Network controllability
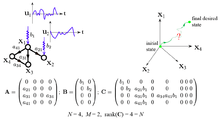
Network Controllability is concerned about the structural controllability of a network. Controllability describes our ability to guide a dynamical system from any initial state to any desired final state in finite time, with a suitable choice of inputs. This definition agrees well with our intuitive notion of control. The controllability of general directed and weighted complex networks has recently been the subject of intense study by a number of groups, worldwide.
Background
Consider the canonical linear time-invariant dynamics on a complex network
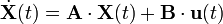 where the vector
where the vector 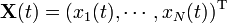 captures the state of a system of
captures the state of a system of  nodes at time
nodes at time 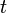 . The
. The 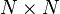 matrix
matrix  describes the system's wiring digram and the interaction strength between the components. The
describes the system's wiring digram and the interaction strength between the components. The 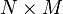 matrix
matrix  identifies the nodes controlled by an outside controller. The system is controlled through the time dependent input vector
identifies the nodes controlled by an outside controller. The system is controlled through the time dependent input vector 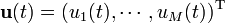 that the controller imposes on the system. To identify the minimum number of driver nodes, denoted by
that the controller imposes on the system. To identify the minimum number of driver nodes, denoted by  , whose control is sufficient to fully control the system's dynamics, Liu et al.[2] attempted to combine the tools from structural control theory, graph theory and statistical physics. They showed[2] that the minimum number of inputs or driver nodes needed to maintain full control of the network is determined by the 'maximum matching’ in the network, that is, the maximum set of links that do not share start or end nodes. They tried[2] to develop an analytical framework, based on the in-out degree distribution, which predicts
, whose control is sufficient to fully control the system's dynamics, Liu et al.[2] attempted to combine the tools from structural control theory, graph theory and statistical physics. They showed[2] that the minimum number of inputs or driver nodes needed to maintain full control of the network is determined by the 'maximum matching’ in the network, that is, the maximum set of links that do not share start or end nodes. They tried[2] to develop an analytical framework, based on the in-out degree distribution, which predicts  for scale-free and Erdős–Rényi Graphs. It is however notable, that their formulation[2] would predict same values of
for scale-free and Erdős–Rényi Graphs. It is however notable, that their formulation[2] would predict same values of  for a chain graph and for a weak densely connected graph. Obviously, both these graphs have very different in and out degree distributions. A recent unpublished work,[3] questions whether degree, which is a purely local measure in networks, would completely describe controllability and whether even slightly distant nodes would have no role in deciding network controllability. Indeed, for many real-word networks, namely, food webs, neuronal and metabolic networks, the mismatch in values of
for a chain graph and for a weak densely connected graph. Obviously, both these graphs have very different in and out degree distributions. A recent unpublished work,[3] questions whether degree, which is a purely local measure in networks, would completely describe controllability and whether even slightly distant nodes would have no role in deciding network controllability. Indeed, for many real-word networks, namely, food webs, neuronal and metabolic networks, the mismatch in values of 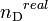 and
and 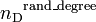 calculated by Liu et al.[2] is notable. It is obvious that if controllability is decided mainly by degree, why are and so different for many real world networks? They argued [2] (arXiv:1203.5161v1), that this might be due to the effect of degree correlations. However, it has been shown[3] that network controllability can be altered only by using betweenness centrality and closeness centrality, without using degree (graph theory) or degree correlations at all.
calculated by Liu et al.[2] is notable. It is obvious that if controllability is decided mainly by degree, why are and so different for many real world networks? They argued [2] (arXiv:1203.5161v1), that this might be due to the effect of degree correlations. However, it has been shown[3] that network controllability can be altered only by using betweenness centrality and closeness centrality, without using degree (graph theory) or degree correlations at all.
Structural Controllability
The concept of the structural properties was first introduced by Lin (1974)[1] and then extended by Shields and Pearson (1976)[4] and alternatively derived by Glover and Silverman (1976).[5] The main question is whether the lack of controllability or observability are generic with respect to the variable system parameters. In the framework of structural control the system parameters are either independent free variables or fixed zeros. This is consistent for models of physical systems since parameter values are never known exactly, with the exception of zero values which express the absence of interactions or connections.
Maximum Matching
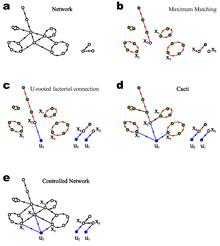
In graph theory, a matching is a set of edges without common vertices. Liu et al.[2] extended this definition to directed graph, where a matching is a set of directed edges that do not share start or end vertices. It is easy to check that a matching of a directed graph composes of a set of vertex-disjoint simple paths and cycles. The maximum matching of a directed network can be efficiently calculated by working in the bipartite representation using the classical Hopcroft–Karp algorithm, which runs in O(E√N) time in the worst case. For undirected graph, analytical solutions of the size and number of maximum matchings have been studied using the cavity method developed in statistical physics.[6] Liu et al.[2] extended the calculations for directed graph.
By calculating the maximum matchings of a wide range of real networks, Liu et al.[2] asserted that the number of driver nodes is determined mainly by the networks degree distribution  . They also calculated the average number of driver nodes for a network ensemble with arbitrary degree distribution using the cavity method. It is interesting that for a chain graph and a weak densely connected graph, both of which have very different in and out degree distributions; the formulation of Liu et al.[2] would predict same values of . Also, for many real-word networks, namely, food webs, neuronal and metabolic networks, the mismatch in values of and calculated by Liu et al.[2] is notable. If controllability is decided purely by degree, why are and so different for many real world networks? It remains open to scrutiny whether control robustness" in networks is influenced more by using betweenness centrality and closeness centrality[3] over degree (graph theory) based metrics.
. They also calculated the average number of driver nodes for a network ensemble with arbitrary degree distribution using the cavity method. It is interesting that for a chain graph and a weak densely connected graph, both of which have very different in and out degree distributions; the formulation of Liu et al.[2] would predict same values of . Also, for many real-word networks, namely, food webs, neuronal and metabolic networks, the mismatch in values of and calculated by Liu et al.[2] is notable. If controllability is decided purely by degree, why are and so different for many real world networks? It remains open to scrutiny whether control robustness" in networks is influenced more by using betweenness centrality and closeness centrality[3] over degree (graph theory) based metrics.
While sparser graphs are more difficult to control,[2][3] it would obviously be interesting to find whether betweenness centrality and closeness centrality[3] or degree heterogeneity[2] plays a more important role in deciding controllability of sparse graphs with almost similar degree distributions.
Future Directions
This recent immense activity inspires hope of new breakthroughs in structural controllability of complex networks.
See also
References
- ↑ 1.0 1.1 C.-T. Lin, IEEE Trans. Auto. Contr. 19 (1974).
- ↑ 2.0 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.10 2.11 2.12 Y.-Y. Liu, J.-J. Slotine, A.-L. Barabási, Nature 473 (2011).
- ↑ 3.0 3.1 3.2 3.3 3.4 SJ Banerjee and S Roy, ARXIV:1209.3737
- ↑ R. W. Shields and J. B. Pearson, IEEE Trans. Auto. Contr. 21 (1976).
- ↑ K. Glover and L. M. Silverman, IEEE Trans. Auto. Contr. 21 (1976).
- ↑ L. Zdeborova and M. Mezard, J. Stat. Mech. 05 (2006).
External links