Point set registration

In computer vision and pattern recognition, point set registration, also known as point matching, is the process of finding a spatial transformation that aligns two point sets. The purpose of finding such a transformation includes merging multiple incomplete data sets obtained by measuring the same entity from different angles or using different techniques, and mapping a new measurement to a known data set to identify features or to estimate its pose. A point set may be raw data from 3D scanning or an array of rangefinders. For use in image processing and feature-based image registration, a point set may be a set of features obtained by feature extraction from an image, for example by the SIFT algorithm. Point set registration is used in optical character recognition[1][2] and aligning data from magnetic resonance imaging with computer aided tomography scans.[3][4]
Overview of problem
The problem may be summarized as follows:[5]
Let  be two finite size point sets in a finite-dimensional real vector space
be two finite size point sets in a finite-dimensional real vector space  , which contain
, which contain  and
and  points respectively. The problem is to find a transformation to be applied to the moving "model" point set
points respectively. The problem is to find a transformation to be applied to the moving "model" point set  such that the difference between and the static "scene" set
such that the difference between and the static "scene" set 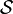 is minimized. In other words, a mapping from to is desired which yields the best alignment between the transformed "model" set and the "scene" set. The mapping may consist of a rigid or non-rigid transformation. The transformation model may be written as
is minimized. In other words, a mapping from to is desired which yields the best alignment between the transformed "model" set and the "scene" set. The mapping may consist of a rigid or non-rigid transformation. The transformation model may be written as  where the transformed, registered model point set is:
where the transformed, registered model point set is:
-

(1)
It is useful to define an optimization parameter 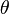 :
:
-

(2)
such that it is clear that the optimizing algorithm adjusts . Depending on the problem and number of dimensions, there may be more such parameters. The output of a point set registration algorithm is therefore the transformation parameter of model so that is optimally aligned to .
In convergence, it is desired for the distance between the two point sets to reach a global minimum. This is difficult without exhausting all possible transformations, so a local minimum suffices. The distance function between a transformed model point set and the scene point set is given by some function  . A simple approach is to take the square of the Euclidean distance for every pair of points:
. A simple approach is to take the square of the Euclidean distance for every pair of points:
-

(3)
Minimizing such a function in rigid registration is equivalent to solving a least squares problem. However, this function is sensitive to outlier data and consequently algorithms based on this function tend to be less robust against noisy data. A robuster formulation of the cost function uses some robust function 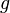 :
:
-

(4)
Such a formulation is known as an M-estimator. The robust function is chosen such that the local configuration of the point set is insensitive to distant points, hence making it robust against outliers and noise.[6]
Rigid registration
Given two point sets, rigid registration yields a rigid transformation which maps one point set to the other. A rigid transformation is defined as a transformation that does not change the distance between any two points. Typically such a transformation consists of translation and rotation.[2] In rare cases, the point set may also be mirrored.
Non-rigid registration
Given two point sets, non-rigid registration yields a non-rigid transformation which maps one point set to the other. Non-rigid transformations include affine transformations such as scaling and shear mapping. However, in the context of point set registration, non-rigid registration typically involves nonlinear transformation. If the eigenmodes of variation of the point set are known, the nonlinear transformation may be parametrized by the eigenvalues.[7] A nonlinear transformation may also be parametrized as a thin plate spline.[1][7]
Point set registration algorithms
Some approaches to point set registration use algorithms that solve the more general graph matching problem.[5] However, the computational complexity of such methods tend to be high and they are limited to rigid registrations. Algorithms specific to the point set registration problem are described in the following sections.
Iterative closest point
The iterative closest point (ICP) algorithm was introduced by Besl and McKay.[8]
The algorithm performs rigid registration in an iterative fashion by assuming that every point in corresponds with the closest point to it in , and then finding the least squares rigid transformation. As such, it works best if the initial pose of is sufficiently close to . In pseudocode, the basic algorithm is implemented as follows:
Algorithm ICP
while not registered:
:=
for
:
:= closest point in


return
Here, the function least_squares performs least squares regression to minimize the distance in each of the pairs, i.e. minimizing the distance function in Equation (3).
Because the cost function of registration depends on finding the closest point in to every point in , it can change as the algorithm is running. As such, it is difficult to prove that ICP will in fact converge exactly to the local optimum.[6] In fact, empirically, ICP and EM-ICP do not converge to the local minimum of the cost function.[6] Nonetheless, because ICP is intuitive to understand and straightforward to implement, it remains the most commonly used point set registration algorithm.[6] Many variants of ICP have been proposed, affecting all phases of the algorithm from the selection and matching of points to the minimization strategy.[7][9]
For example, the expectation maximization algorithm is applied to the ICP algorithm to form the EM-ICP method, and the Levenberg-Marquardt algorithm is applied to the ICP algorithm to form the LM-ICP method.[2]
Robust point matching
Robust point matching (RPM) was introduced by Gold et al.[10] The method performs registration using deterministic annealing and soft assignment of correspondences between point sets. Whereas in ICP the correspondence generated by the nearest-neighbour heuristic is binary, RPM uses a soft correspondence where the correspondence between any two points can be anywhere from 0 to 1, although it ultimately converges to either 0 or 1. The correspondences found in RPM is always one-to-one, which is not always the case in ICP.[1] Let be the  th point in and
th point in and  be the
be the  th point in . The match matrix
th point in . The match matrix  is defined as such:
is defined as such:
-

(rpm.1)
The problem is then defined as: Given two point sets and find the Affine transformation and the match matrix that best relates them.[10] Knowing the optimal transformation makes it easy to determine the match matrix, and vice versa. However, the RPM algorithm determines both simultaneously. The transformation may be decomposed into a translation vector and an transformation matrix:

The matrix  in 2D is composed of four separate parameters
in 2D is composed of four separate parameters  , which are scale, rotation, and the vertical and horizontal shear components respectively. The cost function is then:
, which are scale, rotation, and the vertical and horizontal shear components respectively. The cost function is then:
-

(rpm.2)
subject to  ,
,  ,
,  . The
. The  term biases the objective towards stronger correlation by decreasing the cost if the match matrix has more ones in it. The function
term biases the objective towards stronger correlation by decreasing the cost if the match matrix has more ones in it. The function  serves to regularize the Affine transformation by penalizing large valuse of the scale and shear components:
serves to regularize the Affine transformation by penalizing large valuse of the scale and shear components:

for some regularization parameter  .
.
The RPM method optimizes the cost function using the Softassign algorithm. The 1D case will be derived here. Given a set of variables  where
where  . A variable
. A variable  is associated with each
is associated with each  such that
such that  . The goal is to find that maximizes
. The goal is to find that maximizes  . This can be formulated as a continuous problem by introducing a control parameter
. This can be formulated as a continuous problem by introducing a control parameter  . In the deterministic annealing method, the control parameter
. In the deterministic annealing method, the control parameter  is slowly increased as the algorithm runs. Let be:
is slowly increased as the algorithm runs. Let be:
-

(rpm.3)
this is known as the softmax. As increases, it approaches a binary value as desired in Equation (rpm.1). The problem may now be generalized to the 2D case, where instead of maximizing , the following is maximized:
-

(rpm.4)
where

This is straightforward, except that now the constraints on  are doubly stochastic matrix constraints:
are doubly stochastic matrix constraints:  and
and  . As such the denominator from Equation (rpm.3) cannot be expressed for the 2D case simply. To satisfy the constraints, it is possible to use a result due to Sinkhorn,[10] which states that a doubly stochastic matrix is obtained from any square matrix with all positive entries by the iterative process of alternating row and column normalizations. Thus the algorithm is written as such:[10]
. As such the denominator from Equation (rpm.3) cannot be expressed for the 2D case simply. To satisfy the constraints, it is possible to use a result due to Sinkhorn,[10] which states that a doubly stochastic matrix is obtained from any square matrix with all positive entries by the iterative process of alternating row and column normalizations. Thus the algorithm is written as such:[10]
Algorithm RPM2D:= 0
:= 0

:=
while
: while
:=

:=
// apply Sinkhorn's method while
has not converged: // update
:=
// update
:=
// update pose parameters by coordinate descent update
using Newton's method

return
and
where the deterministic annealing control parameter is initially set to and increases by factor  until it reaches the maximum value
until it reaches the maximum value  . The summations in the normalization steps sum to
. The summations in the normalization steps sum to  and
and 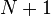 instead of just and because the constraints on are inequalities. As such the th and th elements are slack variables.
instead of just and because the constraints on are inequalities. As such the th and th elements are slack variables.
The algorithm can also be extended for point sets in 3D or higher dimensions. The constraints on the correspondence matrix are the same in the 3D case as in the 2D case. Hence the structure of the algorithm remains unchanged, with the main difference being how the rotation and translation matrices are solved.[10]
Thin plate spline robust point matching
 to the magenta point set corrupted with noisy outliers. The size of the blue circles is inversely related to the control parameter . The yellow lines indicate correspondence.
to the magenta point set corrupted with noisy outliers. The size of the blue circles is inversely related to the control parameter . The yellow lines indicate correspondence.The thin plate spline robust point matching (TPS-RPM) algorithm by Chui and Rangarajan augments the RPM method to perform non-rigid registration by parametrizing the transformation as a thin plate spline.[1] However, because the thin plate spline parametrization only exists in three dimensions, the method cannot be extended to problems involving four or more dimensions.
Kernel correlation
The kernel correlation (KC) approach of point set registration was introduced by Tsin and Kanade.[6]
Compared with ICP, the KC algorithm is more robust against noisy data. Unlike ICP, where, for every model point, only the closest scene point is considered, here every scene point affects every model point.[6] As such this is a multiply-linked registration algorithm. For some kernel function  , the kernel correlation
, the kernel correlation  of two points
of two points  is defined thus:[6]
is defined thus:[6]
-

(kc.1)
The kernel function chosen for point set registration is typically symmetric and non-negative kernel, similar to the ones used in the Parzen window density estimation. The Gaussian kernel typically used for its simplicity, although other ones like the Epanechnikov kernel and the tricube kernel may be substituted.[6] The kernel correlation of an entire point set  is defined as the sum of the kernel correlations of every point in the set to every other point in the set:[6]
is defined as the sum of the kernel correlations of every point in the set to every other point in the set:[6]
-

(kc.2)
The KC of a point set is proportional, within a constant factor, to the logarithm of entropy (information theory). Observe that the KC is a measure of a "compactness" of the point set—trivially, if all points in the point set were at the same location, the KC would evaluate to zero. The cost function of the point set registration algorithm for some transformation parameter is defined thus:
-

(kc.3)
Some algebraic manipulation yields:
-

(kc.4)
The expression is simplified by observing that  is independent of . Furthermore, assuming rigid registration, KC(T(\mathcal{M}, \theta)) is invariant when is changed because the Euclidean distance between every pair of points stays the same under rigid transformation. So the above equation may be rewritten as:
is independent of . Furthermore, assuming rigid registration, KC(T(\mathcal{M}, \theta)) is invariant when is changed because the Euclidean distance between every pair of points stays the same under rigid transformation. So the above equation may be rewritten as:
-

(kc.5)
The kernel density estimates are defined as:


The cost function can then be shown to be the correlation of the two kernel density estimates:
-

(kc.6)
Having established the cost function, the algorithm simply uses gradient descent to find the optimal transformation. It is computationally expensive to compute the cost function from scratch on every iteration, so a discrete version of the cost function Equation (kc.6) is used. The kernel density estimates  can be evaluated at grid points and stored in a lookup table. Unlike the ICP and related methods, it is not necessary to fund the nearest neighbour, which allows the KC algorithm to be comparatively simple in implementation.
can be evaluated at grid points and stored in a lookup table. Unlike the ICP and related methods, it is not necessary to fund the nearest neighbour, which allows the KC algorithm to be comparatively simple in implementation.
Compared to ICP and EM-ICP for noisy 2D and 3D point sets, the KC algorithm is less sensitive to noise and results in correct registration more often.[6]
Gaussian mixture model
The kernel density estimates are sums of Gaussians and may therefore be represented as Gaussian mixture models (GMM).[11] Jian and Vemuri use the GMM version of the KC registration algorithm to perform non-rigid registration parametrized by thin plate splines.
Coherent point drift
 to the red point set using the Coherent Point Drift algorithm. Both point sets have been corrupted with removed points and random spurious outlier points. to the red point set using the Coherent Point Drift algorithm.
to the red point set using the Coherent Point Drift algorithm. Both point sets have been corrupted with removed points and random spurious outlier points. to the red point set using the Coherent Point Drift algorithm. to the red point set using the Coherent Point Drift algorithm. Both point sets have been corrupted with removed points and random spurious outlier points.
to the red point set using the Coherent Point Drift algorithm. Both point sets have been corrupted with removed points and random spurious outlier points.Coherent point drift (CPD) was introduced by Myronenko and Song.[7][12]
The algorithm takes a probabilistic approach to aligning point sets, similar to the GMM KC method. Unlike earlier approaches to non-rigid registration which assume a thin plate spline transformation model, CPD is agnostic with regard to the transformation model used. The point set represents the Gaussian mixture model (GMM) centroids. When the two point sets are optimally aligned, the correspondence is the maximum of the GMM posterior probability for a given data point. To preserve the topological structure of the point sets, the GMM centroids are forced to move coherently as a group. The expectation maximization algorithm is used to optimize the cost function.[7]
Let there be points in and points in . The GMM probability density function for a point  is:
is:
-
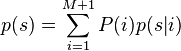
(cpd.1)
where, in  dimensions,
dimensions,  is the Gaussian distribution centered on point
is the Gaussian distribution centered on point 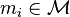 .
.

The membership probabilities  is equal for all GMM components. The weight of the uniform distribution is denoted as
is equal for all GMM components. The weight of the uniform distribution is denoted as ![w\in [0,1]](/2014-wikipedia_en_all_02_2014/I/media/c/1/b/1/c1b1b7698d2deeeb01c3d1e608be196d.png) . The mixture model is then:
. The mixture model is then:
-

(cpd.2)
The GMM centroids are re-parametrized by a set of parameters estimated by maximizing the likelihood. This is equivalent to minimizing the negative log-likelihood function:
-

(cpd.3)
where it is assumed that the data is independent and identically distributed. The correspondence probability between two points and is defined as the posterior probability of the GMM centroid given the data point:

The expectation maximization (EM) algorithm is used to find and  . The EM algorithm consists of two steps. First, in the E-step or estimation step, it guesses the values of parameters ("old" parameter values) and then uses Bayes' theorem to compute the posterior probability distributions
. The EM algorithm consists of two steps. First, in the E-step or estimation step, it guesses the values of parameters ("old" parameter values) and then uses Bayes' theorem to compute the posterior probability distributions  of mixture components. Second, in the M-step or maximization step, the "new" parameter values are then found by minimizing the expectation of the complete negative log-likelihood function, i.e. the cost function:
of mixture components. Second, in the M-step or maximization step, the "new" parameter values are then found by minimizing the expectation of the complete negative log-likelihood function, i.e. the cost function:
-

(cpd.4)
Ignoring constants independent of and 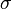 , Equation (cpd.4) can be expressed thus:
, Equation (cpd.4) can be expressed thus:
-

(cpd.5)
where

with  only if
only if  . The posterior probabilities of GMM components computed using previous parameter values
. The posterior probabilities of GMM components computed using previous parameter values  is:
is:
-

(cpd.6)
Minimizing the cost function in Equation (cpd.5) necessarily decreases the negative log-likelihood function  in Equation (cpd.3) unless it is already at a local minimum.[7] Thus, the algorithm can be expressed using the following pseudocode, where the point sets and are represented as
in Equation (cpd.3) unless it is already at a local minimum.[7] Thus, the algorithm can be expressed using the following pseudocode, where the point sets and are represented as  and
and  matrices
matrices  and
and  respectively:[7]
respectively:[7]
Algorithm CPD
while not registered: // E-step, compute
for
and
:
:=
// M-step, solve for optimal transformation
:= solve
return
where the vector  is a column vector of ones. The
is a column vector of ones. The solve function differs by the type of registration performed. For example, in rigid registration, the output is a scale  , a rotation matrix
, a rotation matrix  , and a translation vector . The parameter can be written as a tuple of these:
, and a translation vector . The parameter can be written as a tuple of these:

which is initialized to one, the identity matrix, and a column vector of zeroes:

The aligned point set is:

The solve_rigid function for rigid registration can then be written as follows, with derivation of the algebra explained in Myronenko's 2010 paper.[7]
solve_rigid:=
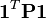
:=

:=

:=

:=


:= svd
// the singular value decomposition of

:=
//
is the diagonal matrix formed from vector


//
is the trace of a matrix
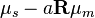
return

For affine registration, where the goal is to find an affine transformation instead of a rigid one, the output is an affine transformation matrix  and a translation such that the aligned point set is:
and a translation such that the aligned point set is:

The solve_affine function for rigid registration can then be written as follows, with derivation of the algebra explained in Myronenko's 2010 paper.[7]
solve_affine

return

It is also possible to use CPD with non-rigid registration using a parametrization derived using calculus of variation.[7]
Sums of Gaussian distributions can be computed in linear time using the fast Gauss transform (FGT).[7] Consequently, the time complexity of CPD is  , which is asymptotically much faster than
, which is asymptotically much faster than  methods.[7]
methods.[7]
External links
- Reference implementation of thin plate spline robust point matching
- Reference implementation of kernel correlation point set registration
- Reference implementation of coherent point drift
References
- ↑ 1.0 1.1 1.2 1.3 Chui, Haili; Rangarajan, Anand (2003). "A new point matching algorithm for non-rigid registration". Computer Vision and Image Understanding 89 (2): 114–141. doi:10.1016/S1077-3142(03)00009-2.
- ↑ 2.0 2.1 2.2 Fitzgibbon, Andrew W. (2003). "Robust registration of 2D and 3D point sets". Image and Vision Computing 21 (13): 1145–1153.
- ↑ Hill, Derek LG; Hawkes, D. J.; Crossman, J. E.; Gleeson, M. J.; Cox, T. C. S.; Bracey, E. E. C. M. L.; Strong, A. J.; Graves, P. (1991). "Registration of MR and CT images for skull base surgery using point-like anatomical features". British journal of radiology 64 (767): 1030–1035.
- ↑ Studholme, C.; Hill, D. L.; Hawkes, D. J. (1995). "Automated 3D Registration of Truncated MR and CT Images of the Head". Proceedings of the Sixth British Machine Vision Conference: 27–36.
- ↑ 5.0 5.1 Jian, Bing; Vemuri, Baba C. (2011). "Robust Point Set Registration Using Gaussian Mixture Models". IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (8): 1633–1645.
- ↑ 6.0 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9 Tsin, Yanghai; Kanade, Takeo (2004). "A Correlation-Based Approach to Robust Point Set Registration". Computer Vision ECCV (Springer Berlin Heidelberg): 558–569.
- ↑ 7.0 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 7.10 7.11 Myronenko, Andriy; Song, Xubo (2010). "Point set registration: Coherent Point drift". IEEE Transactions on Pattern Analysis and Machine Intelligence 32 (2): 2262–2275.
- ↑ Besl, Neil; McKay (1992). "A Method for Registration of 3-D Shapes". IEEE Transactions on Pattern Analysis and Machine Intelligence 14 (2): 239–256. doi:10.1109/34.121791.
- ↑ Rusinkiewicz, Szymon; Levoy, Marc (2001). "Efficient variants of the ICP algorithm". 3-D Digital Imaging and Modeling, 2001. Proceedings. Third International Conference on (IEEE): 145–152. doi:10.1109/IM.2001.924423.
- ↑ 10.0 10.1 10.2 10.3 10.4 Gold, Steven; Rangarajan, Anand; Lu, Chien-Ping; Suguna, Pappu; Mjolsness, Eric (1998). "New algorithms for 2d and 3d point matching:: pose estimation and correspondence". Pattern Recognition 38 (8): 1019–1031.
- ↑ Jian, Bing; Vemuri, Baba C. (2005). "A robust algorithm for point set registration using mixture of Gaussians". Tenth IEEE International Conference on Computer Vision 2005 2: 1246–1251.
- ↑ Myronenko, Andriy; Song, Xubo; Carriera-Perpinán, Miguel A. (2006). "Non-rigid point set registration: Coherent point drift". Advances in Neural Information Processing Systems: 1009–1016.