Posterior probability
In Bayesian statistics, the posterior probability of a random event or an uncertain proposition is the conditional probability that is assigned after the relevant evidence is taken into account. Similarly, the posterior probability distribution is the probability distribution of an unknown quantity, treated as a random variable, conditional on the evidence obtained from an experiment or survey. "Posterior", in this context, means after taking into account the relevant evidence related to the particular case being examined.
Definition
The posterior probability is the probability of the parameters 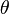 given the evidence
given the evidence  :
: 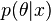 .
.
It contrasts with the likelihood function, which is the probability of the evidence given the parameters:  .
.
The two are related as follows:
Let us have a prior belief that the probability distribution function is  and observations
and observations  with the likelihood , then the posterior probability is defined as
with the likelihood , then the posterior probability is defined as

The posterior probability can be written in the memorable form as
 .
.
Example
Suppose there is a mixed school having 60% boys and 40% girls as students. The girls wear trousers or skirts in equal numbers; the boys all wear trousers. An observer sees a (random) student from a distance; all the observer can see is that this student is wearing trousers. What is the probability this student is a girl? The correct answer can be computed using Bayes' theorem.
The event  is that the student observed is a girl, and the event
is that the student observed is a girl, and the event  is that the student observed is wearing trousers. To compute
is that the student observed is wearing trousers. To compute  , we first need to know:
, we first need to know:
-
 , or the probability that the student is a girl regardless of any other information. Since the observer sees a random student, meaning that all students have the same probability of being observed, and the percentage of girls among the students is 40%, this probability equals 0.4.
, or the probability that the student is a girl regardless of any other information. Since the observer sees a random student, meaning that all students have the same probability of being observed, and the percentage of girls among the students is 40%, this probability equals 0.4. -
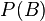 , or the probability that the student is not a girl (i.e. a boy) regardless of any other information (
, or the probability that the student is not a girl (i.e. a boy) regardless of any other information ( is the complementary event to ). This is 60%, or 0.6.
is the complementary event to ). This is 60%, or 0.6. -
 , or the probability of the student wearing trousers given that the student is a girl. As they are as likely to wear skirts as trousers, this is 0.5.
, or the probability of the student wearing trousers given that the student is a girl. As they are as likely to wear skirts as trousers, this is 0.5. -
 , or the probability of the student wearing trousers given that the student is a boy. This is given as 1.
, or the probability of the student wearing trousers given that the student is a boy. This is given as 1. -
 , or the probability of a (randomly selected) student wearing trousers regardless of any other information. Since
, or the probability of a (randomly selected) student wearing trousers regardless of any other information. Since  (via the law of total probability), this is
(via the law of total probability), this is  .
.
Given all this information, the probability of the observer having spotted a girl given that the observed student is wearing trousers can be computed by substituting these values in the formula:

Calculation
The posterior probability distribution of one random variable given the value of another can be calculated with Bayes' theorem by multiplying the prior probability distribution by the likelihood function, and then dividing by the normalizing constant, as follows:

gives the posterior probability density function for a random variable given the data  , where
, where
-
 is the prior density of ,
is the prior density of ,
-
 is the likelihood function as a function of ,
is the likelihood function as a function of ,
-
 is the normalizing constant, and
is the normalizing constant, and
-
 is the posterior density of given the data .
is the posterior density of given the data .
Classification
In classification posterior probabilities reflect the uncertainty of assessing an observation to particular class, see also Class membership probabilities. While Statistical classification methods by definition generate posterior probabilities, Machine Learners usually supply membership values which do not induce any probabilistic confidence. It is desirable to transform or re-scale membership values to class membership probabilities, since they are comparable and additionally easier applicable for post-processing.
See also
- Prediction interval
- Bernstein–von Mises theorem
- Monty Hall Problem
- Three Prisoners Problem
- Bertrand's box paradox
References
- Peter M. Lee (2004). Bayesian Statistics, an introduction (3rd ed.). Wiley. ISBN 978-0-340-81405-5.