Rényi entropy
In information theory, the Rényi entropy generalizes the Shannon entropy, the Hartley entropy, the min-entropy, and the collision entropy. Entropies quantify the diversity, uncertainty, or randomness of a system. The Rényi entropy is named after Alfréd Rényi.[1]
The Rényi entropy is important in ecology and statistics as indices of diversity. The Rényi entropy is also important in quantum information, where it can be used as a measure of entanglement. In the Heisenberg XY spin chain model, the Rényi entropy as a function of α can be calculated explicitly by virtue of the fact that it is an automorphic function with respect to a particular subgroup of the modular group.[2][3] In theoretical computer science, the min-entropy is used in the context of randomness extractors.
Definition
The Rényi entropy of order  , where
, where  and
and  , is defined as
, is defined as
 .[1]
.[1]
Here,  is a discrete random variable with possible outcomes
is a discrete random variable with possible outcomes 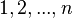 and corresponding probabilities
and corresponding probabilities 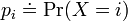 for
for 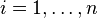 , and the logarithm is base 2.
If the probabilities are
, and the logarithm is base 2.
If the probabilities are  for all , then all the Rényi entropies of the distribution are equal:
for all , then all the Rényi entropies of the distribution are equal:  .
In general, for all discrete random variables ,
.
In general, for all discrete random variables ,  is a non-increasing function in .
is a non-increasing function in .
Applications often exploit the following relation between the Rényi entropy and the p-norm:
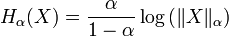 .
.
Here, the discrete probability distribution is interpreted as a vector in  with
with 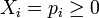 and
and 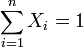 .
.
The Rényi entropy for any is Schur concave.
Special cases of the Rényi entropy
As approaches zero, the Rényi entropy increasingly weighs all possible events more equally, regardless of their probabilities.
In the limit for  , the Rényi entropy is just the logarithm of the size of the support of .
The limit for
, the Rényi entropy is just the logarithm of the size of the support of .
The limit for 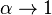 equals the Shannon entropy, which has special properties.
As approaches infinity, the Rényi entropy is increasingly determined by the events of highest probability.
equals the Shannon entropy, which has special properties.
As approaches infinity, the Rényi entropy is increasingly determined by the events of highest probability.
Hartley entropy
Provided the probabilities are nonzero,[4] 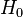 is the logarithm of the cardinality of X, sometimes called the Hartley entropy of X:
is the logarithm of the cardinality of X, sometimes called the Hartley entropy of X:

Shannon entropy
In the limit  , it follows immediately that
, it follows immediately that  converges to the Shannon entropy:[5]
converges to the Shannon entropy:[5]
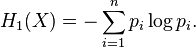
Collision entropy
Collision entropy, sometimes just called "Rényi entropy," refers to the case 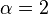 ,
,
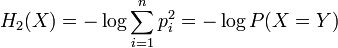
where X and Y are independent and identically distributed.
Min-entropy
In the limit as  , the Rényi entropy converges to the min-entropy
, the Rényi entropy converges to the min-entropy 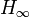 :
:
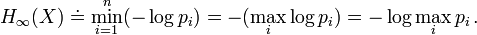
Equivalently, the min-entropy 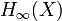 is the largest real number
is the largest real number  such that all events occur with probability at most
such that all events occur with probability at most  .
.
The name min-entropy stems from the fact that it is the smallest entropy measure in the family of Rényi entropies. In this sense, it is the strongest way to measure the information content of a discrete random variable. In particular, the min-entropy is never larger than the Shannon entropy.
The min-entropy has important applications for randomness extractors in theoretical computer science: Extractors are able to extract randomness from random sources that have a large min-entropy; merely having a large Shannon entropy does not suffice for this task.
Inequalities between different values of α
That is non-increasing in ,
which can be proven by differentiation,[6] as
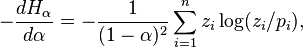
which is proportional to Kullback–Leibler divergence (which is always non-negative), where
 .
.
In particular cases inequalities can be proven also by Jensen's inequality:
 .,
.,For values of  , inequalities in the other direction also hold. In particular, we have
, inequalities in the other direction also hold. In particular, we have
 .[9][citation needed]
.[9][citation needed]
On the other hand, the Shannon entropy  can be arbitrarily high for a random variable that has a constant min-entropy.[citation needed]
can be arbitrarily high for a random variable that has a constant min-entropy.[citation needed]
Rényi divergence
As well as the absolute Rényi entropies, Rényi also defined a spectrum of divergence measures generalising the Kullback–Leibler divergence.
The Rényi divergence of order α, where α > 0, of a distribution P from a distribution Q is defined to be:
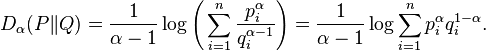
Like the Kullback-Leibler divergence, the Rényi divergences are non-negative for α>0. This divergence is also known as the alpha-divergence (-divergence).
Some special cases:
 : minus the log probability under Q that pi>0;
: minus the log probability under Q that pi>0;
 : minus twice the logarithm of the Bhattacharyya coefficient;
: minus twice the logarithm of the Bhattacharyya coefficient;
 : the Kullback-Leibler divergence;
: the Kullback-Leibler divergence;
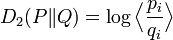 : the log of the expected ratio of the probabilities;
: the log of the expected ratio of the probabilities;
 : the log of the maximum ratio of the probabilities.
: the log of the maximum ratio of the probabilities.
Why α=1 is special
The value α = 1, which gives the Shannon entropy and the Kullback–Leibler divergence, is special because it is only at α=1 that the chain rule of conditional probability holds exactly:
![H(A,X)=H(A)+{\mathbb {E}}_{{a\sim A}}{\big [}H(X|A=a){\big ]}](/2014-wikipedia_en_all_02_2014/I/media/1/8/3/8/183893ceb7cf31485ae32a3cab738ac4.png)
for the absolute entropies, and
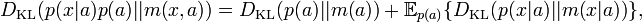
for the relative entropies.
The latter in particular means that if we seek a distribution p(x,a) which minimizes the divergence from some underlying prior measure m(x,a), and we acquire new information which only affects the distribution of a, then the distribution of p(x|a) remains m(x|a), unchanged.
The other Rényi divergences satisfy the criteria of being positive and continuous; being invariant under 1-to-1 co-ordinate transformations; and of combining additively when A and X are independent, so that if p(A,X) = p(A)p(X), then

and

The stronger properties of the α = 1 quantities, which allow the definition of conditional information and mutual information from communication theory, may be very important in other applications, or entirely unimportant, depending on those applications' requirements.
Exponential families
The Rényi entropies and divergences for an exponential family admit simple expressions (Nielsen & Nock, 2011)
![H_{\alpha }(p_{F}(x;\theta ))={\frac {1}{1-\alpha }}\left(F(\alpha \theta )-\alpha F(\theta )+\log E_{p}[e^{{(\alpha -1)k(x)}}]\right)](/2014-wikipedia_en_all_02_2014/I/media/a/d/7/9/ad7974137165e58fed319c932e25fae2.png)
and

where
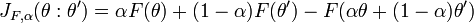
is a Jensen difference divergence.
See also
- Diversity indices
- Tsallis entropy
- Generalized entropy index
Notes
 holds because
holds because 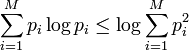 .
. holds because
holds because 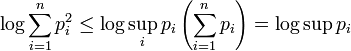 .
.
References
- Beck, Christian; Schlögl, Friedrich (1993). Thermodynamics of chaotic systems: an introduction. Cambridge University Press. ISBN 0521433673.
- Jizba, P.; Arimitsu, T. (2004). "The world according to Rényi: Thermodynamics of multifractal systems". Annals of Physics (Elsevier) 312: 17–59. arXiv:cond-mat/0207707. Bibcode:2004AnPhy.312...17J. doi:10.1016/j.aop.2004.01.002.
- Jizba, P.; Arimitsu, T. (2004). "On observability of Rényi's entropy". Physical Review E (APS) 69: 026128–1 – 026128–12. arXiv:cond-mat/0307698. Bibcode:2004PhRvE..69b6128J. doi:10.1103/PhysRevE.69.026128.
- Bromiley, P.A.; Thacker, N.A.; Bouhova-Thacker, E. (2004), Shannon Entropy, Renyi Entropy, and Information
- Franchini, F.; Its, A.R., Korepin, V.E. (2008). "Rényi entropy as a measure of entanglement in quantum spin chain". Journal of Physics A: Mathematical and Theoretical (IOPScience) 41 (25302): 025302. arXiv:0707.2534. Bibcode:2008JPhA...41b5302F. doi:10.1088/1751-8113/41/2/025302.
- Hazewinkel, Michiel, ed. (2001), "Rényi test", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- Hero, A. O.; Michael, O.; Gorman, J. (2002). Alpha-divergences for Classification, Indexing and Retrieval.
- Its, A. R.; Korepin, V. E. (2010). "Generalized entropy of the Heisenberg spin chain". Theoretical and Mathematical Physics (Springer) 164 (3): 1136–1139. Bibcode:2010TMP...164.1136I. doi:10.1007/s11232-010-0091-6. Retrieved 7 Mar 2012.
- Nielsen, Frank; Nock, Richard (2012). "A closed-form expression for the Sharma-Mittal entropy of exponential families". Journal of Physics A: Mathematical and Theoretical 45 (3): 032003. arXiv:1112.4221. Bibcode:2012JPhA...45c2003N. doi:10.1088/1751-8113/45/3/032003.
- Nielsen, Frank; Nock, Richard (2011). "On Rényi and Tsallis entropies and divergences for exponential families". Arxiv. arXiv:1105.3259. Bibcode:2011arXiv1105.3259N.
- Rényi, Alfréd (1961). "On measures of information and entropy". Proceedings of the fourth Berkeley Symposium on Mathematics, Statistics and Probability 1960. pp. 547–561.
- Rosso, O.A., "EEG analysis using wavelet-based information tools", Journal of Neuroscience Methods, 153 (2006) 163–182.
- van Erven, Tim; Harremoës, Peter (2012). "Rényi Divergence and Kullback-Leibler Divergence". Arxiv. arXiv:1206.2459. Bibcode:2012arXiv1206.2459V.