NVIDIA Fermi architecture
Overview
The Fermi architecture is the penultimate NVIDIA architecture, the very last being the Kepler one. Fermi Graphic Processing Units (GPUs) feature 3.0 billion transistors and a schematic is sketched in Fig. 1.
Streaming Multiprocessor (SM): composed by 32 CUDA cores (see Streaming Multiprocessor and CUDA core sections).
GigaThread globlal scheduler: distributes thread blocks to SM thread schedulers and manages the context switches between threads during execution (see Warp Scheduling section).
Host interface: connects the GPU to the CPU via a PCI-Express v2 bus (peak transfer rate of 8GB/s).
DRAM: supported up to 6GB of GDDR5 DRAM memory thanks to the 64-bit addressing capability (see Memory Architecture section).
Clock frequency: 1.5GHz (not released by NVIDIA, but estimated by Insight 64).
Peak performance: 1.5 TFlops.
Global memory clock: 2GHz.
DRAM bandwidth: 192GB/s.
Convention in figures: orange - scheduling and dispatch; green - execution; light blue -registers and caches.
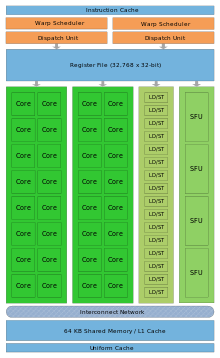
Streaming Multiprocessor
Each SM features 32 single-precision CUDA cores, 16 load/store units, four Special Function Units (SFUs), a 64KB block of high speed on-chip memory (see L1+Shared Memory subsection) and an interface to the L2 cache (see L2 Cache subsection).
Load/Store Units: Allow source and destination addresses to be calculated for 16 threads per clock. Load and store the data from/to cache or DRAM.
Special Functions Units (SFUs): Execute transcendental instructions such as sin, cosine, reciprocal, and square root. Each SFU executes one instruction per thread, per clock; a warp executes over eight clocks. The SFU pipeline is decoupled from the dispatch unit, allowing the dispatch unit to issue to other execution units while the SFU is occupied.
CUDA core
Integer Arithmetic Logic Unit (ALU): Supports full 32-bit precision for all instructions, consistent with standard programming language requirements. It is also optimized to efficiently support 64-bit and extended precision operations.
Floating Point Unit (FPU): Implements the new IEEE 754-2008 floating-point standard, providing the fused multiply-add (FMA) instruction (see Fused Multiply-Add subsection) for both single and double precision arithmetic. Up to 16 double precision fused multiply-add operations can be performed per SM, per clock.
Fused Multiply-Add
Fused Multiply-Add (FMA) perform multiplication and addition (i.e., A*B+C) with a single final rounding step, with no loss of precision in the addition. FMA is more accurate than performing the operations separately.
Warp Scheduling
The Fermi architecture uses a two-level, distributed thread scheduler.
Each SM can issue instructions consuming any two of the four green execution columns shown in the schematic Fig. 1. For example, the SM can mix 16 operations from the 16 first column cores with 16 operations from the 16 second column cores, or 16 operations from the load/store units with four from SFUs, or any other combinations the program specifies.
Note that 64-bit floating point operations consumes both the first two execution columns. This implies that an SM can issue up to 32 single-precision (32-bit) floating point operations or 16 double-precision (64-bit) floating point operations at a time.
GigaThread Engine: The GigaThread engine schedules thread blocks to various SMs
Dual Warp Scheduler: At the SM level, each warp scheduler distributes warps of 32 threads to its execution units. Threads are scheduled in groups of 32 threads called warps. Each SM features two warp schedulers and two instruction dispatch units, allowing two warps to be issued and executed concurrently. The dual warp scheduler selects two warps, and issues one instruction from each warp to a group of 16 cores, 16 load/store units, or 4 SFUs. Most instructions can be dual issued; two integer instructions, two floating instructions, or a mix of integer, floating point, load, store, and SFU instructions can be issued concurrently. Double precision instructions do not support dual dispatch with any other operation.
Memory
L1 cache per SM and unified L2 cache that services all operations (load, store and texture).
Registers: Each SM has 32KB of registers. Each thread has access to its own registers and not those of other threads. The maximum number of registers that can be used by a CUDA kernel is 63. The number of available registers degrades gracefully from 63 to 21 as the workload (and hence resource requirements) increases by number of threads. Registers have a very high bandwidth: about 8,000 GB/s.
L1+Shared Memory: On-chip memory that can be used either to cache data for individual threads (register spilling/L1 cache) and/or to share data among several threads (shared memory). This 64 KB memory can be configured as either 48 KB of shared memory with 16 KB of L1 cache, or 16 KB of shared memory with 48 KB of L1 cache. Shared memory enables threads within the same thread block to cooperate, facilitates extensive reuse of on-chip data, and greatly reduces off-chip traffic. Shared memory is accessible by the threads in the same thread block. It provides low-latency access (10-20 cycles) and very high bandwidth (1,600 GB/s) to moderate amounts of data (such as intermediate results in a series of calculations, one row or column of data for matrix operations, a line of video, etc.). David Patterson says that this Shared Memory uses idea of local scratchpad[1]
Local Memory: Local memory is meant as a memory location used to hold “spilled” registers. Register spilling occurs when a thread block requires more register storage than is available on an SM. Local memory is used only for some automatic variables (which are declared in the device code without any of the __device__, __shared__, or __constant__ qualifiers). Generally, an automatic variable resides in a register except for the following: • Arrays that the compiler cannot determine are indexed with constant quantities; • Large structures or arrays that would consume too much register space; Any variable the compiler decides to spill to local memory when a kernel uses more registers than are available on the SM.
L2 Cache: 768 KB unified L2 cache, shared among the 16 SMs, that services all load and store from/to global memory, including copies to/from CPU host, and also texture requests. The L2 cache subsystem also implements atomic operations, used for managing access to data that must be shared across thread blocks or even kernels.
Global Memory: Accessible by all threads as well as host (CPU). High latency (400-800 cycles)
References
- ↑ Patterson, David (September 30, 2009 ). "The Top 10 Innovations in the New NVIDIA Fermi Architecture, and the Top 3 Next Challenges " (in English). Parallel Computing Research Laboratory & NVIDIA. Retrieved 3 October 2013.
[1] "NVIDIA’s Next Generation CUDA Compute Architecture: Fermi." http://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
[2] N. Brookwood, "NVIDIA Solves the GPU Computing Puzzle." http://www.nvidia.com/content/PDF/fermi_white_papers/N.Brookwood_NVIDIA_Solves_the_GPU_Computing_Puzzle1.pdf
[3] P.N. Glaskowsky, "NVIDIA’s Fermi: The First Complete GPU Computing Architecture." http://www.nvidia.com/content/PDF/fermi_white_papers/P.Glaskowsky_NVIDIA's_Fermi-The_First_Complete_GPU_Architecture.pdf
[4] N. Whitehead, A. Fit-Florea, "Precision & Performance: Floating Point and IEEE 754 Compliance for NVIDIA GPUs." http://developer.download.nvidia.com/assets/cuda/files/NVIDIA-CUDA-Floating-Point.pdf, 2011.
[5] S.F. Oberman, M. Siu, "A high-performance area-efficient multifunction interpolator," Proc. of the 17th IEEE Symposium on Computer Arithmetic, Cap Cod, MA, USA, Jul. 27-29, 2005, pp. 272–279.
[6] R. Farber, "CUDA Application Design and Development," Morgan Kaufmann, 2011.
[7] NVIDIA Application Note "Tuning CUDA applications for Fermi".
External links
- NVIDIA Fermi Architecture on Orange Owl Solutions
- Patterson, David (September 30, 2009 ). "The Top 10 Innovations in the New NVIDIA Fermi Architecture, and the Top 3 Next Challenges " (in English). Parallel Computing Research Laboratory & NVIDIA. Retrieved 3 October 2013.