Random variable
| Probability theory |
|---|
 |
In probability and statistics, a random variable, aleatory variable or stochastic variable is a variable whose value is subject to variations due to chance (i.e. randomness, in a mathematical sense).[1]:391 As opposed to other mathematical variables, a random variable conceptually does not have a single, fixed value (even if unknown); rather, it can take on a set of possible different values, each with an associated probability.
A random variable's possible values might represent the possible outcomes of a yet-to-be-performed experiment, or the possible outcomes of a past experiment whose already-existing value is uncertain (for example, as a result of incomplete information or imprecise measurements). They may also conceptually represent either the results of an "objectively" random process (such as rolling a die), or the "subjective" randomness that results from incomplete knowledge of a quantity. The meaning of the probabilities assigned to the potential values of a random variable is not part of probability theory itself, but instead related to philosophical arguments over the interpretation of probability. The mathematics works the same regardless of the particular interpretation in use.
The mathematical function describing the possible values of a random variable and their associated probabilities is known as a probability distribution. Random variables can be discrete, that is, taking any of a specified finite or countable list of values, and hence with a probability mass function as probability distribution, continuous, taking any numerical value in an interval or collection of intervals, and with a probability density function describing the probability distribution, or a mixture of both types. The realizations of a random variable, that is, the results of randomly choosing values according to the variable's probability distribution, are called random variates.
The formal mathematical treatment of random variables is a topic in probability theory. In that context, a random variable is understood as a function defined on a sample space whose outputs are numerical values.[2]
Definition
Random variable is usually understood to mean a real-valued random variable; this discussion assumes real values. A random variable is a real-valued function defined on a set of possible outcomes, the sample space Ω. That is, the random variable is a function that maps from its domain, the sample space Ω, to its range, the real numbers or a subset of the real numbers. It is typically some kind of a property or measurement on the random outcome (for example, if the random outcome is a randomly chosen person, the random variable might be the person's height, or number of children).
The fine print: the admissible functions for defining random variables are limited to those for which a probability distribution exists, derivable from a probability measure that turns the sample space into a probability space. That is, for the mapping to be an admissible random variable, it must be theoretically possible to compute the probability that the value of the random variable is less than any particular real number. Equivalently, the preimage of any range of values of the random variable must be a subset of Ω that has a defined probability; that is, there exists a subset of Ω, an event, the probability of which is the same probability as the random variable being in the range of real numbers that that event maps to. Furthermore, the notion of a "range of values" here must be generalizable to the non-pathological subset of reals known as Borel sets.[3]
Random variables are typically distinguished as discrete versus continuous ones. Mixtures of both types also exist.
Discrete random variables can take on either a finite or at most a countably infinite set of discrete values (for example, the integers).[1]:392 Their probability distribution is given by a probability mass function which directly maps each value of the random variable to a probability; for each possible value of the random variable, the probability is equal to the probability of the event containing all possible outcomes in Ω that map to that value.
Continuous random variables, on the other hand, take on values that vary continuously within one or more real intervals[1]:399, and have a cumulative distribution function (CDF) that is absolutely continuous. As a result, the random variable has an uncountably infinite number of possible values, all of which have probability 0, though ranges of such values can have nonzero probability. The resulting probability distribution of the random variable can be described by a probability density. (Some sources refer to this class as "absolutely continuous random variables", and allow a wider class of "continuous random variables",[4] including those with singular distributions, but note that these are typically not encountered in practical situations.[5])
Random variables with discontinuities in their CDFs can be treated as mixtures of discrete and continuous random variables.
Examples
For example, in an experiment a person may be chosen at random, and one random variable may be the person's height. Mathematically, the random variable is interpreted as a function which maps the person to the person's height. Associated with the random variable is a probability distribution that allows the computation of the probability that the height is in any non-pathological subset of possible values, such as probability that the height is between 180 and 190 cm, or the probability that the height is either less than 150 or more than 200 cm.
Another random variable may be the person's number of children; this is a discrete random variable with non-negative integer values. It allows the computation of probabilities for individual integer values – the probability mass function (PMF) – or for sets of values, including infinite sets. For example, the event of interest may be "an even number of children". For both finite and infinite event sets, their probabilities can be found by adding up the PMFs of the elements; that is, the probability of an even number of children is the infinite sum PMF(0) + PMF(2) + PMF(4) + ...
In examples such as these, the sample space (the set of all possible persons) is often suppressed, since it is mathematically hard to describe, and the possible values of the random variables are then treated as a sample space. But when two random variables are measured on the same sample space of outcomes, such as the height and number of children being computed on the same random persons, it is easier to track their relationship if it is acknowledged that both height and number of children come from the same random person, for example so that questions of whether such random variables are correlated or not can be posed.
Probability density
The probability distribution for continuous random variables can be defined using a probability density function (PDF or p.d.f), which indicates the "density" of probability in a small neighborhood around a given value. The probability that a random variable is in a particular range can then be computed from the integral of the probability density function over that range. The PDF is the derivative of the CDF.
Mixtures
Some random variables are neither discrete nor continuous, but a mixture of both types. Their CDF is not absolutely continuous, and a PDF does not exist. For example, a typical "sparse" continuous random variable may be exactly 0 with probability 0.9, and continuously distributed otherwise, so its CDF has a big jump discontinuity at 0. The PDF therefore does not exist as an ordinary function in this case, though such situations are easily handled by using a distribution instead of a function to represent a PDF, or by using other representations of measure.
Extensions
The basic concept of "random variable" in statistics is real-valued, and therefore expected values, variances and other measures can be computed. However, one can consider arbitrary types such as boolean values, categorical variables, complex numbers, vectors, matrices, sequences, trees, sets, shapes, manifolds, functions, and processes. The term random element is used to encompass all such related concepts.
Another extension is the stochastic process, a set of indexed random variables (typically indexed by time or space).
These more general concepts are particularly useful in fields such as computer science and natural language processing where many of the basic elements of analysis are non-numerical. Such general random elements can sometimes be treated as sets of real-valued random variables — often more specifically as random vectors. For example:
- A "random word" may be parameterized by an integer-valued index into the vocabulary of possible words; alternatively, as an indicator vector, in which exactly one element is a 1, and the others are 0, with the one indexing a particular word into a vocabulary.
- A "random sentence" may be parameterized as a vector of random words.
- A random graph, for a graph with V edges, may be parameterized as an NxN matrix, indicating the weight for each edge, or 0 for no edge. (If the graph has no weights, 1 indicates an edge; 0 indicates no edge.)
Reduction to numerical values is not essential for dealing with random elements: a randomly selected individual remains an individual, not a number.
Examples
The possible outcomes for one coin toss can be described by the sample space  = {heads, tails}. We can introduce a real-valued random variable Y that models a $1 payoff for a successful bet on heads as follows:
= {heads, tails}. We can introduce a real-valued random variable Y that models a $1 payoff for a successful bet on heads as follows:

If the coin is equally likely to land on either side then Y has a probability mass function ƒY given by:
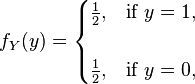
.svg.png)
A random variable can also be used to describe the process of rolling dice and the possible outcomes. The most obvious representation for the two-dice case is to take the set of pairs of numbers n1 and n2 from {1, 2, 3, 4, 5, 6} representing the numbers on the two dice as the sample space, defining the random variable X to be equal to the total number rolled, the sum of the numbers in each pair. In this case, the random variable of interest X is defined as the function that maps the pair to the sum:
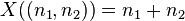
and has probability mass function ƒX given by:
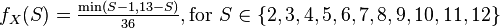
An example of a continuous random variable would be one based on a spinner that can choose a horizontal direction. Then the values taken by the random variable are directions. We could represent these directions by North, West, East, South, Southeast, etc. However, it is commonly more convenient to map the sample space to a random variable which takes values which are real numbers. This can be done, for example, by mapping a direction to a bearing in degrees clockwise from North. The random variable then takes values which are real numbers from the interval [0, 360), with all parts of the range being "equally likely". In this case, X = the angle spun. Any real number has probability zero of being selected, but a positive probability can be assigned to any range of values. For example, the probability of choosing a number in [0, 180] is ½. Instead of speaking of a probability mass function, we say that the probability density of X is 1/360. The probability of a subset of [0, 360) can be calculated by multiplying the measure of the set by 1/360. In general, the probability of a set for a given continuous random variable can be calculated by integrating the density over the given set.
An example of a random variable of mixed type would be based on an experiment where a coin is flipped and the spinner is spun only if the result of the coin toss is heads. If the result is tails, X = −1; otherwise X = the value of the spinner as in the preceding example. There is a probability of ½ that this random variable will have the value −1. Other ranges of values would have half the probability of the last example.
Measure-theoretic definition
The most formal, axiomatic definition of a random variable involves measure theory. Continuous random variables are defined in terms of sets of numbers, along with functions that map such sets to probabilities. Because of various difficulties (e.g. the Banach–Tarski paradox) that arise if such sets are insufficiently constrained, it is necessary to introduce what is termed a sigma-algebra to constrain the possible sets over which probabilities can be defined. Normally, a particular such sigma-algebra is used, the Borel σ-algebra, which allows for probabilities to be defined over any sets that can be derived either directly from continuous intervals of numbers or by a finite or countably infinite number of unions and/or intersections of such intervals.[2]
The measure-theoretic definition is as follows.
Let (Ω, ℱ, P) be a probability space and (E, ℰ) a measurable space. Then an (E, ℰ)-valued random variable is a function X: Ω→E which is (ℱ, ℰ)-measurable. The latter means that, for every subset B ∈ ℰ, its preimage X −1(B) ∈ ℱ where X −1(B) = {ω: X(ω) ∈ B}.[6] This definition enables us to measure any subset B in the target space by looking at its preimage, which by assumption is measurable.
When E is a topological space, then the most common choice for the σ-algebra ℰ is to take it equal to the Borel σ-algebra ℬ(E), which is the σ-algebra generated by the collection of all open sets in E. In such case the (E, ℰ)-valued random variable is called the E-valued random variable. Moreover, when space E is the real line ℝ, then such real-valued random variable is called simply the random variable.
Real-valued random variables
In this case the observation space is the real numbers. Recall, 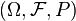 is the probability space. For real observation space, the function
is the probability space. For real observation space, the function 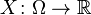 is a real-valued random variable if
is a real-valued random variable if
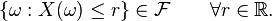
This definition is a special case of the above because the set ![\{(-\infty ,r]:r\in \mathbb{R} \}](/2014-wikipedia_en_all_02_2014/I/media/7/e/9/7/7e978ff4357b04dc715271f1cc743566.png) generates the Borel σ-algebra on the real numbers, and it suffices to check measurability on any generating set. Here we can prove measurability on this generating set by using the fact that
generates the Borel σ-algebra on the real numbers, and it suffices to check measurability on any generating set. Here we can prove measurability on this generating set by using the fact that ![\{\omega :X(\omega )\leq r\}=X^{{-1}}((-\infty ,r])](/2014-wikipedia_en_all_02_2014/I/media/4/b/7/1/4b71a32b862a640cf96aa20333258f40.png) .
.
Distribution functions of random variables
If a random variable 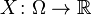 defined on the probability space is given, we can ask questions like "How likely is it that the value of
defined on the probability space is given, we can ask questions like "How likely is it that the value of  is bigger than 2?". This is the same as the probability of the event
is bigger than 2?". This is the same as the probability of the event  which is often written as
which is often written as 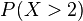 for short.
for short.
Recording all these probabilities of output ranges of a real-valued random variable X yields the probability distribution of X. The probability distribution "forgets" about the particular probability space used to define X and only records the probabilities of various values of X. Such a probability distribution can always be captured by its cumulative distribution function
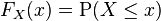
and sometimes also using a probability density function. In measure-theoretic terms, we use the random variable X to "push-forward" the measure P on Ω to a measure dF on R. The underlying probability space Ω is a technical device used to guarantee the existence of random variables, sometimes to construct them, and to define notions such as correlation and dependence or independence based on a joint distribution of two or more random variables on the same probability space. In practice, one often disposes of the space Ω altogether and just puts a measure on R that assigns measure 1 to the whole real line, i.e., one works with probability distributions instead of random variables.
Moments
The probability distribution of a random variable is often characterised by a small number of parameters, which also have a practical interpretation. For example, it is often enough to know what its "average value" is. This is captured by the mathematical concept of expected value of a random variable, denoted E[X], and also called the first moment. In general, E[f(X)] is not equal to f(E[X]). Once the "average value" is known, one could then ask how far from this average value the values of X typically are, a question that is answered by the variance and standard deviation of a random variable. E[X] can be viewed intuitively as an average obtained from an infinite population, the members of which are particular evaluations of X.
Mathematically, this is known as the (generalised) problem of moments: for a given class of random variables X, find a collection {fi} of functions such that the expectation values E[fi(X)] fully characterise the distribution of the random variable X.
Moments can only be defined for real-valued functions of random variables (or complex-valued, etc.). If the random variable is itself real-valued, then moments of the variable itself can be taken, which are equivalent to moments of the identity function 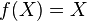 of the random variable. However, even for non-real-valued random variables, moments can be taken of real-valued functions of those variables. For example, for a categorical random variable X that can take on the nominal values "red", "blue" or "green", the real-valued function
of the random variable. However, even for non-real-valued random variables, moments can be taken of real-valued functions of those variables. For example, for a categorical random variable X that can take on the nominal values "red", "blue" or "green", the real-valued function ![[X={\text{green}}]](/2014-wikipedia_en_all_02_2014/I/media/d/3/9/7/d39712e75f57b55eef3478dfa44b15c7.png) can be constructed; this uses the Iverson bracket, and has the value 1 if X has the value "green", 0 otherwise. Then, the expected value and other moments of this function can be determined.
can be constructed; this uses the Iverson bracket, and has the value 1 if X has the value "green", 0 otherwise. Then, the expected value and other moments of this function can be determined.
Functions of random variables
A new random variable Y can be defined by applying a real Borel measurable function 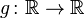 to the outcomes of a real-valued random variable X. The cumulative distribution function of
to the outcomes of a real-valued random variable X. The cumulative distribution function of 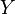 is
is
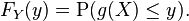
If function g is invertible, i.e. g−1 exists, and is either increasing or decreasing, then the previous relation can be extended to obtain
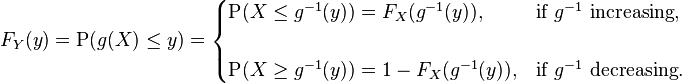
and, again with the same hypotheses of invertibility of g, assuming also differentiability, we can find the relation between the probability density functions by differentiating both sides with respect to y, in order to obtain

If there is no invertibility of g but each y admits at most a countable number of roots (i.e. a finite, or countably infinite, number of xi such that y = g(xi)) then the previous relation between the probability density functions can be generalized with
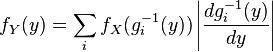
where xi = gi-1(y). The formulas for densities do not demand g to be increasing.
In the measure-theoretic, axiomatic approach to probability, if we have a random variable 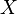 on
on  and a Borel measurable function , then
and a Borel measurable function , then  will also be a random variable on , since the composition of measurable functions is also measurable. (However, this is not true if
will also be a random variable on , since the composition of measurable functions is also measurable. (However, this is not true if 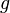 is Lebesgue measurable.) The same procedure that allowed one to go from a probability space
is Lebesgue measurable.) The same procedure that allowed one to go from a probability space 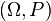 to
to 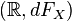 can be used to obtain the distribution of .
can be used to obtain the distribution of .
Example 1
Let X be a real-valued, continuous random variable and let Y = X2.
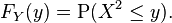
If y < 0, then P(X2 ≤ y) = 0, so

If y ≥ 0, then
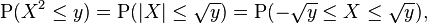
so

Example 2
Suppose 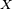 is a random variable with a cumulative distribution
is a random variable with a cumulative distribution

where 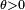 is a fixed parameter. Consider the random variable
is a fixed parameter. Consider the random variable 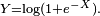 Then,
Then,

The last expression can be calculated in terms of the cumulative distribution of  so
so

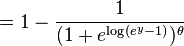
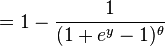
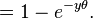
Example 3
Suppose is a random variable with a standard normal distribution, whose density is
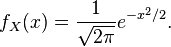
Consider the random variable 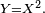 We can find the density using the above formula for a change of variables:
We can find the density using the above formula for a change of variables:
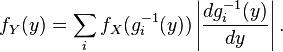
In this case the change is not monotonic, because every value of  has two corresponding values of (one positive and negative). However, because of symmetry, both halves will transform identically, i.e.
has two corresponding values of (one positive and negative). However, because of symmetry, both halves will transform identically, i.e.
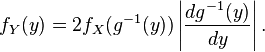
The inverse transformation is
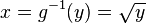
and its derivative is

Then:
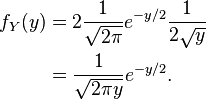
This is a chi-squared distribution with one degree of freedom.
Equivalence of random variables
There are several different senses in which random variables can be considered to be equivalent. Two random variables can be equal, equal almost surely, or equal in distribution.
In increasing order of strength, the precise definition of these notions of equivalence is given below.
Equality in distribution
If the sample space is a subset of the real line a possible definition is that random variables X and Y are equal in distribution if they have the same distribution functions:
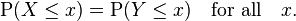
Two random variables having equal moment generating functions have the same distribution. This provides, for example, a useful method of checking equality of certain functions of i.i.d. random variables. However, the moment generating function exists only for distributions that have a defined Laplace transform.
Almost sure equality
Two random variables X and Y are equal almost surely if, and only if, the probability that they are different is zero:
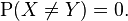
For all practical purposes in probability theory, this notion of equivalence is as strong as actual equality. It is associated to the following distance:
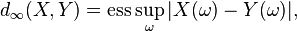
where "ess sup" represents the essential supremum in the sense of measure theory.
Equality
Finally, the two random variables X and Y are equal if they are equal as functions on their measurable space:
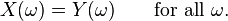
Convergence
A significant theme in mathematical statistics consists of obtaining convergence results for certain sequences of random variables; for instance the law of large numbers and the central limit theorem.
There are various senses in which a sequence (Xn) of random variables can converge to a random variable X. These are explained in the article on convergence of random variables.
See also
References
- ↑ 1.0 1.1 1.2 Yates, Daniel S.; Moore, David S; Starnes, Daren S. (2003). The Practice of Statistics (2nd ed.). New York: Freeman. ISBN 978-0-7167-4773-4.
- ↑ 2.0 2.1 Steigerwald, Douglas G. "Economics 245A – Introduction to Measure Theory". University of California, Santa Barbara. Retrieved April 26, 2013.
- ↑ Emanuel, Parzen (1962). Stochastic Processes. SIAM. p. 8. ISBN 9780898714418.
- ↑ L. Castañeda, V. Arunachalam, and S. Dharmaraja (2012). Introduction to Probability and Stochastic Processes with Applications. Wiley. p. 67.
- ↑ Epps, T. W. (2007). Pricing Derivative Securities. World Scientific. p. 52. ISBN 9789812700339.
- ↑ Fristedt & Gray (1996, page 11)
Literature
- Fristedt, Bert; Gray, Lawrence (1996). A modern approach to probability theory. Boston: Birkhäuser. ISBN 3-7643-3807-5.
- Kallenberg, Olav (1986). Random Measures (4th ed.). Berlin: Akademie Verlag. ISBN 0-12-394960-2. MR MR0854102.
- Kallenberg, Olav (2001). Foundations of Modern Probability (2nd ed.). Berlin: Springer Verlag. ISBN 0-387-95313-2.
- Papoulis, Athanasios (1965). Probability, Random Variables, and Stochastic Processes (9th ed.). Tokyo: McGraw–Hill. ISBN 0-07-119981-0.
External links
- Hazewinkel, Michiel, ed. (2001), "Random variable", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4