Simple random sample
In statistics, a simple random sample is a subset of individuals (a sample) chosen from a larger set (a population). Each individual is chosen randomly and entirely by chance, such that each individual has the same probability of being chosen at any stage during the sampling process, and each subset of k individuals has the same probability of being chosen for the sample as any other subset of k individuals.[1] This process and technique is known as simple random sampling, and should not be confused with systematic random sampling. A simple random sample is an unbiased surveying technique.
Simple random sampling is a basic type of sampling, since it can be a component of other more complex sampling methods. The principle of simple random sampling is that every object has the same probability of being chosen. For example, suppose N college students want to get a ticket for a basketball game, but there are only X < N tickets for them, so they decide to have a fair way to see who gets to go. Then, everybody is given a number in the range from 0 to N-1, and random numbers are generated, either electronically or from a table of random numbers. Numbers outside the range from 0 to N-1 are ignored, as are any numbers previously selected. The first X numbers would identify the lucky ticket winners.
In small populations and often in large ones, such sampling is typically done "without replacement", i.e., one deliberately avoids choosing any member of the population more than once. Although simple random sampling can be conducted with replacement instead, this is less common and would normally be described more fully as simple random sampling with replacement. Sampling done without replacement is no longer independent, but still satisfies exchangeability, hence many results still hold. Further, for a small sample from a large population, sampling without replacement is approximately the same as sampling with replacement, since the odds of choosing the same individual twice is low.
An unbiased random selection of individuals is important so that if a large number of samples were drawn, the average sample would accurately represent the population. However, this does not guarantee that a particular sample is a perfect representation of the population. Simple random sampling merely allows one to draw externally valid conclusions about the entire population based on the sample.
Conceptually, simple random sampling is the simplest of the probability sampling techniques. It requires a complete sampling frame, which may not be available or feasible to construct for large populations. Even if a complete frame is available, more efficient approaches may be possible if other useful information is available about the units in the population.
Advantages are that it is free of classification error, and it requires minimum advance knowledge of the population other than the frame. Its simplicity also makes it relatively easy to interpret data collected in this manner. For these reasons, simple random sampling best suits situations where not much information is available about the population and data collection can be efficiently conducted on randomly distributed items, or where the cost of sampling is small enough to make efficiency less important than simplicity. If these conditions do not hold, stratified sampling or cluster sampling may be a better choice.
Distinction between a systematic random sample and a simple random sample
Consider a school with 1000 students, divided equally into boys and girls, and suppose that a researcher wants to select 100 of them for further study. All their names might be put in a bucket and then 100 names might be pulled out. Not only does each person have an equal chance of being selected, we can also easily calculate the probability P of a given person being chosen, since we know the sample size (n) and the population (N):
1. In the case that any given person can only be selected once (i.e., after selection a person is removed from the selection pool):
Failed to parse(syntax error): P &= 1 - \frac{N-1}{N} \cdot \frac{N-2}{N - 1} \cdot \cdots \cdot \frac{N-n}{N - (n - 1)} \\ &\stackrel{Canceling}{=} 1 - \frac{N - n}N \\ &= \frac nN \\ &= \frac{100}{1000} \\ &= 10\%
2. In the case that any selected person is returned to the selection pool (i.e., can be picked more than once):
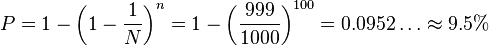
This means that every student in the school has in any case approximately a 1 in 10 chance of being selected using this method. Further, all combinations of 100 students have the same probability of selection.
If a systematic pattern is introduced into random sampling, it is referred to as "systematic (random) sampling". An example would be if the students in the school had numbers attached to their names ranging from 0001 to 1000, and we chose a random starting point, e.g. 0533, and then picked every 10th name thereafter to give us our sample of 100 (starting over with 0003 after reaching 0993). In this sense, this technique is similar to cluster sampling, since the choice of the first unit will determine the remainder. This is no longer simple random sampling, because some combinations of 100 students have a larger selection probability than others - for instance, {3, 13, 23, ..., 993} has a 1/10 chance of selection, while {1, 2, 3, ..., 100} cannot be selected under this method.
Sampling a dichotomous population
If the members of the population come in two kinds, say "red" and "black", the number of red elements in a sample of given size will vary by sample and hence is a random variable whose distribution can be studied. That distribution depends on the numbers of red and black elements in the full population. For a simple random sample with replacement, the distribution is a binomial distribution. For a simple random sample without replacement, one obtains a hypergeometric distribution.
See also
- Sampling (statistics)
- Probability Proportional to Size Sampling
- Reservoir sampling
- Marketing research
- Multistage sampling
- Nonprobability sampling
- Opinion poll
- Quantitative marketing research
References
Shiela Marie Trinidad