Property testing
In computer science, a property testing algorithm for a decision problem is an algorithm whose query complexity to its input is much smaller than the instance size of the problem. Typically property testing algorithms are used to decide if some mathematical object (such as a graph or a boolean function) has a "global" property, or is "far" from having this property, using only a small number of "local" queries to the object.
For example, the following promise problem admits an algorithm whose query complexity is independent of the instance size (for an arbitrary constant ε > 0):
- "Given a graph G on n vertices, decide if G is bipartite, or G cannot be made bipartite even after removing an arbitrary subset of at most
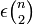 edges of G."
edges of G."
Property testing algorithms are important in the theory of probabilistically checkable proofs.
Definition and variants
Formally, a property testing algorithm with query complexity q(n) and proximity parameter ε for a decision problem L is a randomized algorithm that, on input x (an instance of L) makes at most q(|x|) queries to x and behaves as follows:
- If x is in L, the algorithm accepts x with probability at least ⅔.
- If x is ε-far from L, the algorithm rejects x with probability at least ⅔.
Here, "x is ε-far from L" means that the Hamming distance between x and any string in L is at least ε|x|.
A property testing algorithm is said to have one-sided error if it satisfies the stronger condition that the accepting probability for instances x ∈ L is 1 instead of ⅔.
A property testing algorithm is said be non-adaptive if it performs all its queries before it "observes" any answers to previous queries. Such an algorithm can be viewed as operating in the following manner. First the algorithm receives its input. Before looking at the input, using its internal randomness, the algorithm decides which symbols of the input are to be queried. Next, the algorithm observes these symbols. Finally, without making any additional queries (but possibly using its randomness), the algorithm decides whether to accept or reject the input.
Features and limitations
The main efficiency parameter of a property testing algorithm is its query complexity, which is the maximum number of input symbols inspected over all inputs of a given length (and all random choices made by the algorithm). One is interested in designing algorithms whose query complexity is as small as possible. In many cases the running time of property testing algorithms is sublinear in the instance length. Typically, the goal is first to make the query complexity as small as possible as a function of the instance size n, and then study the dependency on the proximity parameter ε.
Unlike other complexity-theoretic settings, the asymptotic query complexity of property testing algorithms is affected dramatically by the representation of instances. For example, when ε = 0.01, the problem of testing bipartiteness of dense graphs (which are represented by their adjacency matrix) admits an algorithm of constant query complexity. In contrast, sparse graphs on n vertices (which are represented by their adjacency list) require property testing algorithms of query complexity 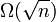 .
.
The query complexity of property testing algorithms grows as the proximity parameter ε becomes smaller for all non-trivial properties. This dependence on ε is necessary as a change of fewer than ε symbols in the input cannot be detected with constant probability using fewer than O(1/ε) queries. Many interesting properties of dense graphs can be tested using query complexity that depends only on ε and not on the graph size n. However, the query complexity can grow enormously fast as a function of ε. For example, for a long time the best known algorithm for testing if a graph does not contain any triangle had a query complexity which is a tower function of poly(1/ε), and only in 2010 this has been improved to a tower function of log(1/ε). One of the reasons for this enormous growth in bounds is that many of the positive results for property testing of graphs are established using the Szemerédi regularity lemma, which also has tower-type bounds in its conclusions.
References
- Dana Ron. Property Testing. In Handbook of Randomization, 2000.
- Ronitt Rubinfeld. Sublinear-time Algorithms. In Proceedings of the 2006 International Congress of Mathematicians.
- Oded Goldreich. Combinatorial Property Testing (a survey).
- Jacob Fox, A new proof of the graph removal lemma, to appear in Annals of Mathematics.