Sardinas–Patterson algorithm
In coding theory, the Sardinas–Patterson algorithm is a classical algorithm for determining in polynomial time whether a given variable-length code is uniquely decodable, named after August Albert Sardinas and George W. Patterson, who published it in 1953.[1] The algorithm carries out a systematic search for a string which admits two different decompositions into codewords. As Knuth reports, the algorithm was rediscovered about ten years later in 1963 by Floyd, despite the fact that it was at the time already well known in coding theory.[2]
Idea of the algorithm
Consider the code 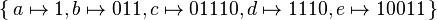 . This code, which is based on an example by Berstel,[3] is an example of a code which is not uniquely decodable, since the string
. This code, which is based on an example by Berstel,[3] is an example of a code which is not uniquely decodable, since the string
- 011101110011
can be interpreted as the sequence of codewords
- 01110 – 1110 – 011,
but also as the sequence of codewords
- 011 – 1 – 011 – 10011.
Two possible decodings of this encoded string are thus given by cdb and babe.
In general, a codeword can be found by the following idea: In the first round, we choose two codewords  and
and  such that is a prefix of , that is,
such that is a prefix of , that is,
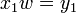 for some "dangling suffix"
for some "dangling suffix"  . If one tries first
. If one tries first  and
and 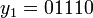 , the dangling suffix is
, the dangling suffix is 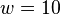 . If we manage to find two sequences
. If we manage to find two sequences  and
and 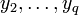 of codewords such that
of codewords such that
 , then we are finished: For then the string
, then we are finished: For then the string 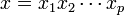 can alternatively be decomposed as
can alternatively be decomposed as  , and we have found the desired string having at least two different decompositions into codewords. In the second round, we try out two different approaches: the first trial is to look for a codeword that has w as prefix. Then we obtain a new dangling suffix w', with which we can continue our search. If we eventually encounter a dangling suffix that is itself a codeword (or the empty word), then the search will terminate, as we know there exists a string with two decompositions. The second trial is to seek for a codeword that is itself a prefix of w. In our example, we have , and the sequence 1 is a codeword. We can thus also continue with w'=0 as the new dangling suffix.
, and we have found the desired string having at least two different decompositions into codewords. In the second round, we try out two different approaches: the first trial is to look for a codeword that has w as prefix. Then we obtain a new dangling suffix w', with which we can continue our search. If we eventually encounter a dangling suffix that is itself a codeword (or the empty word), then the search will terminate, as we know there exists a string with two decompositions. The second trial is to seek for a codeword that is itself a prefix of w. In our example, we have , and the sequence 1 is a codeword. We can thus also continue with w'=0 as the new dangling suffix.
Precise description of the algorithm
The algorithm is described most conveniently using quotients of formal languages. In general, for two sets of strings D and N, the (left) quotient 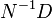 is defined as the residual words obtained from D by removing some prefix in N. Formally,
is defined as the residual words obtained from D by removing some prefix in N. Formally,  . Now let
. Now let  denote the (finite) set of codewords in the given code.
denote the (finite) set of codewords in the given code.
The algorithm proceeds in rounds, where we maintain in each round not only one dangling suffix as described above, but the (finite) set of all potential dangling suffixes. Starting with round  , the set of potential dangling suffixes will be denoted by
, the set of potential dangling suffixes will be denoted by  . The sets are defined inductively as follows:
. The sets are defined inductively as follows:
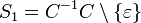 . Here, the symbol
. Here, the symbol  denotes the empty word.
denotes the empty word.
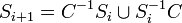 , for all
, for all  .
.
The algorithm computes the sets in increasing order of  . As soon as one of the contains a word from C or the empty word, then the algorithm terminates and answers that the given code is not uniquely decodable. Otherwise, once a set
equals a previously encountered set
. As soon as one of the contains a word from C or the empty word, then the algorithm terminates and answers that the given code is not uniquely decodable. Otherwise, once a set
equals a previously encountered set 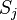 with
with  , then the algorithm would enter in principle an endless loop. Instead of continuing endlessly, it answers that the given code is uniquely decodable.
, then the algorithm would enter in principle an endless loop. Instead of continuing endlessly, it answers that the given code is uniquely decodable.
Termination and correctness of the algorithm
Since all sets are sets of suffixes of a finite set of codewords, there are only finitely many different candidates for . Since visiting one of the sets for the second time will cause the algorithm to stop, the algorithm cannot continue endlessly and thus must always terminate. More precisely, the total number of dangling suffixes that the algorithm considers is at most equal to the total of the lengths of the codewords in the input, so the algorithm runs in polynomial time as a function of this input length. By using a suffix tree to speed the comparison between each dangling suffix and the codewords, the time for the algorithm can be bounded by O(nk), where n is the total length of the codewords and k is the number of codewords.[4] The algorithm can also be implemented to run on a nondeterministic turing machine that uses only logarithmic space; the problem of testing unique decipherability is NL-complete, so this space bound is optimal.[5]
A proof that the algorithm is correct, i.e. that it always gives the correct answer, is found in the textbooks by Salomaa[6] and by Berstel et al.[7]
See also
- Kraft's inequality in some cases provides a quick way to exclude the possibility that a given code is uniquely decodable.
- Prefix codes and block codes are important classes of codes which are uniquely decodable by definition.
- Timeline of information theory
Notes
- ↑ Sardinas & Patterson (1953).
- ↑ Knuth (2003), p. 2
- ↑ Berstel et al. (2009), Example 2.3.1 p. 63
- ↑ Rodeh (1982).
- ↑ Rytter (1986) proves that the complementary problem, of testing for the existence of a string with two decodings, is NL-complete, and therefore that unique decipherability is co-NL-complete. The equivalence of NL-completeness and co-NL-completeness follows from the Immerman–Szelepcsényi theorem.
- ↑ Salomaa (1981)
- ↑ Berstel et al. (2009), Chapter 2.3
References
- Berstel, Jean; Perrin, Dominique; Reutenauer, Christophe (2010). Codes and automata. Encyclopedia of Mathematics and its Applications 129. Cambridge: Cambridge University Press. ISBN 978-0-521-88831-8. Zbl 1187.94001.
- Berstel, Jean; Reutenauer, Christophe (2011). Noncommutative rational series with applications. Encyclopedia of Mathematics and Its Applications 137. Cambridge: Cambridge University Press. ISBN 978-0-521-19022-0. Zbl 1250.68007.
- Knuth, Donald E. (December 2003). "Robert W Floyd, In Memoriam". SIGACT News 34 (4): 3–13.
- Rodeh, M. (1982). "A fast test for unique decipherability based on suffix trees (Corresp.)". IEEE Transactions on Information Theory 28 (4): 648–651. doi:10.1109/TIT.1982.1056535..
- Rytter, Wojciech (1986). "The space complexity of the unique decipherability problem". Information Processing Letters 23 (1): 1–3. doi:10.1016/0020-0190(86)90121-3. MR 853618..
- Salomaa, Arto (1981). Jewels of Formal Language Theory. Pitman Publishing. ISBN 0-273-08522-0. Zbl 0487.68064.
- Sardinas, August Albert; Patterson, George W. (1953). "A necessary and sufficient condition for the unique decomposition of coded messages". Convention Record of the I.R.E., 1953 National Convention, Part 8: Information Theory. pp. 104–108..
- Further reading
- Robert G. Gallager: Information Theory and Reliable Communication. Wiley, 1968