Rubin causal model
The Rubin causal model (RCM), also known as the Neyman–Rubin causal model,[1] is an approach to the statistical analysis of cause and effect based on the framework of potential outcomes, named after Donald Rubin. The name "Rubin causal model" was first coined by Rubin's graduate school colleague, Paul W. Holland.[2] The potential outcomes framework was first proposed by Jerzy Neyman in his 1923 Master's thesis,[3] though he discussed it only in the context of completely randomized experiments.[4] Rubin, together with other contemporary statisticians, extended it into a powerful general framework for thinking about causation in both observational and experimental studies.[1]
Introduction
The Neyman potential outcomes framework is based in the idea of potential outcomes and the assignment mechanism: every unit has different potential outcomes depending on their "assignment" to a condition.[1] Potential outcomes are expressed in the form of counterfactual conditional statements, which state what would be the case conditional on a prior event occurring. For instance, a person would have a particular income at age 40 if they had attended a private college, whereas they would have a different income at age 40 had they attended a public college. To measure the causal effect of going to a public versus a private college, the investigator should look at the outcome for the same individual in both alternative futures. Since it is impossible to see both potential outcomes at once, one of the potential outcomes is always missing. This observation is described as the "fundamental problem of causal inference". A randomized experiment works by assigning people randomly to treatments (in this case, public or private college). Because the assignment was random, the groups are (on average) equivalent, and the difference in income at age 40 can be attributed to the college assignment since that was the only difference between the groups. The assignment mechanism is the explanation for why some units received the treatment and others the control.
Rubin, together with a number of other contributors such as Cochran, developed this approach into a powerful formal framework for assessing causation in observational data.[1] In such data, there is a non-random assignment mechanism: in the case of college attendance, people may choose to attend a private versus a public college based on their financial situation, parents' education, relative ranks of the schools they were admitted to, etc. If all of these factors can be balanced between the two groups of public and private college students, then the effect of the college attendance can be attributed to the college choice.
Many statistical methods have been developed for causal inference, such as propensity score matching and nearest-neighbor matching (which often uses the Mahalanobis metric, also called Mahalanobis matching). These methods attempt to correct for the assignment mechanism by finding control units similar to treatment units. In the example, matching finds graduates of a public college most similar to graduates of a private college, so that like is compared only with like.
Causal inference methods make few assumptions other than that one unit's outcomes are unaffected by another unit's treatment assignment, the stable unit treatment value assumption (SUTVA).
An extended example
Rubin defines a causal effect:
Intuitively, the causal effect of one treatment, E, over another, C, for a particular unit and an interval of time from
to
is the difference between what would have happened at time
According to the RCM, the causal effect of your taking or not taking aspirin one hour ago is the difference between how your head would have felt in case 1 (taking the aspirin) and case 2 (not taking the aspirin). If your headache would remain without aspirin but disappear if you took aspirin, then the causal effect of taking aspirin is headache relief.
Suppose that Joe is participating in an FDA test for a new hypertension drug. If we were omniscient, we would know the outcomes for Joe under both the treatments and therefore know the treatment effect.
| subject | 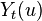 | 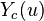 | 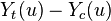 |
|---|---|---|---|
| Joe | -5 | 5 | -10 |
is the change in Joe's blood pressure if he takes the pill. In general, this notation expresses the effect of a treatment, t, on a unit, u. Similarly, is the effect of a different treatment, c or control, on a unit, u. In this case, is the change in Joe's blood pressure if he doesn't take the pill. is the causal effect of taking the drug.
From this table we only know the causal effect on Joe. Everyone else in the study might have an increase in blood pressure. However, regardless of what the causal effect is for the other subjects, the causal effect for Joe is a decrease in blood pressure.
Consider a larger sample of patients:
| subject | | | |
|---|---|---|---|
| Joe | -5 | 5 | -10 |
| Mary | -10 | -5 | -5 |
| Sally | 0 | 10 | -10 |
| Bob | -20 | -5 | -15 |
The causal effect is different for every subject, but the drug works for everyone because everyone's blood pressure decreases.
Stable unit treatment value assumption (SUTVA)
We require that "the [potential outcome] observation on one unit should be unaffected by the particular assignment of treatments to the other units" (Cox 1958, §2.4). This is called the Stable Unit Treatment Value Assumption (SUTVA), which goes beyond the concept of independence.
In the context of our example, Joe's change in blood pressure may not depend on whether or not Mary receives the drug. Suppose that Joe and Mary live in the same house. Mary always cooks. If Mary does not take the drug she will not cook salty foods, but if she does take the drug she will cook salty foods. A high salt diet increases Joe's blood pressure. Therefore, his response will depend on which treatment Mary receives. [Note that if it's a blinded trial, Mary doesn't know if she gets the active or placebo drug, so another example is probably better.]
SUTVA violation makes causal inference more difficult. We can account for dependent observations by considering more treatments. We create 4 treatments by taking into account whether or not Mary receives treatment.
| subject | Joe = c, Mary = t | Joe = t, Mary = t | Joe = c, Mary = c | Joe = t, Mary = c |
|---|---|---|---|---|
| Joe | 20 | 10 | 5 | 0 |
Now there are multiple causal effects. One is the causal effect of the drug on Joe when Mary receives treatment and is calculated, 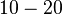 . Another is the causal effect on Joe when Mary does not receive treatment and is calculated
. Another is the causal effect on Joe when Mary does not receive treatment and is calculated 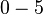 . The third is the causal effect of Mary on Joe, and is calculated
. The third is the causal effect of Mary on Joe, and is calculated 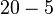 . The treatment Mary receives has a greater causal effect for Joe than the assignment of treatment to Joe.
. The treatment Mary receives has a greater causal effect for Joe than the assignment of treatment to Joe.
With additional treatments, SUTVA holds. However, if any units other than Joe are dependent on Mary, then we must consider further treatments. The greater the number of dependent units, the more treatments we must consider and the more complex the calculations become (consider an experiment with 20 different causal effects). In order to determine the causal effect using only two treatments, the observations must be independent.
Consider an example where not all subjects benefit from the drug.
| subject | | | |
|---|---|---|---|
| Joe | 10 | -5 | 15 |
| Mary | 0 | 5 | - 5 |
| Sally | -20 | 5 | -25 |
| Bob | -10 | 10 | -20 |
| James | -5 | 0 | -5 |
| MEAN | -5 | 3 | -8 |
One may calculate the average causal effect by taking the mean of all the causal effects or by subtracting the mean change under control from the mean change under treatment. Although the average causal effect is a decrease in blood pressure, the causal effect for Joe is an increase in blood pressure. Joe would never want to take the drug.
How we measure the response affects what inferences we draw. Suppose that we measure changes in blood pressure as a percentage change:
| subject | | | |
|---|---|---|---|
| Joe | 12 | -6 | 18 |
| Mary | 0 | 1 | -1 |
| Sally | -8 | 2 | -10 |
| Bob | -1 | 1 | -2 |
| James | -1 | 0 | -1 |
| MEAN | 0.4% | -0.4% | 0.8% |
This measurement suggests the opposite conclusion, that the average causal effect is an increase in blood pressure. One obtains this result because the positive change in blood pressure for Joe is a larger percentage of his blood pressure. This would occur if Joe's blood pressure is lower than the blood pressure of the other subjects. For example, Joe's blood pressure is 140 and increase by 14 mm Hg, an increase of 10%. If Mary's blood pressure is 200 mm Hg and her blood pressure increases by 14 mm Hg, then her blood pressure only increases by 7%. Consequently, a small absolute change in blood pressure would yield a larger percentage change for Joe.
The fundamental problem of causal inference
The results we have seen up to this point would never be observed in practice. It is impossible to observe the effect of more than one treatment on a subject at one time. Joe cannot both take the pill and not take the pill at the same time. Therefore, the data would look something like this:
| subject | | | |
|---|---|---|---|
| Joe | -5 | ? | ? |
Question marks are responses that could not be observed. Some scholars call the impossibility of observing responses to multiple treatments on the same subject over a given period of time the Fundamental Problem of Causal Inference (FPCI).[2] The FPCI makes observing causal effects impossible. However, this does not make causal inference impossible. Certain techniques and assumptions allow the FPCI to be overcome.
Suppose that we want to determine the causal effect of the drug on Joe. The FPCI makes it impossible to observe the causal effect so we must determine the average causal effect instead. To do this, we could instruct Joe to repeat the experiment each month for 6 consecutive months. At the beginning of each month, we would flip a coin to determine which treatment he receives. The results of this experiment follow:
| date | | | |
|---|---|---|---|
| January | -5 | ? | ? |
| February | 10 | ? | ? |
| March | ? | 10 | ? |
| April | -20 | ? | ? |
| May | ? | 5 | ? |
| June | ? | 15 | ? |
| MEAN | -5 | 10 | -15 |
Suppose that Joe could only choose to take the drug for all 6 months or not take the drug at all. During one of the months Joe's blood pressure increases when he takes the drug. However, it could have been even higher if he had not taken the drug. Joe would, on average, benefit from the drug because the average causal effect is a decrease in blood pressure. Even if he knew that he would be better off not taking the drug in February, it would most likely be in his overall interest to choose the drug for the entire duration of the study.
In order for us to conclude that the average causal effect of the pill is a decrease in Joe's blood pressure, we must make certain assumptions. Joe's responses must be independent of each other. Joe's response during any month must not be affected by the treatments he receives during any other month. His taking the drug in January should not affect his response to the control in February. If this assumption does not hold, perhaps because the drug remains in the blood stream, we would have to consider multiple treatments. By making each treatment a combination of the treatment Joe received the previous month and the treatment he would receive the following month, we would create 4 treatments:
| subject | Joe = 0, last month = 1 | Joe = 1, last month = 1 | Joe = 0, last month = 0 | Joe = 1, last month = 0 |
|---|---|---|---|---|
| Joe | 20 | 10 | 5 | 0 |
Using these different treatments would restore independence. However, as responses become dependent on more than one treatment assignment, the number of treatments becomes exponentially greater, and determining average causal effect becomes more complex. In this example, we would have to determine three different causal effects. The first is the causal effect of the drug on Joe when Joe takes the drug the month before. The second is the causal effect of the drug on Joe when Joe does not take the drug the month before. The third is the causal effect of taking the drug on Joe when he does not take the drug this month, but took it the month before.
We can infer what Joe's response to the unobserved treatment would be if we make an assumption of constant effect. This means that the causal effect is the same at different times, no different in March than it is in April. If the causal effect is always the same, then the average causal effect equals the causal effect. Therefore, knowing the average causal effect and observing one response, we can calculate the other response.
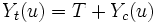
and
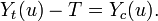
Since the average causal effect for Joe is a reduction in blood pressure, an assumption of constant effect suggests that the drug would always reduce his blood pressure.
Multiple subjects
Another way to determine average causal effect is to use multiple subjects:
| subject | | | |
|---|---|---|---|
| Joe | 10 | ? | ? |
| Mary | ? | 5 | ? |
| Sally | -20 | ? | ? |
| Bob | ? | 10 | ? |
| James | ? | 0 | ? |
| MEAN | -5 | 5 | 10 |
Mary's and Susie's blood pressures increase when they take the drug. We do not know the causal effect of the drug on Susie or Mary because we do not know their responses under control.
If we wanted to infer the unobserved values we could make an assumption of either constant effect or homogeneity, an even stronger assumption than constant effect. If the subjects are all the same or homogeneous, then they would all have the same response to the treatment and the same response to the control. Mathematically, 
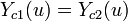 where 1 and 2 are units being tested for homogeneity. As causal effect equals , the causal effect would be the same for all of them. The following tables illustrate data that supports assumptions of constant effect, homogeneity, or both:
where 1 and 2 are units being tested for homogeneity. As causal effect equals , the causal effect would be the same for all of them. The following tables illustrate data that supports assumptions of constant effect, homogeneity, or both:
| subject | | | |
|---|---|---|---|
| Joe | 15 | 20 | -5 |
| Mary | 5 | 10 | -5 |
| Sally | -5 | 0 | -5 |
| Bob | 0 | 5 | -5 |
| James | -10 | -5 | -5 |
| MEAN | 1 | 6 | -5 |
All of the subjects have the same causal effect even though they have different responses to the treatments. This data supports the assumption of constant effect, but does not support the assumption of homogeneity.
| subject | | | |
|---|---|---|---|
| Joe | -5 | 0 | -5 |
| Mary | -5 | 0 | -5 |
| Sally | -5 | 0 | -5 |
| Bob | -5 | 0 | -5 |
| James | -5 | 0 | -5 |
| MEAN | -5 | 0 | -5 |
These subjects have the same responses to the treatment and consequently, the same causal effect. This makes them homogeneous. This data supports the assumptions of both constant effect and homogeneity.
If the assumption of homogeneity holds, then the average causal effect equals the causal effect for every unit. Knowing the average causal effect and having observed the response to one treatment for each unit, one can determine the response to the other treatment. One cannot apply this assumption to the data in this example because the responses are different for every subject.
The assignment mechanism
The assignment mechanism, the method by which units are assigned treatment, affects the calculation of the average causal effect. One such assignment mechanism is randomization. For each subject we could flip a coin to determine if she receives treatment. If we wanted five subjects to receive treatment, we could assign treatment to the first five names we pick out of a hat. When we randomly assign treatments we may get different answers.
| subject | | | |
|---|---|---|---|
| Joe | 10 | -5 | 15 |
| Mary | 0 | 5 | -5 |
| Sally | -20 | 5 | -25 |
| Bob | -10 | 10 | -20 |
| James | -5 | 0 | -5 |
| MEAN | -5 | 3 | -8 |
This is the true average causal effect. Assigning treatments randomly, we calculate another causal effect.
| subject | | | |
|---|---|---|---|
| Joe | 10 | ? | ? |
| Mary | 0 | ? | ? |
| Sally | ? | 5 | ? |
| Bob | ? | 10 | ? |
| James | -5 | ? | ? |
| MEAN | 1.66 | 7.5 | -5.83 |
Under the same mechanism another random assignment of treatments yields yet another average causal effect.
| subject | | | |
|---|---|---|---|
| Joe | 10 | ? | ? |
| Mary | 0 | ? | ? |
| Sally | -20 | ? | ? |
| Bob | ? | 10 | ? |
| James | ? | 0 | ? |
| MEAN | -3.33 | 5 | -8.33 |
The average causal effect varies because our sample is small and the responses have a large variance. If the sample were larger and the variance were less, the average causal effect would be closer to the true average causal effect.
Alternatively, suppose the mechanism assigns the treatment to all men and only to them.
| subject | | | |
|---|---|---|---|
| Joe | 10 | ? | ? |
| Bob | -10 | ? | ? |
| James | -15 | ? | ? |
| Mary | ? | 10 | ? |
| Sally | ? | 5 | ? |
| Susie | ? | 15 | ? |
| MEAN | -5 | 10 | -15 |
Under this assignment mechanism, it is impossible for women to receive treatment and therefore impossible to determine the average causal effect on female subjects. In order to make any inferences of causal effect on a subject, the probability that the subject receive treatment must be greater than 0 and less than 1.
The perfect doctor
Consider the use of the perfect doctor as an assignment mechanism. The perfect doctor knows how each subject will respond to the drug or the control and assigns each subject to the treatment that will most benefit her. The perfect doctor knows this information about a sample of patients:
| subject | | | |
|---|---|---|---|
| Joe | 10 | -5 | 15 |
| Bob | 0 | 5 | -5 |
| James | -50 | 5 | -55 |
| Mary | -10 | 10 | -20 |
| Sally | -20 | 15 | -35 |
| Susie | 10 | -20 | 30 |
| MEAN | -10 | 1.7 | -11.7 |
Based on this knowledge she would make the following treatment assignments:
| subject | | | |
|---|---|---|---|
| Joe | ? | -5 | ? |
| Bob | 0 | ? | ? |
| James | -50 | ? | ? |
| Mary | -10 | ? | ? |
| Sally | -20 | ? | ? |
| Susie | ? | -20 | ? |
| MEAN | -18 | -12.5 | -5.5 |
The perfect doctor distorts both averages by filtering out poor responses to both the treatment and control. The difference between means, which is the supposed average causal effect, is distorted in a direction that depends on details. For instance, a subject like Susie who is harmed by taking the drug would be assigned to the control group by the perfect doctor and thus the negative effect of the drug would be masked.
Matching
Another approach to estimation of causal effect is matching or pairing similar units, as an approximation to observing the same unit twice. If an experiment is possible, match units with identical or most similar attributes; randomly assign treatment to one and control to the other unit in each pair.
| subject | sex | blood pressure | | | |
|---|---|---|---|---|---|
| Joe | male | 180 | ? | -15 | ? |
| Bob | male | 180 | -20 | ? | ? |
| James | male | 160 | -10 | ? | ? |
| Paul | male | 160 | ? | -5 | ? |
| Mary | female | 180 | 5 | ? | ? |
| Sally | female | 180 | ? | 10 | ? |
| Susie | female | 160 | 5 | ? | ? |
| Jen | female | 160 | ? | 10 | ? |
| MEAN | 170 | -5 | 0 | -5 |
If matched units are homogeneous, then they have the same causal effect. This means that they have the same average causal effect. Therefore, if all units are perfectly matched, the average causal effect equals the causal effect.
Propensity score matching is often used when there are multiple attributes.
Conclusion
The causal effect of a treatment on a single unit at a point in time is the difference between the outcome variable with the treatment and without the treatment. The Fundamental Problem of Causal Inference is that it is impossible to observe the causal effect on a single unit. You either take the aspirin now or you don't. As a consequence, assumptions must be made in order to estimate the missing counterfactuals.
Relations to other approaches
In the view of Pearl (2000),[6] the Rubin Causal Model (RCM) is subsumed by the Structural Equation Model (SEM) used in econometrics and the social sciences, in its extended nonparametric form. That view, which has long been argued by Heckman (2005)[7] is presented formally in Pearl (2000).[6] The key connection between the RCM and SEM rests on interpreting the "potential outcome" variable Yx(u) to be the solution for variable Y in a modified structural model, in which the external intervention X=x is emulated by replacing the equation that determines X by the constant equation X=x.
The variable u, which in the RCM stands for the identity of each experimental unit (e.g., a patient or an agricultural lot,) is represented in the SEM formulation by a vector of exogeneous variables (usually unobserved) that characterize that unit. With this interpretation, every theorem in RCM can be shown to be a theorem in SEM and vice versa.
This interpretation has led to a complete axiomatization of RCM and, based on the derivations of Shpitser-Pearl (2006),[8] a complete solution to the identification of causal effects, using graphs. Complete solution means that, for any subset X of variables and a set A of causal assumptions encoded in a graph G, it is possible to determine algorithmically whether the causal effect P(Yx = y) can be estimated consistently from non-experimental data and, if so, what form the estimand of P(Yx = y) should have.
Using that estimand, it is possible then to estimate, from observational study, the average causal effect over the population:
![E_{u}[Y_{t}(u)-Y_{c}(u)]](/2014-wikipedia_en_all_02_2014/I/media/e/0/a/9/e0a9a796234a30bb0648536353c7ce0e.png) .
.
From the perspective of Pearl and his colleagues, a major shortcoming of RCM is that all assumptions and background knowledge pertaining to a given problem must first be translated into the language of counterfactuals (e.g., ignorability) before analysis can commence. In SEM, by comparison, Pearl (2000)[6] and Heckman (2008)[9] hold that background knowledge is expressed directly in the vocabulary of ordinary scientific discourse, invoking cause-effect relationships among realizable, not hypothetical variables.[10]
The Rubin causal model has also been connected to instrumental variables (Angrist, Imbens, and Rubin, 1996)[11] and other techniques for causal inference. For more on the connections between the Rubin causal model, structural equation modeling, and other statistical methods for causal inference, see Morgan and Winship (2007)[12] and Pearl (2009).[10]
See also
References
- ↑ 1.0 1.1 1.2 1.3 Sekhon, Jasjeet (2007). "The Neyman-Rubin Model of Causal Inference and Estimation via Matching Methods". The Oxford Handbook of Political Methodology.
- ↑ 2.0 2.1 Holland, Paul W. (1986). "Statistics and Causal Inference". J. Amer. Statist. Assoc. 81 (396): 945–960. JSTOR 2289064.
- ↑ Neyman, Jerzy. Sur les applications de la theorie des probabilites aux experiences agricoles: Essai des principes. Master's Thesis (1923). Excerpts reprinted in English, Statistical Science, Vol. 5, pp. 463-472. (D. M. Dabrowska, and T. P. Speed, Translators.)
- ↑ Rubin, Donald (2005). "Causal Inference Using Potential Outcomes". J. Amer. Statist. Assoc. 100 (469): 322–331. doi:10.1198/016214504000001880.
- ↑ Rubin, Donald (1974). "Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies". J. Educ. Psychol. 66 (5): 688–701 [p. 689]. doi:10.1037/h0037350.
- ↑ 6.0 6.1 6.2 Pearl, J. Causality: Models, Reasoning, and Inference, Cambridge University Press (2000).
- ↑ Heckman, J.J., The scientific model of causality, Sociological methodology, Vol. 35, 1-97, 2005. http://www.jstor.org/stable/4148843
- ↑ Shpitser, I. and Pearl, J., Identification of Conditional Interventional Distributions. In R. Dechter and T.S. Richardson (Eds.), Proceedings of the Twenty-Second Conference on Uncertainty in Artificial Intelligence, Corvallis, OR: AUAI Press, 437-444, 2006.
- ↑ Heckman, J.J. Econometric Causality. International Statistical Review, Vol. 76, 1--27, 2008.
- ↑ 10.0 10.1 Pearl, J. Causal inference in statistics: An overview. UCLA Computer Science Department, Technical Report R-350. To appear in Statistics Surveys, 2009.
- ↑ Angrist, J.; Imbens, G.; Rubin, D. (1996). "Identification of Causal effects Using Instrumental Variables". J. Amer. Statist. Assoc. 91 (434): 444–455. doi:10.1080/01621459.1996.10476902.
- ↑ Morgan, S.; Winship, C. (2007). Counterfactuals and Causal Inference: Methods and Principles for Social Research. New York: Cambridge University Press. ISBN 978-0-521-67193-4.
- Donald Rubin (1977) "Assignment to Treatment Group on the Basis of a Covariate", Journal of Educational Statistics, 2, pp. 1–26.
- Rubin, Donald (1978) "Bayesian Inference for Causal Effects: The Role of Randomization", The Annals of Statistics, 6, pp. 34–58.
- Rubin, Donald (1974) "Estimating Causal Effects of Treatments in Randomized and Nonrandomized Studies", Journal of Educational Psychology, 66 (5), pp. 688–701.
External links
- "Rubin Causal Model": an article for the New Palgrave Dictionary of Economics by Guido Imbens and Donald Rubin.
- "Counterfactual Causal Analysis": a webpage maintained by Stephen Morgan, Christopher Winship, and others with links to many research articles on causal inference.