Quasi-Newton method
In optimization, quasi-Newton methods (a special case of variable metric methods) are algorithms for finding local maxima and minima of functions. Quasi-Newton methods are based on Newton's method to find the stationary point of a function, where the gradient is 0. Newton's method assumes that the function can be locally approximated as a quadratic in the region around the optimum, and uses the first and second derivatives to find the stationary point. In higher dimensions, Newton's method uses the gradient and the Hessian matrix of second derivatives of the function to be minimized.
In quasi-Newton methods the Hessian matrix does not need to be computed. The Hessian is updated by analyzing successive gradient vectors instead. Quasi-Newton methods are a generalization of the secant method to find the root of the first derivative for multidimensional problems. In multiple dimensions the secant equation is under-determined, and quasi-Newton methods differ in how they constrain the solution, typically by adding a simple low-rank update to the current estimate of the Hessian.
The first quasi-Newton algorithm was proposed by William C. Davidon, a physicist working at Argonne National Laboratory. He developed the first quasi-Newton algorithm in 1959: the DFP updating formula, which was later popularized by Fletcher and Powell in 1963, but is rarely used today. The most common quasi-Newton algorithms are currently the SR1 formula (for symmetric rank one), the BHHH method, the widespread BFGS method (suggested independently by Broyden, Fletcher, Goldfarb, and Shanno, in 1970), and its low-memory extension, L-BFGS. The Broyden's class is a linear combination of the DFP and BFGS methods.
The SR1 formula does not guarantee the update matrix to maintain positive-definiteness and can be used for indefinite problems. The Broyden's method does not require the update matrix to be symmetric and it is used to find the root of a general system of equations (rather than the gradient) by updating the Jacobian (rather than the Hessian).
One of the chief advantages of quasi-Newton methods over Newton's method is that the Hessian matrix (or, in the case of quasi-Newton methods, its approximation)  does not need to be inverted. Newton's method, and its derivatives such as interior point methods, require the Hessian to be inverted, which is typically implemented by solving a system of linear equations and is often quite costly. In contrast, quasi-Newton methods usually generate an estimate of
does not need to be inverted. Newton's method, and its derivatives such as interior point methods, require the Hessian to be inverted, which is typically implemented by solving a system of linear equations and is often quite costly. In contrast, quasi-Newton methods usually generate an estimate of  directly.
directly.
Description of the method
As in Newton's method, one uses a second order approximation to find the minimum of a function  .
The Taylor series of around an iterate is:
.
The Taylor series of around an iterate is:
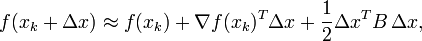
where ( ) is the gradient and an approximation to the Hessian matrix.
The gradient of this approximation (with respect to
) is the gradient and an approximation to the Hessian matrix.
The gradient of this approximation (with respect to  ) is
) is
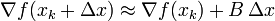
and setting this gradient to zero provides the Newton step:

The Hessian approximation is chosen to satisfy
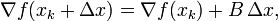
which is called the secant equation (the Taylor series of the gradient itself). In more than one dimension is under determined. In one dimension, solving for and applying the Newton's step with the updated value is equivalent to the secant method.
The various quasi-Newton methods differ in their choice of the solution to the secant equation (in one dimension, all the variants are equivalent).
Most methods (but with exceptions, such as Broyden's method) seek a symmetric solution (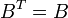 ); furthermore,
the variants listed below can be motivated by finding an update
); furthermore,
the variants listed below can be motivated by finding an update  that is as close as possible
to
that is as close as possible
to  in some norm; that is,
in some norm; that is, 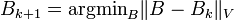 where
where  is some positive definite matrix that defines the norm.
An approximate initial value of
is some positive definite matrix that defines the norm.
An approximate initial value of  is often sufficient to achieve rapid convergence. The unknown
is often sufficient to achieve rapid convergence. The unknown  is updated applying the Newton's step calculated using the current approximate Hessian matrix
is updated applying the Newton's step calculated using the current approximate Hessian matrix
-
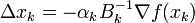 , with
, with  chosen to satisfy the Wolfe conditions;
chosen to satisfy the Wolfe conditions; -
 ;
; - The gradient computed at the new point
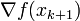 , and
, and

is used to update the approximate Hessian  , or directly its inverse
, or directly its inverse 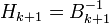 using the Sherman-Morrison formula.
using the Sherman-Morrison formula.
- A key property of the BFGS and DFP updates is that if
 is positive definite and
is positive definite and  is chosen to satisfy the Wolfe conditions then is also positive definite.
is chosen to satisfy the Wolfe conditions then is also positive definite.
The most popular update formulas are:
| Method | 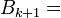 |
 |
|---|---|---|
| DFP |  |
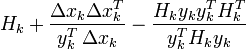 |
| BFGS | 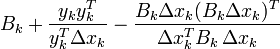 |
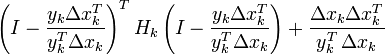 |
| Broyden |  |
 |
| Broyden family | ![(1-\varphi _{k})B_{{k+1}}^{{BFGS}}+\varphi _{k}B_{{k+1}}^{{DFP}},\qquad \varphi \in [0,1]](/2014-wikipedia_en_all_02_2014/I/media/f/a/0/b/fa0b40f635e471dac81b5ee2f76acda1.png) |
|
| SR1 | 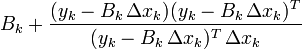 |
 |
Implementations
Owing to their success, there are implementations of quasi-Newton methods in almost all programming languages. The NAG Library contains several routines[1] for minimizing or maximizing a function[2] which use quasi-Newton algorithms.
In MATLAB's Optimization Toolbox, the fminunc function uses (among other methods) the BFGS Quasi-Newton method. Many of the constrained methods of the Optimization toolbox use BFGS and the variant L-BFGS. Many user-contributed quasi-Newton routines are available on MATLAB's file exchange.
Mathematica includes quasi-Newton solvers. R's optim general-purpose optimizer routine uses the BFGS method by using method="BFGS". In the SciPy extension to Python, the scipy.optimize.minimize function includes, among other methods, a BFGS implementation.
See also
- Newton's method in optimization
- Newton's method
- DFP updating formula
- BFGS method
- L-BFGS
- OWL-QN
- SR1 formula
- Broyden's Method
References
- ↑ The Numerical Algorithms Group. "Keyword Index: Quasi-Newton". NAG Library Manual, Mark 23. Retrieved 2012-02-09.
- ↑ The Numerical Algorithms Group. "E04 – Minimizing or Maximizing a Function". NAG Library Manual, Mark 23. Retrieved 2012-02-09.
Further reading
- Bonnans, J. F., Gilbert, J.Ch., Lemaréchal, C. and Sagastizábal, C.A. (2006), Numerical optimization, theoretical and numerical aspects. Second edition. Springer. ISBN 978-3-540-35445-1.
- William C. Davidon, Variable Metric Method for Minimization, SIOPT Volume 1 Issue 1, Pages 1–17, 1991.
- Fletcher, Roger (1987), Practical methods of optimization (2nd ed.), New York: John Wiley & Sons, ISBN 978-0-471-91547-8.
- Nocedal, Jorge & Wright, Stephen J. (1999). Numerical Optimization. Springer-Verlag. ISBN 0-387-98793-2.
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007). "Section 10.9. Quasi-Newton or Variable Metric Methods in Multidimensions". Numerical Recipes: The Art of Scientific Computing (3rd ed.). New York: Cambridge University Press. ISBN 978-0-521-88068-8.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||