ProbCons
ProbCons is an open source probabilistic consistency-based multiple alignment of amino acid sequences. It is an efficient protein multiple sequence alignment program, which has demonstrated a statistically significant improvement in accuracy compared to several leading alignment tools.[1]
Algorithm
The following describes the basic outline of the ProbCons algorithm. [2]
Step 1: Reliability of an alignment edge
For every pair of sequences compute the probability that letters  and
and  are paired in
are paired in 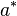 an alignment that is generated by the model.
an alignment that is generated by the model.
![{\begin{aligned}P(x_{i}\sim y_{i}|x,y)&{\stackrel {def}{=}}Pr[x_{i}\sim y_{i}{\text{ in some a }}|x,y]\\&=\sum _{{{\text{alignment a with }}x_{i}-y_{i}}}Pr[a|x,y]\\&=\sum _{{{\text{alignment a}}}}{\mathbf {1}}\{x_{i}-y_{i}\in a\}Pr[a|x,y]\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/4/9/7/a/497ae5f768fe31af9dbc15f2fba7fc42.png)
(Where  is equal to 1 if and are in the alignment and 0 otherwise.)
is equal to 1 if and are in the alignment and 0 otherwise.)
Step 2: Maximum expected accuracy
The accuracy of an alignment with respect to another alignment  is defined as the number of common aligned pairs divided by the length of the shorter sequence.
is defined as the number of common aligned pairs divided by the length of the shorter sequence.
Calculate expected accuracy of each sequence:
![{\begin{aligned}E_{{Pr[a|x,y]}}(acc(a^{*},a))&=\sum _{{a}}Pr[a|x,y]acc(a^{*},a)\\&={\frac {1}{min(|x|,|y|)}}\cdot \sum _{{a}}{\mathbf {1}}\{x_{i}\sim y_{i}\in a\}Pr[a|x,y]\\&={\frac {1}{min(|x|,|y|)}}\cdot \sum _{{x_{i}-y_{i}}}P(x_{i}\sim y_{j}|x,y)\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/f/4/7/c/f47c80458a5c3519dec0f9cca1dba8e6.png)
This yields a maximum expected accuracy (MEA) alignment:
![E(x,y)=\arg \max _{{a^{*}}}\;E_{{Pr[a|x,y]}}(acc(a^{*},a))](/2014-wikipedia_en_all_02_2014/I/media/8/5/e/8/85e811b9fc0780913c6d0390ad6a4d3c.png)
Step 3: Probabilistic Consistency Transformation
All pairs of sequences x,y from the set of all sequences  are now re-estimated using all intermediate sequences z:
are now re-estimated using all intermediate sequences z:

This step can be iterated.
Step 4: Computation of guide tree
Construct a guide tree by hierarchical clustering using MEA score as sequence similarity score. Cluster similarity is defined using weighted average over pairwise sequence similarity.
Step 5: Compute MSA
Finally compute the MSA using progressive alignment or iterative alignment.
See also
- Sequence alignment software
- Clustal
- MUSCLE
- AMAP
- T-Coffee
- Probalign
- ProbConsRNA — for nucleotide sequences
References
- ↑ Do CB, Mahabhashyam MSP, Brudno M, Batzoglou S (2005). "PROBCONS: Probabilistic Consistency-based Multiple Sequence Alignment". Genome Research 15 (2): 330–340. doi:10.1101/gr.2821705. PMC 546535. PMID 15687296.
- ↑ Lecture "Bioinformatics II" at University of Freiburg