Query likelihood model
The query likelihood model is a language model used in Information Retrieval. A language model is constructed for each document in the collection. It is then possible to rank each document by the probability of specific documents given a query. This is interpreted as being the likelihood of a document being relevant given a query.
Calculating the likelihood
Using Bayes' rule, the probability  of a document
of a document  , given a query
, given a query  can be written as follows:
can be written as follows:

Since the probability of the query P(q) is the same for all documents, this can be ignored. Further, it is typical to assume that the probability of documents is uniform. Thus, P(d) is also ignored.

Documents are then ranked by the probability that a query is observed as a random sample from the document model. The multinomial unigram language model is commonly used to achieve this. We have:
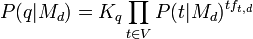 ,where the multinomial coefficient is
,where the multinomial coefficient is 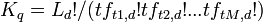 for query q.
for query q.
In practice the multinomial coefficient is usually removed from the calculation. The reason is that it is a constant for a given bag of words (such as all the words from a specific document ). The language model  should be the true language model calculated from the distribution of words underlying each retrieved document. In practice this language model is unknown, so it is usually approximated by considering each term (unigram) from the retrieved document together with its probability of appearance. So
should be the true language model calculated from the distribution of words underlying each retrieved document. In practice this language model is unknown, so it is usually approximated by considering each term (unigram) from the retrieved document together with its probability of appearance. So  is the probability of term
is the probability of term 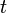 being generated by the language model of document . This probability is multiplied for all terms from query to get a rank for document in the interval
being generated by the language model of document . This probability is multiplied for all terms from query to get a rank for document in the interval ![[0,1]](/2014-wikipedia_en_all_02_2014/I/media/c/c/f/c/ccfcd347d0bf65dc77afe01a3306a96b.png) . The calculation is repeated for all documents to create a ranking of all documents in the document collection.
. The calculation is repeated for all documents to create a ranking of all documents in the document collection.
References
- ↑ Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze: An Introduction to Information Retrieval, page 241. Cambridge University Press, 2009