Snowflake schema
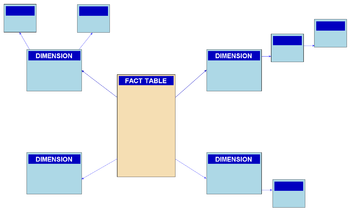
In computing, a snowflake schema is a logical arrangement of tables in a multidimensional database such that the entity relationship diagram resembles a snowflake in shape. The snowflake schema is represented by centralized fact tables which are connected to multiple dimensions.[citation needed]. "Snowflaking" is a method of normalising the dimension tables in a star schema. When it is completely normalised along all the dimension tables, the resultant structure resembles a snowflake with the fact table in the middle. The principle behind snowflaking is normalisation of the dimension tables by removing low cardinality attributes and forming separate tables.[1]
The snowflake schema is similar to the star schema. However, in the snowflake schema, dimensions are normalized into multiple related tables, whereas the star schema's dimensions are denormalized with each dimension represented by a single table. A complex snowflake shape emerges when the dimensions of a snowflake schema are elaborate, having multiple levels of relationships, and the child tables have multiple parent tables ("forks in the road").
Common uses
Star and snowflake schemas are most commonly found in dimensional data warehouses and data marts where speed of data retrieval is more important than the efficiency of data manipulations. As such, the tables in these schemas are not normalized much, and are frequently designed at a level of normalization short of third normal form.[citation needed]
Deciding whether to employ a star schema or a snowflake schema should involve considering the relative strengths of the database platform in question and the query tool to be employed. Star schemas should be favored with query tools that largely expose users to the underlying table structures, and in environments where most queries are simpler in nature. Snowflake schemas are often better with more sophisticated query tools that create a layer of abstraction between the users and raw table structures for environments having numerous queries with complex criteria.[citation needed]
Data normalization and storage
Normalization splits up data to avoid redundancy (duplication) by moving commonly repeating groups of data into new tables. Normalization therefore tends to increase the number of tables that need to be joined in order to perform a given query, but reduces the space required to hold the data and the number of places where it needs to be updated if the data changes.[citation needed]
From a space storage point of view, the dimensional tables are typically small compared to the fact tables. This often removes the storage space benefit of snowflaking the dimension tables, as compared with a star schema.[citation needed]
Some database developers compromise by creating an underlying snowflake schema with views built on top of it that perform many of the necessary joins to simulate a star schema. This provides the storage benefits achieved through the normalization of dimensions with the ease of querying that the star schema provides. The tradeoff is that requiring the server to perform the underlying joins automatically can result in a performance hit when querying as well as extra joins to tables that may not be necessary to fulfill certain queries.[citation needed]
Benefits
The snowflake schema is in the same family as the star schema logical model. In fact, the star schema is considered a special case of the snowflake schema. The snowflake schema provides some advantages over the star schema in certain situations, including:
- Some OLAP multidimensional database modeling tools are optimized for snowflake schemas.[2]
- Normalizing attributes results in storage savings, the tradeoff being additional complexity in source query joins.
Disadvantages
The primary disadvantage of the snowflake schema is that the additional levels of attribute normalization adds complexity to source query joins, when compared to the star schema. When compared to a highly normalized transactional schema, the snowflake schema's denormalization removes the data integrity assurances provided by normalized schemas. Data loads into the snowflake schema must be highly controlled and managed to avoid update and insert anomalies.
Examples

The example schema shown to the right is a snowflaked version of the star schema example provided in the star schema article.[citation needed]
The following example query is the snowflake schema equivalent of the star schema example code which returns the total number of units sold by brand and by country for 1997. Notice that the snowflake schema query requires many more joins than the star schema version in order to fulfill even a simple query. The benefit of using the snowflake schema in this example is that the storage requirements are lower since the snowflake schema eliminates many duplicate values from the dimensions themselves.[citation needed]
SELECT B.Brand, G.Country, SUM(F.Units_Sold) FROM Fact_Sales F INNER JOIN Dim_Date D ON F.Date_Id = D.Id INNER JOIN Dim_Store S ON F.Store_Id = S.Id INNER JOIN Dim_Geography G ON S.Geography_Id = G.Id INNER JOIN Dim_Product P ON F.Product_Id = P.Id INNER JOIN Dim_Brand B ON P.Brand_Id = B.Id INNER JOIN Dim_Product_Category C ON P.Product_Category_Id = C.Id WHERE D.YEAR = 1997 AND C.Product_Category = 'tv' GROUP BY B.Brand, G.Country
See also
- Star schema
- Data Warehouse
- OLAP
References
- ↑ Paulraj Ponniah. Data Warehousing Fundamentals for IT Professionals. Wiley, 2010, pp. 29–32. ISBN 0470462078.
- ↑ Wilkie, Michelle (2009). "Using SAS® OLAP Server for a ROLAP Scenario". SAS Global Forum 2009. Retrieved 2013-02-27.
Paulraj Ponniah. Data Warehousing Fundamentals for IT Professionals. Wiley, 2010, pp. 29–32. ISBN 0470462078.
Bibliography
- Anahory, S.; D. Murray. Data Warehousing in the Real World: A Practical Guide for Building Decision Support Systems. Addison Wesley Professional.
- Kimball, Ralph (1996). The Data Warehousing Toolkit. John Wiley.
External links
- "Why is the Snowflake Schema a Good Data Warehouse Design?" by Mark Levene and George Loizou
- Reverse Snowflake Joins