100000 |
| 4.5σ | 99.9993204653751% | 0.0006795346249% | 3.4 / 1000000 (on each side of mean) |
| 4.891638σ | 99.9999% | 0.0001% | 1 / 1000000 |
| 5σ | 99.9999426697% | 0.0000573303% | 1 / 1744278 |
| 5.326724σ | 99.99999% | 0.00001% | 1 / 10000000 |
| 5.730729σ | 99.999999% | 0.000001% | 1 / 100000000 |
| 6σ | 99.9999998027% | 0.0000001973% | 1 / 506797346 |
| 6.109410σ | 99.9999999% | 0.0000001% | 1 / 1000000000 |
| 6.466951σ | 99.99999999% | 0.00000001% | 1 / 10000000000 |
| 6.806502σ | 99.999999999% | 0.000000001% | 1 / 100000000000 |
| 7σ | 99.9999999997440% | 0.000000000256% | 1 / 390682215445 |
Relationship between standard deviation and mean
The mean and the standard deviation of a set of data are descriptive statistics usually reported together. In a certain sense, the standard deviation is a "natural" measure of statistical dispersion if the center of the data is measured about the mean. This is because the standard deviation from the mean is smaller than from any other point. The precise statement is the following: suppose x1, ..., xn are real numbers and define the function:

Using calculus or by completing the square, it is possible to show that σ(r) has a unique minimum at the mean:
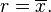
Variability can also be measured by the coefficient of variation, which is the ratio of the standard deviation to the mean. It is a dimensionless number.
Standard deviation of the mean
Often, we want some information about the precision of the mean we obtained. We can obtain this by determining the standard deviation of the sampled mean. Assuming statistical independence of the values in the sample, the standard deviation of the mean is related to the standard deviation of the distribution by:

where N is the number of observations in the sample used to estimate the mean. This can easily be proven with (see basic properties of the variance):
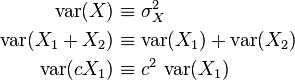
hence

Resulting in:
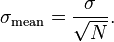
It should be emphasized that in order to estimate standard deviation of the mean  it is necessary to know standard deviation of the entire population
it is necessary to know standard deviation of the entire population 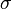 beforehand. However, in most applications this parameter is unknown. For example, if series of 10 measurements of previously unknown quantity is performed in laboratory, it is possible to calculate resulting sample mean and sample standard deviation, but it is impossible to calculate standard deviation of the mean.
beforehand. However, in most applications this parameter is unknown. For example, if series of 10 measurements of previously unknown quantity is performed in laboratory, it is possible to calculate resulting sample mean and sample standard deviation, but it is impossible to calculate standard deviation of the mean.
Rapid calculation methods
The following two formulas can represent a running (repeatedly updated) standard deviation. A set of two power sums s1 and s2 are computed over a set of N values of x, denoted as x1, ..., xN:

Given the results of these running summations, the values N, s1, s2 can be used at any time to compute the current value of the running standard deviation:
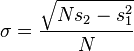
Where :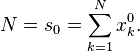
Similarly for sample standard deviation,
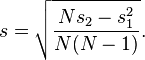
In a computer implementation, as the three sj sums become large, we need to consider round-off error, arithmetic overflow, and arithmetic underflow. The method below calculates the running sums method with reduced rounding errors.[8] This is a "one pass" algorithm for calculating variance of n samples without the need to store prior data during the calculation. Applying this method to a time series will result in successive values of standard deviation corresponding to n data points as n grows larger with each new sample, rather than a constant-width sliding window calculation.
For k = 1, ..., n:
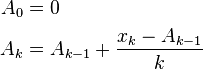
where A is the mean value.

Note: 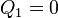 since
since  or
or 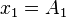
Sample variance:
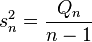
Population variance:

Weighted calculation
When the values xi are weighted with unequal weights wi, the power sums s0, s1, s2 are each computed as:
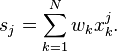
And the standard deviation equations remain unchanged. Note that s0 is now the sum of the weights and not the number of samples N.
The incremental method with reduced rounding errors can also be applied, with some additional complexity.
A running sum of weights must be computed for each k from 1 to n:
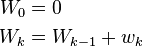
and places where 1/n is used above must be replaced by wi/Wn:

In the final division,
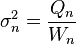
and
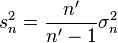
where n is the total number of elements, and n' is the number of elements with non-zero weights. The above formulas become equal to the simpler formulas given above if weights are taken as equal to one.
Combining standard deviations
Population-based statistics
The populations of sets, which may overlap, can be calculated simply as follows:

Standard deviations of non-overlapping (X ∩ Y = ∅) sub-populations can be aggregated as follows if the size (actual or relative to one another) and means of each are known:
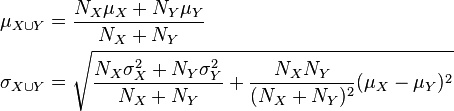
For example, suppose it is known that the average American man has a mean height of 70 inches with a standard deviation of three inches and that the average American woman has a mean height of 65 inches with a standard deviation of two inches. Also assume that the number of men, N, is equal to the number of women. Then the mean and standard deviation of heights of American adults could be calculated as:
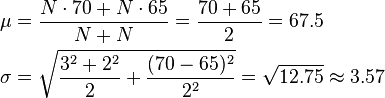
For the more general case of M non-overlapping populations, X1 through XM, and the aggregate population 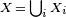 :
:
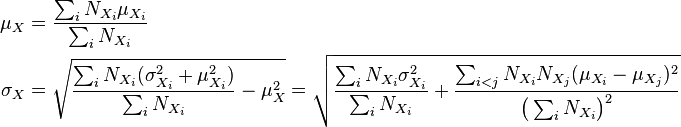
where
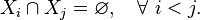
If the size (actual or relative to one another), mean, and standard deviation of two overlapping populations are known for the populations as well as their intersection, then the standard deviation of the overall population can still be calculated as follows:
![{\begin{aligned}\mu _{{X\cup Y}}&={\frac {1}{N_{{X\cup Y}}}}\left(N_{X}\mu _{X}+N_{Y}\mu _{Y}-N_{{X\cap Y}}\mu _{{X\cap Y}}\right)\\\sigma _{{X\cup Y}}&={\sqrt {{\frac {1}{N_{{X\cup Y}}}}\left(N_{X}[\sigma _{X}^{2}+\mu _{X}^{2}]+N_{Y}[\sigma _{Y}^{2}+\mu _{Y}^{2}]-N_{{X\cap Y}}[\sigma _{{X\cap Y}}^{2}+\mu _{{X\cap Y}}^{2}]\right)-\mu _{{X\cup Y}}^{2}}}\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/d/f/b/f/dfbfeabd367bd1e8a84bce1baf6d3fd7.png)
If two or more sets of data are being added together datapoint by datapoint, the standard deviation of the result can be calculated if the standard deviation of each data set and the covariance between each pair of data sets is known:

For the special case where no correlation exists between any pair of data sets, then the relation reduces to the root-mean-square:
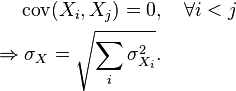
Sample-based statistics
Standard deviations of non-overlapping (X ∩ Y = ∅) sub-samples can be aggregated as follows if the actual size and means of each are known:
![{\begin{aligned}\mu _{{X\cup Y}}&={\frac {1}{N_{{X\cup Y}}}}\left(N_{X}\mu _{X}+N_{Y}\mu _{Y}\right)\\\sigma _{{X\cup Y}}&={\sqrt {{\frac {1}{N_{{X\cup Y}}-1}}\left([N_{X}-1]\sigma _{X}^{2}+N_{X}\mu _{X}^{2}+[N_{Y}-1]\sigma _{Y}^{2}+N_{Y}\mu _{Y}^{2}-[N_{X}+N_{Y}]\mu _{{X\cup Y}}^{2}\right)}}\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/7/5/5/b/755b6644b38e95d5e77a35786ca73079.png)
For the more general case of M non-overlapping data sets, X1 through XM, and the aggregate data set :
![{\begin{aligned}\mu _{X}&={\frac {1}{\sum _{i}{N_{{X_{i}}}}}}\left(\sum _{i}{N_{{X_{i}}}\mu _{{X_{i}}}}\right)\\\sigma _{X}&={\sqrt {{\frac {1}{\sum _{i}{N_{{X_{i}}}-1}}}\left(\sum _{i}{\left[(N_{{X_{i}}}-1)\sigma _{{X_{i}}}^{2}+N_{{X_{i}}}\mu _{{X_{i}}}^{2}\right]}-\left[\sum _{i}{N_{{X_{i}}}}\right]\mu _{X}^{2}\right)}}\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/8/4/3/2/8432914c7d3c1734e55daf3cbbe0365d.png)
where:

If the size, mean, and standard deviation of two overlapping samples are known for the samples as well as their intersection, then the standard deviation of the aggregated sample can still be calculated. In general:
![{\begin{aligned}\mu _{{X\cup Y}}&={\frac {1}{N_{{X\cup Y}}}}\left(N_{X}\mu _{X}+N_{Y}\mu _{Y}-N_{{X\cap Y}}\mu _{{X\cap Y}}\right)\\\sigma _{{X\cup Y}}&={\sqrt {{\frac {[N_{X}-1]\sigma _{X}^{2}+N_{X}\mu _{X}^{2}+[N_{Y}-1]\sigma _{Y}^{2}+N_{Y}\mu _{Y}^{2}-[N_{{X\cap Y}}-1]\sigma _{{X\cap Y}}^{2}-N_{{X\cap Y}}\mu _{{X\cap Y}}^{2}-[N_{X}+N_{Y}-N_{{X\cap Y}}]\mu _{{X\cup Y}}^{2}}{N_{{X\cup Y}}-1}}}}\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/1/e/c/8/1ec86704f0678b560eb5474125d27f15.png)
History
The term standard deviation was first used[9] in writing by Karl Pearson[10] in 1894, following his use of it in lectures. This was as a replacement for earlier alternative names for the same idea: for example, Gauss used mean error.[11] It may be worth noting in passing that the mean error is mathematically distinct from the standard deviation.
See also
- Accuracy and precision
- Chebyshev's inequality An inequality on location and scale parameters
- Cumulant
- Deviation (statistics)
- Distance correlation Distance standard deviation
- Error bar
- Geometric standard deviation
- Mahalanobis distance generalizing number of standard deviations to the mean
- Mean absolute error
- Percentile
- Pooled variance pooled standard deviation
- Raw score
- Robust standard deviation
- Root mean square
- Sample size
- Samuelson's inequality
- Six Sigma
- Standard error
- Volatility (finance)
- Yamartino method for calculating standard deviation of wind direction
References
- ↑ Bland, J.M.; Altman, D.G. (1996). "Statistics notes: measurement error.". Bmj, 312(7047), 1654. Retrieved 22 November 2013.
- ↑ Gauss, Carl Friedrich (1816). "Bestimmung der Genauigkeit der Beobachtungen". Zeitschrift für Astronomie und verwandt Wissenschaften 1: 187–197.
- ↑ Walker, Helen (1931). Studies in the History of the Statistical Method. Baltimore, MD: Williams & Wilkins Co. pp. 24–25.
- ↑ "CERN | Accelerating science". Public.web.cern.ch. Retrieved 2013-08-10.
- ↑ "CERN experiments observe particle consistent with long-sought Higgs boson | CERN press office". Press.web.cern.ch. 2012-07-04. Retrieved 2013-08-10.
- ↑ "What is Standard Deviation". Pristine. Retrieved 2011-10-29.
- ↑ Ghahramani, Saeed (2000). Fundamentals of Probability (2nd Edition). Prentice Hall: New Jersey. p. 438.
- ↑ Welford, BP (August 1962). "Note on a Method for Calculating Corrected Sums of Squares and Products". Technometrics 4 (3): 419–420.
- ↑ Dodge, Yadolah (2003). The Oxford Dictionary of Statistical Terms. Oxford University Press. ISBN 0-19-920613-9.
- ↑ Pearson, Karl (1894). "On the dissection of asymmetrical frequency curves". Philosophical Transactions of the Royal Society A 185: 719–810.
- ↑ Miller, Jeff. "Earliest Known Uses of Some of the Words of Mathematics".
External links
- Hazewinkel, Michiel, ed. (2001), "Quadratic deviation", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- A simple way to understand Standard Deviation
- Standard Deviation – an explanation without maths
- Standard Deviation, an elementary introduction
- Standard Deviation while Financial Modeling in Excel
- Standard Deviation, a simpler explanation for writers and journalists
- The concept of Standard Deviation is shown in this 8-foot-tall (2.4 m) Probability Machine (named Sir Francis) comparing stock market returns to the randomness of the beans dropping through the quincunx pattern. from Index Funds Advisors IFA.com
| ||||||||||||||||||||||||||||||||||||||