Partition problem
In computer science, the partition problem is the task of deciding whether a given multiset S of positive integers can be partitioned into two subsets S1 and S2 such that the sum of the numbers in S1 equals the sum of the numbers in S2. Although the partition problem is NP-complete, there is a pseudo-polynomial time dynamic programming solution, and there are heuristics that solve the problem in many instances, either optimally or approximately. For this reason, it has been called "The Easiest Hard Problem".[1]
There is an optimization version of the partition problem, which is to partition the multiset S into two subsets S1, S2 such that the difference between the sum of elements in S1 and the sum of elements in S2 is minimized.
Examples
Given S = {3,1,1,2,2,1}, a valid solution to the partition problem is the two sets S1 = {1,1,1,2} and S2 = {2,3}. Both sets sum to 5, and they partition S. Note that this solution is not unique. S1 = {3,1,1} and S2 = {2,2,1} is another solution.
Not every multiset of positive integers has a partition into two halves with equal sum. An example of such a set is S = {2,5,1,11,3,5,10,24,555,123,985,1337,9,13,24,89,19,27}.
Pseudo-polynomial time algorithm
The problem can be solved using dynamic programming when the size of the set and the size of the sum of the integers in the set are not too big to render the storage requirements infeasible.
Suppose the input to the algorithm is a list of the form:
- S = x1, ..., xn
Let N be the sum of all elements in S. That is: N = x1 + ... + xn. We will build an algorithm that determines if there is a subset of S that sums to 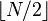 . If there is a subset, then:
. If there is a subset, then:
- if N is even, the rest of S also sums to
- if N is odd, then the rest of S sums to
 . This is as good a solution as possible.
. This is as good a solution as possible.
Recurrence relation
We wish to determine if there is a subset of S that sums to . Let:
- p(i, j) be True if a subset of { x1, ..., xj } sums to i and False otherwise.
Then p(, n) is True if and only if there is a subset of S that sums to . The goal of our algorithm will be to compute p(, n). In aid of this, we have the following recurrence relation:
- p(i, j) is True if either p(i, j − 1) is True or if p(i − xj, j − 1) is True
- p(i, j) is False otherwise
The reasoning for this is as follows: there is some subset of S that sums to i using numbers
- x1, ..., xj
if and only if either of the following is true:
- There is a subset of { x1, ..., xj } that does not use xj and that sums to i
- There is a subset of { x1, ..., xj } that does not use xj and that sums to i − xj (since xj + that subset's sum = i)
The pseudo-polynomial algorithm
The algorithm is to build up a table of size by n containing the values of the recurrence. Once the entire table is filled in, return P(, n). Below is a picture of the table P. There is a purple arrow from one block to another if the value of the target-block might depend on the value of the source-block. This dependence is a property of the recurrence relation.

INPUT: A list of integers S OUTPUT: True if S can be partitioned into two subsets that have equal sum 1 function find_partition( S ): 2 n ← |S| 3 N ← sum(S) 4 P ← empty boolean table of size (
C# code:
//pseudo-polynomial algorithm
public static bool balancePatition(int[] S)
{
var n = S.Length;
var N = S.Sum();
bool[,] P = new bool[N / 2 + 1, n + 1];
for (int i = 0; i < n + 1; i++)
P[0, i] = true;
for (int i = 1; i < N / 2 + 1; i++)
P[i, 0] = false;
for (int i = 1; i <= N / 2; i++)
for (int j = 1; j <= n; j++)
P[i, j] = S[j - 1] <= i ? P[i, j - 1] || P[i - S[j - 1], j - 1] : P[i, j - 1];
return P[N / 2, n];
}
Example
Below is the table P for the example set used above S = {3, 1, 1, 2, 2, 1}:

Runtime
This algorithm runs in time  , where
, where  is the number of elements in the input set and
is the number of elements in the input set and  is the sum of elements in the input set.
is the sum of elements in the input set.
Special case of the subset-sum problem
The partition problem can be viewed as a special case of the subset sum problem and the pseudo-polynomial time dynamic programming solution given above generalizes to a solution for the subset sum problem.
Approximation algorithm approaches
The greedy algorithm
One approach to the problem, imitating the way children choose teams for a game, is the greedy algorithm, which iterates through the numbers in descending order, assigning each of them to whichever subset has the smaller sum. This works well when the numbers in the set are of about the same size as its cardinality or less. This approach has a running time of 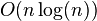 . An example of a set upon which this heuristic "breaks" is:
. An example of a set upon which this heuristic "breaks" is:
- S = {5, 5, 4, 3, 3}
For the above input, the greedy approach would build sets S1 = {5, 4} and S2 = {5, 3, 3} which are not a solution to the partition problem. The solution is S1 = {5, 5} and S2 = {4, 3, 3}.
This greedy approach is known to give a 4/3-approximation to the optimal solution of the optimization version (if the greedy algorithm gives two sets  , then
, then  ). Below is pseudocode for the greedy algorithm.
). Below is pseudocode for the greedy algorithm.
INPUT: A list of integers S
OUTPUT: An attempt at a partition of S into two sets of equal sum
1 function find_partition( S ):
2 A ← {}
3 B ← {}
4 sort S in descending order
5 for i in S:
6 if sum(A) <= sum(B)
7 add element i to set A
8 else
9 add element i to set B
10 return {A, B}
This algorithm can be extended to take the  largest elements, and for each partition of them, extends the partition by adding the remaining elements successively to whichever set is smaller. (The simple version above corresponds to
largest elements, and for each partition of them, extends the partition by adding the remaining elements successively to whichever set is smaller. (The simple version above corresponds to 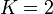 .) This version runs in time
.) This version runs in time 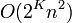 and is known to give a
and is known to give a 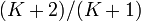 approximation; thus we have a polynomial-time approximation scheme (PTAS) for the number partition problem, though this is not a fully polynomial time approximation scheme (the running time is exponential in the desired approximation guarantee). However, there are variations of this idea that are fully polynomial-time approximation schemes for the subset-sum problem, and hence for the partition problem as well.[2][3]
approximation; thus we have a polynomial-time approximation scheme (PTAS) for the number partition problem, though this is not a fully polynomial time approximation scheme (the running time is exponential in the desired approximation guarantee). However, there are variations of this idea that are fully polynomial-time approximation schemes for the subset-sum problem, and hence for the partition problem as well.[2][3]
Differencing algorithm
Another heuristic, due to Narendra Karmarkar and Richard Karp,[4] is the differencing algorithm, which at each step removes two numbers from the set and replaces them by their difference. This represents the decision to put the two numbers in different sets, without immediately deciding which one is in which set. The differencing heuristic performs better than the greedy one, but is still bad for instances where the numbers are exponential in the size of the set.[1]
Java code:
int karmarkarKarpPartition( int[] baseArr ){
// create max heap
PriorityQueue<Integer> heap = new PriorityQueue<Integer>(baseArr.length, REVERSE_INT_CMP);
for( int value : baseArr ){
heap.add( value );
}
while( heap.size() > 1 ){
int val1 = heap.poll();
int val2 = heap.poll();
heap.add( val1 - val2 );
}
return heap.poll();
}
Other approaches
There are also anytime algorithms, based on the differencing heuristic, that first find the solution returned by the differencing heuristic, then find progressively better solutions as time allows (possibly requiring exponential time to reach optimality, for the worst instances).[5]
Hard instances
Sets with only one, or no partitions tend to be hardest (or most expensive) to solve compared to their input sizes. When the values are small compared to the size of the set, perfect partitions are more likely. The problem is known to undergo a "phase transition"; being likely for some sets and unlikely for others. If m is the number of bits needed to express any number in the set and n is the size of the set then 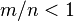 tends to have many solutions and
tends to have many solutions and 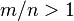 tends to have few or no solutions. As n and m get larger, the probability of a perfect partition goes to 1 or 0 respectively. This was originally argued based on empirical evidence by Gent and Walsh,[6] then using methods from statistical physics by Mertens,[7] and later proved by Borgs, Chayes, and Pittel.[8]
tends to have few or no solutions. As n and m get larger, the probability of a perfect partition goes to 1 or 0 respectively. This was originally argued based on empirical evidence by Gent and Walsh,[6] then using methods from statistical physics by Mertens,[7] and later proved by Borgs, Chayes, and Pittel.[8]
The k-partition problem
There is a problem called the 3-partition problem which is to partition the set S into |S|/3 triples each with the same sum. The 3-partition problem is quite different than the Partition Problem and has no pseudo-polynomial time algorithm unless P = NP.[9] For generalizations of the partition problem, see the Bin packing problem.
Alternative forms of the problem
An interesting related problem, somewhat similar to the Birthday paradox is that of determining the size of the input set so that we have a probability of one half that there is a solution, under the assumption that each element in the set is randomly selected with uniform distribution between 1 and some given value.
The problem is interesting in that the solution can be counter-intuitive (like the Birthday paradox). For example, with elements randomly selected in between 1 and one million, many people's intuition is that the answer is in the thousands, tens, or even hundreds of thousands, whereas the correct answer is approximately 23 (see Birthday problem#Partition problem for details).
See also
Notes
- ↑ 1.0 1.1 Hayes 2002
- ↑ Hans Kellerer; Ulrich Pferschy; David Pisinger (2004), Knapsack problems, Springer, p. 97, ISBN 9783540402862
- ↑ Martello, Silvano; Toth, Paolo (1990). "4 Subset-sum problem". Knapsack problems: Algorithms and computer interpretations. Wiley-Interscience. pp. 105–136. ISBN 0-471-92420-2. MR 1086874.
- ↑ Karmarkar & Karp 1982
- ↑ Korf 1998, Mertens 1999
- ↑ Gent & Walsh 1996
- ↑ Mertens 1998, Mertens 2001
- ↑ Borgs, Chayes & Pittel 2001
- ↑ Garey, Michael; Johnson, David (1979). Computers and Intractability; A Guide to the Theory of NP-Completeness. pp. 96–105. ISBN 0-7167-1045-5.
References
- Hayes, Brian (May–June 2002), "The Easiest Hard Problem", American Scientist
- Karmarkar, Narenda; Karp, Richard M (1982), "The Differencing Method of Set Partitioning", Technical Report UCB/CSD 82/113 (University of California at Berkeley: Computer Science Division (EECS))
- Gent, Ian; Walsh, Toby (August 1996), "Phase Transitions and Annealed Theories: Number Partitioning as a Case Study", in Wolfgang Wahlster, Proceedings of 12th European Conference on Artificial Intelligence, ECAI-96, John Wiley and Sons, pp. 170–174
- Gent, Ian; Walsh, Toby (1998), "Analysis of Heuristics for Number Partitioning", Computational Intelligence 14 (3): 430–451, doi:10.1111/0824-7935.00069
- Mertens, Stephan (November 1998), "Phase Transition in the Number Partitioning Problem", Physical Review Letters 81 (20): 4281, arXiv:cond-mat/9807077, Bibcode:1998PhRvL..81.4281M, doi:10.1103/PhysRevLett.81.4281, retrieved 2009-10-03
- Mertens, Stephan (2001), "A physicist's approach to number partitioning", Theoretical Computer Science 265 (1-2): 79–108, doi:10.1016/S0304-3975(01)00153-0
- Mertens, Stephan (2006), "The Easiest Hard Problem: Number Partitioning", in Allon Percus; Gabriel Istrate; Cristopher Moore, Computational complexity and statistical physics, Oxford University Press US, p. 125, arXiv:cond-mat/0310317, Bibcode:2003cond.mat.10317M, ISBN 9780195177374
- Borgs, Christian; Chayes, Jennifer; Pittel, Boris (2001), "Phase transition and finite-size scaling for the integer partitioning problem", Random Structures and Algorithms 19 (3-4): 247–288, doi:10.1002/rsa.10004, retrieved 2009-10-04
- Korf, Richard E. (1998), "A complete anytime algorithm for number partitioning", Artificial Intelligence 106 (2): 181–203, doi:10.1016/S0004-3702(98)00086-1, ISSN 0004-3702, retrieved 2009-10-04
- Mertens, Stephan (1999), A complete anytime algorithm for balanced number partitioning, arXiv:cs/9903011, Bibcode:1999cs........3011M