Pruning (decision trees)
Pruning is a technique in machine learning that reduces the size of decision trees by removing sections of the tree that provide little power to classify instances. The dual goal of pruning is reduced complexity of the final classifier as well as better predictive accuracy by the reduction of overfitting and removal of sections of a classifier that may be based on noisy or erroneous data.
Introduction
One of the questions that arises in a decision tree algorithm is the optimal size of the final tree. A tree that is too large risks overfitting the training data and poorly generalizing to new samples. A small tree might not capture important structural information about the sample space. However, it is hard to tell when a tree algorithm should stop because it is impossible to tell if the addition of a single extra node will dramatically decrease error. This problem is known as the horizon effect. A common strategy is to grow the tree until each node contains a small number of instances then use pruning to remove nodes that do not provide additional information.[1]
Pruning should reduce the size of a learning tree without reducing predictive accuracy as measured by a test set or using cross-validation. There are many techniques for tree pruning that differ in the measurement that is used to optimize performance.
Techniques
Pruning can occur in a top down or bottom up fashion. A top down pruning will traverse nodes and trim subtrees starting at the root, while a bottom up pruning will start at the leaf nodes. Below are several popular pruning algorithms.
Reduced error pruning
One of the simplest forms of pruning is reduced error pruning. Starting at the leaves, each node is replaced with its most popular class. If the prediction accuracy is not affected then the change is kept. While somewhat naive, reduced error pruning has the advantage of simplicity and speed.
Cost complexity pruning
Cost complexity pruning generates a series of trees 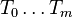 where
where  is the initial tree and
is the initial tree and  is the root alone. At step
is the root alone. At step  the tree is created by removing a subtree from tree
the tree is created by removing a subtree from tree  and replacing it with a leaf node with value chosen as in the tree building algorithm. The subtree that is removed is chosen as follows. Define the error rate of tree
and replacing it with a leaf node with value chosen as in the tree building algorithm. The subtree that is removed is chosen as follows. Define the error rate of tree  over data set
over data set 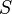 as
as  . The subtree that minimizes
. The subtree that minimizes
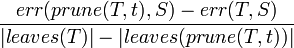 is chosen for removal. The function
is chosen for removal. The function  defines the tree gotten by pruning the subtrees
defines the tree gotten by pruning the subtrees 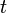 from the tree . Once the series of trees has been created, the best tree is chosen by generalized accuracy as measured by a training set or cross-validation.
from the tree . Once the series of trees has been created, the best tree is chosen by generalized accuracy as measured by a training set or cross-validation.
See also
- Alpha-beta pruning
- Artificial neural network
- Null-move heuristic
References
- Judea Pearl, Heuristics, Addison-Wesley, 1984
- Pessimistic Decision tree pruning based on Tree size[2]
- ↑ Tevor Hastie, Robert Tibshirani, and Jerome Friedman. The Elements of Statistical Learning. Springer: 2001, pp. 269-272
- ↑ Mansour, Y. (1997), "Pessimistic decision tree pruning based on tree size", Proc. 14th International Conference on Machine Learning: 195–201
Further reading
- MDL based decision tree pruning
- Decision tree pruning using backpropagation
- Neural networks