Random binary tree
| Part of a series on |
| Probabilistic data structures |
|---|
| Bloom filter · Quotient filter · Skip list |
| Random trees |
| Rapidly exploring random tree |
| Related |
| Randomized algorithm |
| Computer science Portal |
In computer science and probability theory, a random binary tree refers to a binary tree selected at random from some probability distribution on binary trees. Two different distributions are commonly used: binary trees formed by inserting nodes one at a time according to a random permutation, and binary trees chosen from a uniform discrete distribution in which all distinct trees are equally likely. It is also possible to form other distributions, for instance by repeated splitting. Adding and removing nodes directly in a random binary tree will in general disrupt its random structure, but the treap and related randomized binary search tree data structures use the principle of binary trees formed from a random permutation in order to maintain a balanced binary search tree dynamically as nodes are inserted and deleted.
For random trees that are not necessarily binary, see random tree.
Binary trees from random permutations
For any set of numbers (or, more generally, values from some total order), one may form a binary search tree in which each number is inserted in sequence as a leaf of the tree, without changing the structure of the previously inserted numbers. The position into which each number should be inserted is uniquely determined by a binary search in the tree formed by the previous numbers. For instance, if the three numbers (1,3,2) are inserted into a tree in that sequence, the number 1 will sit at the root of the tree, the number 3 will be placed as its right child, and the number 2 as the left child of the number 3. There are six different permutations of the numbers (1,2,3), but only five trees may be constructed from them. That is because the permutations (2,1,3) and (2,3,1) form the same tree.
Expected depth of a node
For any fixed choice of a value x in a given set of n numbers, if one randomly permutes the numbers and forms a binary tree from them as described above, the expected value of the length of the path from the root of the tree to x is at most 2 log n + O(1), where "log" denotes the natural logarithm function and the O introduces big O notation. For, the expected number of ancestors of x is by linearity of expectation equal to the sum, over all other values y in the set, of the probability that y is an ancestor of x. And a value y is an ancestor of x exactly when y is the first element to be inserted from the elements in the interval [x,y]. Thus, the values that are adjacent to x in the sorted sequence of values have probability 1/2 of being an ancestor of x, the values one step away have probability 1/3, etc. Adding these probabilities for all positions in the sorted sequence gives twice a Harmonic number, leading to the bound above. A bound of this form holds also for the expected search length of a path to a fixed value x that is not part of the given set.[1]
The longest path
Although not as easy to analyze as the average path length, there has also been much research on determining the expectation (or high probability bounds) of the length of the longest path in a binary search tree generated from a random insertion order. It is now known that this length, for a tree with n nodes, is almost surely
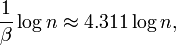
where β is the unique number in the range 0 < β < 1 satisfying the equation

Expected number of leaves
In the random permutation model, each of the numbers from the set of numbers used to form the tree, except for the smallest and largest of the numbers, has probability 1/3 of being a leaf in the tree, for it is a leaf when it inserted after its two neighbors, and any of the six permutations of these two neighbors and it are equally likely. By similar reasoning, the smallest and largest of the numbers have probability 1/2 of being a leaf. Therefore, the expected number of leaves is the sum of these probabilities, which for n ≥ 2 is exactly (n + 1)/3.
Treaps and randomized binary search trees
In applications of binary search tree data structures, it is rare for the values in the tree to be inserted without deletion in a random order, limiting the direct applications of random binary trees. However, algorithm designers have devised data structures that allow insertions and deletions to be performed in a binary search tree, at each step maintaining as an invariant the property that the shape of the tree is a random variable with the same distribution as a random binary search tree.
If a given set of ordered numbers is assigned numeric priorities (distinct numbers unrelated to their values), these priorities may be used to construct a Cartesian tree for the numbers, a binary tree that has as its inorder traversal sequence the sorted sequence of the numbers and that is heap-ordered by priorities. Although more efficient construction algorithms are known, it is helpful to think of a Cartesian tree as being constructed by inserting the given numbers into a binary search tree in priority order. Thus, by choosing the priorities either to be a set of independent random real numbers in the unit interval, or by choosing them to be a random permutation of the numbers from 1 to n (where n is the number of nodes in the tree), and by maintaining the heap ordering property using tree rotations after any insertion or deletion of a node, it is possible to maintain a data structure that behaves like a random binary search tree. Such a data structure is known as a treap or a randomized binary search tree.[3]
Uniformly random binary trees
The number of binary trees with n nodes is a Catalan number: for n = 1, 2, 3, ... these numbers of trees are
Thus, if one of these trees is selected uniformly at random, its probability is the reciprocal of a Catalan number. Trees in this model have expected depth proportional to the square root of n, rather than to the logarithm;[4] however, the Strahler number of a uniformly random binary tree, a more sensitive measure of the distance from a leaf in which a node has Strahler number i whenever it has either a child with that number or two children with number i − 1, is with high probability logarithmic.[5]
Due to their large heights, this model of equiprobable random trees is not generally used for binary search trees, but it has been applied to problems of modeling the parse trees of algebraic expressions in compiler design[6] (where the above-mentioned bound on Strahler number translates into the number of registers needed to evaluate an expression[7]) and for modeling evolutionary trees.[8] In some cases the analysis of random binary trees under the random permutation model can be automatically transferred to the uniform model.[9]
Random split trees
Devroye & Kruszewski (1996) generate random binary trees with n nodes by generating a real-valued random variable x in the unit interval (0,1), assigning the first xn nodes (rounded down to an integer number of nodes) to the left subtree, the next node to the root, and the remaining nodes to the right subtree, and continuing recursively in each subtree. If x is chosen uniformly at random in the interval, the result is the same as the random binary search tree generated by a random permutation of the nodes, as any node is equally likely to be chosen as root; however, this formulation allows other distributions to be used instead. For instance, in the uniformly random binary tree model, once a root is fixed each of its two subtrees must also be uniformly random, so the uniformly random model may also be generated by a different choice of distribution for x. As Devroye and Kruszewski show, by choosing a beta distribution on x and by using an appropriate choice of shape to draw each of the branches, the mathematical trees generated by this process can be used to create realistic-looking botanical trees.
Notes
- ↑ Hibbard (1962); Knuth (1973); Mahmoud (1992), p. 75.
- ↑ Robson (1979); Pittel (1985); Devroye (1986); Mahmoud (1992), pp. 91–99; Reed (2003).
- ↑ Martinez & Roura (1992); Seidel & Aragon (1996).
- ↑ Knuth (2005), p. 15.
- ↑ Devroye & Kruszewski (1995). That it is at most logarithmic is trivial, because the Strahler number of every tree is bounded by the logarithm of the number of its nodes.
- ↑ Mahmoud (1992), p. 63.
- ↑ Flajolet, Raoult & Vuillemin (1979).
- ↑ Aldous (1996).
- ↑ Mahmoud (1992), p. 70.
References
- Aldous, David (1996), "Probability distributions on cladograms", in Aldous, David; Pemantle, Robin, Random Discrete Structures, The IMA Volumes in Mathematics and its Applications 76, Springer-Verlag, pp. 1–18.
- Devroye, Luc (1986), "A note on the height of binary search trees", Journal of the ACM 33 (3): 489–498, doi:10.1145/5925.5930.
- Devroye, Luc; Kruszewski, Paul (1995), "A note on the Horton-Strahler number for random trees", Information Processing Letters 56 (2): 95–99, doi:10.1016/0020-0190(95)00114-R.
- Devroye, Luc; Kruszewski, Paul (1996), "The botanical beauty of random binary trees", in Brandenburg, Franz J., Graph Drawing: 3rd Int. Symp., GD'95, Passau, Germany, September 20-22, 1995, Lecture Notes in Computer Science 1027, Springer-Verlag, pp. 166–177, doi:10.1007/BFb0021801, ISBN 3-540-60723-4.
- Drmota, Michael (2009), Random Trees : An Interplay between Combinatorics and Probability, Springer-Verlag, ISBN 978-3-211-75355-2.
- Flajolet, P.; Raoult, J. C.; Vuillemin, J. (1979), "The number of registers required for evaluating arithmetic expressions", Theoretical Computer Science 9 (1): 99–125, doi:10.1016/0304-3975(79)90009-4.
- Hibbard, T. (1962), "Some combinatorial properties of certain trees with applications to searching and sorting", Journal of the ACM 9 (1): 13–28, doi:10.1145/321105.321108.
- Knuth, Donald M. (1973), "6.2.2 Binary Tree Searching", The Art of Computer Programming III, Addison-Wesley, pp. 422–451.
- Knuth, Donald M. (2005), "Draft of Section 7.2.1.6: Generating All Trees", The Art of Computer Programming IV.
- Mahmoud, Hosam M. (1992), Evolution of Random Search Trees, John Wiley & Sons.
- Martinez, Conrado; Roura, Salvador (1998), "Randomized binary search trees", Journal of the ACM (ACM Press) 45 (2): 288–323, doi:10.1145/274787.274812.
- Pittel, B. (1985), "Asymptotical growth of a class of random trees", Annals of Probability 13 (2): 414–427, doi:10.1214/aop/1176993000.
- Reed, Bruce (2003), "The height of a random binary search tree", Journal of the ACM 50 (3): 306–332, doi:10.1145/765568.765571.
- Robson, J. M. (1979), "The height of binary search trees", Australian Computer Journal 11: 151–153.
- Seidel, Raimund; Aragon, Cecilia R. (1996), "Randomized Search Trees", Algorithmica 16 (4/5): 464–497, doi:10.1007/s004539900061.