Sanov's theorem
In information theory, Sanov's theorem gives a bound on the probability of observing an atypical sequence of samples from a given probability distribution.
Let A be a set of probability distributions over an alphabet X, and let q be an arbitrary distribution over X (where q may or may not be in A). Suppose we draw n i.i.d. samples from q, represented by the vector  . Further, let us ask that the empirical distribution,
. Further, let us ask that the empirical distribution, 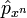 , of the samples falls within the set A -- formally, we write
, of the samples falls within the set A -- formally, we write  . Then,
. Then,
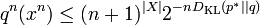 ,
,
where
-
 is shorthand for
is shorthand for  , and
, and -
 is the information projection of q onto A.
is the information projection of q onto A.
In words, the probability of drawing an atypical distribution is proportional to the KL distance from the true distribution to the atypical one; in the case that we consider a set of possible atypical distributions, there is a dominant atypical distribution, given by the information projection.
Furthermore, if A is a closed set,
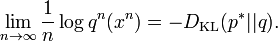
References
- Cover, Thomas M.; Thomas, Joy A. (2006). Elements of Information Theory (2 ed.). Hoboken, New Jersey: Wiley Interscience. p. 362.
- Sanov, I. N. (1957) "On the probability of large deviations of random variables". Mat. Sbornik 42, 11–44.