Pivotal quantity
In statistics, a pivotal quantity or pivot is a function of observations and unobservable parameters whose probability distribution does not depend on the unknown parameters [1] (also referred to as nuisance parameters). Note that a pivot quantity need not be a statistic—the function and its value can depend on the parameters of the model, but its distribution must not. If it is a statistic, then it is known as an ancillary statistic.
More formally,[2] let 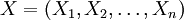 be a random sample from a distribution that depends on a parameter (or vector of parameters)
be a random sample from a distribution that depends on a parameter (or vector of parameters) 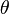 . Let
. Let 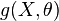 be a random variable whose distribution is the same for all . Then
be a random variable whose distribution is the same for all . Then 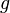 is called a pivotal quantity (or simply a pivotal).
is called a pivotal quantity (or simply a pivotal).
Pivotal quantities are commonly used for normalization to allow data from different data sets to be compared. It is relatively easy to construct pivots for location and scale parameters: for the former we form differences so that location cancels, for the latter ratios so that scale cancels.
Pivotal quantities are fundamental to the construction of test statistics, as they allow the statistic to not depend on parameters – for example, Student's t-statistic is for a normal distribution with unknown variance (and mean). They also provide one method of constructing confidence intervals, and the use of pivotal quantities improves performance of the bootstrap. In the form of ancillary statistics, they can be used to construct frequentist prediction intervals (predictive confidence intervals).
Examples
Normal distribution
One of the simplest pivotal quantities is the z-score; given a normal distribution with  and variance
and variance  , and an observation x, the z-score:
, and an observation x, the z-score:
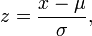
has distribution  – a normal distribution with mean 0 and variance 1. Similarly, since the n-sample sample mean has sampling distribution
– a normal distribution with mean 0 and variance 1. Similarly, since the n-sample sample mean has sampling distribution  the z-score of the mean
the z-score of the mean
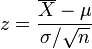
also has distribution  Note that while these functions depend on the parameters – and thus one can only compute them if the parameters are known (they are not statistics) – the distribution is independent of the parameters.
Note that while these functions depend on the parameters – and thus one can only compute them if the parameters are known (they are not statistics) – the distribution is independent of the parameters.
Given  independent, identically distributed (i.i.d.) observations from the normal distribution with unknown mean and variance , a pivotal quantity can be obtained from the function:
independent, identically distributed (i.i.d.) observations from the normal distribution with unknown mean and variance , a pivotal quantity can be obtained from the function:

where
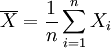
and

are unbiased estimates of and , respectively. The function 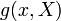 is the Student's t-statistic for a new value
is the Student's t-statistic for a new value  , to be drawn from the same population as the already observed set of values
, to be drawn from the same population as the already observed set of values  .
.
Using  the function
the function  becomes a pivotal quantity, which is also distributed by the Student's t-distribution with
becomes a pivotal quantity, which is also distributed by the Student's t-distribution with  degrees of freedom. As required, even though appears as an argument to the function , the distribution of does not depend on the parameters or
degrees of freedom. As required, even though appears as an argument to the function , the distribution of does not depend on the parameters or 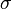 of the normal probability distribution that governs the observations
of the normal probability distribution that governs the observations 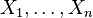 .
.
This can be used to compute a prediction interval for the next observation  see Prediction interval: Normal distribution.
see Prediction interval: Normal distribution.
Bivariate normal distribution
In more complicated cases, it is impossible to construct exact pivots. However, having approximate pivots improves convergence to asymptotic normality.
Suppose a sample of size of vectors  is taken from a bivariate normal distribution with unknown correlation
is taken from a bivariate normal distribution with unknown correlation  .
.
An estimator of is the sample (Pearson, moment) correlation

where 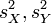 are sample variances of and
are sample variances of and  . The sample statistic
. The sample statistic  has an asymptotically normal distribution:
has an asymptotically normal distribution:
 .
.
However, a variance-stabilizing transformation

known as Fisher's z transformation of the correlation coefficient allows to make the distribution of  asymptotically independent of unknown parameters:
asymptotically independent of unknown parameters:

where  is the corresponding population parameter. For finite samples sizes , the random variable will have distribution closer to normal than that of . An even closer approximation to the standard normal distribution is obtained by using a better approximation for the exact variance: the usual form is
is the corresponding population parameter. For finite samples sizes , the random variable will have distribution closer to normal than that of . An even closer approximation to the standard normal distribution is obtained by using a better approximation for the exact variance: the usual form is

Robustness
From the point of view of robust statistics, pivotal quantities are robust to changes in the parameters – indeed, independent of the parameters – but not in general robust to changes in the model, such as violations of the assumption of normality. This is fundamental to the robust critique of non-robust statistics, often derived from pivotal quantities: such statistics may be robust within the family, but are not robust outside it.
See also
References
- ↑ Shao, J.: Mathematical Statistics, Springer, New York, 2003, ISBN 978-0-387-95382-3 (Section 7.1)
- ↑ Morris H. DeGroot, Mark J. Schervish: Probability and Statistics (4th Edition), Pearson, 2011 (page 489)