Multivariate random variable
In mathematics, probability, and statistics, a multivariate random variable or random vector is a list of mathematical variables each of whose value is unknown, either because the value has not yet occurred or because there is imperfect knowledge of its value. The individual variables in a random vector are grouped together because there may be correlations among them — often they represent different properties of an individual statistical unit (e.g. a particular person, event, etc.). Normally each element of a random vector is a real number.
Random vectors are often used as the underlying implementation of various types of aggregate random variables, e.g. a random matrix, random tree, random sequence, random process, etc.
More formally, a multivariate random variable is a column vector 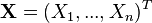 (or its transpose, which is a row vector) whose components are scalar-valued random variables on the same probability space
(or its transpose, which is a row vector) whose components are scalar-valued random variables on the same probability space 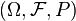 , where
, where  is the sample space,
is the sample space,  is the sigma-algebra (the collection of all events), and
is the sigma-algebra (the collection of all events), and  is the probability measure (a function returning each event's probability).
is the probability measure (a function returning each event's probability).
Probability distribution
Every random vector gives rise to a probability measure on  with the Borel algebra as the underlying sigma-algebra. This measure is also known as the joint probability distribution, the joint distribution, or the multivariate distribution of the random vector.
with the Borel algebra as the underlying sigma-algebra. This measure is also known as the joint probability distribution, the joint distribution, or the multivariate distribution of the random vector.
The distributions of each of the component random variables  are called marginal distributions. The conditional probability distribution of given
are called marginal distributions. The conditional probability distribution of given 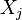 is the probability distribution of when is known to be a particular value.
is the probability distribution of when is known to be a particular value.
Operations on random vectors
Random vectors can be subjected to the same kinds of algebraic operations as can non-random vectors: addition, subtraction, multiplication by a scalar, and the taking of inner products.
Similarly, a new random vector 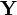 can be defined by applying an affine transformation
can be defined by applying an affine transformation 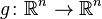 to a random vector
to a random vector  :
:
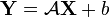 , where
, where  is an
is an 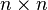 matrix and
matrix and  is an
is an 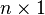 column vector.
column vector.
If is invertible and the probability density of 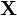 is
is 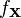 , then the probability density of is
, then the probability density of is
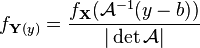 .
.
Expected value, covariance, and cross-covariance
The expected value or mean of a random vector is a fixed vector ![\operatorname {E}[{\mathbf {X}}]](/2014-wikipedia_en_all_02_2014/I/media/2/9/2/5/29255185cf211026bf3ea7dc4e71c1ac.png) whose elements are the expected values of the respective random variables.
whose elements are the expected values of the respective random variables.
The covariance matrix (also called the variance-covariance matrix) of an random vector is an matrix whose 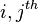 element is the covariance between the
element is the covariance between the 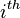 and the
and the  random variables. The covariance matrix is the expected value, element by element, of the matrix computed as
random variables. The covariance matrix is the expected value, element by element, of the matrix computed as ![[{\mathbf {X}}-\operatorname {E}[{\mathbf {X}}]][{\mathbf {X}}-\operatorname {E}[{\mathbf {X}}]]^{T}](/2014-wikipedia_en_all_02_2014/I/media/0/5/c/8/05c8c4aa59496b3b70dc3d9d9b306170.png) , where the superscript T refers to the transpose of the indicated vector:
, where the superscript T refers to the transpose of the indicated vector:
![\operatorname {Var}[{\mathbf {X}}]=\operatorname {E}[({\mathbf {X}}-\operatorname {E}[{\mathbf {X}}])({\mathbf {X}}-\operatorname {E}[{\mathbf {X}}])^{{T}}].](/2014-wikipedia_en_all_02_2014/I/media/5/1/0/d/510d9fe741a6ad54c171f790d7d8745f.png)
By extension, the cross-covariance matrix between two random vectors and ( having  elements and having
elements and having  elements) is the
elements) is the 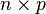 matrix
matrix
![\operatorname {Cov}[{\mathbf {X}},{\mathbf {Y}}]=\operatorname {E}[({\mathbf {X}}-\operatorname {E}[{\mathbf {X}}])({\mathbf {Y}}-\operatorname {E}[{\mathbf {Y}}])^{{T}}],](/2014-wikipedia_en_all_02_2014/I/media/6/a/8/b/6a8b8ab694db469de6fa59369c13aff5.png)
where again the indicated matrix expectation is taken element-by-element in the matrix. The cross-covariance matrix ![\operatorname {Cov}[{\mathbf {Y}},{\mathbf {X}}]](/2014-wikipedia_en_all_02_2014/I/media/4/e/4/8/4e488a41095c0cdd40d6cadc5394d8d5.png) is simply the transpose of the matrix
is simply the transpose of the matrix ![\operatorname {Cov}[{\mathbf {X}},{\mathbf {Y}}]](/2014-wikipedia_en_all_02_2014/I/media/3/d/8/1/3d81b434df666d759207a6e3ebdf3e12.png) .
.
Further properties
Expectation of a quadratic form
One can take the expectation of a quadratic form in the random vector X as follows:[1]:p.170-171
![\operatorname {E}(X^{{T}}AX)=[\operatorname {E}(X)]^{{T}}A[\operatorname {E}(X)]+\operatorname {tr}(AC),](/2014-wikipedia_en_all_02_2014/I/media/d/8/b/d/d8bddbbe2f0fe8db387087f749aa7c69.png)
where C is the covariance matrix of X and tr refers to the trace of a matrix — that is, to the sum of the elements on its main diagonal (from upper left to lower right). Since the quadratic form is a scalar, so is its expectation.
Proof: Let  be an
be an  random vector with
random vector with ![\operatorname {E}[{\mathbf {z}}]=\mu](/2014-wikipedia_en_all_02_2014/I/media/b/b/b/f/bbbfabbcb3018954938bac0359733161.png) and
and ![\operatorname {Cov}[{\mathbf {z}}]=V](/2014-wikipedia_en_all_02_2014/I/media/2/3/e/c/23ec28203bea81936ff14300c21f50a3.png) and let
and let 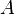 be an
be an 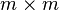 non-stochastic matrix.
non-stochastic matrix.
Based on the formula of the covariance, then if we call 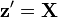 and
and 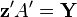 , we see that:
, we see that:
![\operatorname {Cov}[{\mathbf {X}},{\mathbf {Y}}]=\operatorname {E}[{\mathbf {X}}{\mathbf {Y}}']-\operatorname {E}[{\mathbf {X}}]\operatorname {E}[{\mathbf {Y}}]'](/2014-wikipedia_en_all_02_2014/I/media/f/0/9/1/f09161038e458b3605b86003fe3b967c.png)
Hence
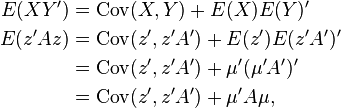
which leaves us to show that

This is true based on the fact that one can cyclically permute matrices when taking a trace without changing the end result (e.g.: trace(AB) = trace(BA)).
We see that
![{\begin{aligned}\operatorname {Cov}(z',z'A')&=E\left[\left(z'-E(z')\right)\left(z'A'-E\left(z'A'\right)\right)'\right]\\&=E\left[(z'-\mu ')(z'A'-\mu 'A')'\right]\\&=E\left[(z-\mu )'(Az-A\mu )\right].\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/4/6/2/a/462a304755c11cf103c6ad461866b03c.png)
And since

is a fixed number, then
![(z-\mu )'(Az-A\mu )=\operatorname {trace}\left[{(z-\mu )'(Az-A\mu )}\right]=\operatorname {trace}\left[(z-\mu )'A(z-\mu )\right]](/2014-wikipedia_en_all_02_2014/I/media/0/b/b/1/0bb1409ef1f512d8e2e343600fb0db87.png)
trivially. Using the permutation we get:
![\operatorname {trace}\left[{(z-\mu )'A(z-\mu )}\right]=\operatorname {trace}\left[{A(z-\mu )'(z-\mu )}\right],](/2014-wikipedia_en_all_02_2014/I/media/a/4/7/6/a476f911b7bbce9735a3a1b5a59493f4.png)
and by plugging this into the original formula we get:
![{\begin{aligned}\operatorname {Cov}\left({z',z'A'}\right)&=E\left[{\left({z-\mu }\right)'(Az-A\mu )}\right]\\&=E\left[\operatorname {trace}\left[A(z-\mu )'(z-\mu )\right]\right]\\&=\operatorname {trace}\left[{A\cdot E\left[(z-\mu )'(z-\mu )\right]}\right]\\&=\operatorname {trace}[AV].\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/5/b/f/d/5bfd8dc798f12a79b8dc7c487084e389.png)
Expectation of the product of two different quadratic forms
One can take the expectation of the product of two different quadratic forms in a zero-mean Gaussian random vector X as follows:[1]:pp. 162-176
![\operatorname {E}[X^{{T}}AX][X^{{T}}BX]=2\operatorname {trace}(ACBC)+\operatorname {trace}(AC)\operatorname {trace}(BC)](/2014-wikipedia_en_all_02_2014/I/media/a/5/f/b/a5fbce7a875c0555a007200ea7ba683d.png)
where again C is the covariance matrix of X. Again, since both quadratic forms are scalars and hence their product is a scalar, the expectation of their product is also a scalar.
Applications
Portfolio theory
In portfolio theory in finance, an objective often is to choose a portfolio of risky assets such that the distribution of the random portfolio return has desirable properties. For example, one might want to choose the portfolio return having the lowest variance for a given expected value. Here the random vector is the vector r of random returns on the individual assets, and the portfolio return p (a random scalar) is the inner product of the vector of random returns with a vector w of portfolio weights — the fractions of the portfolio placed in the respective assets. Since p = wTr, the expected value of the portfolio return is wTE(r) and the variance of the portfolio return can be shown to be wTCw, where C is the covariance matrix of r.
Regression theory
In linear regression theory, we have data on n observations on a dependent variable y and n observations on each of k independent variables xj. The observations on the dependent variable are stacked into a column vector y; the observations on each independent variable are also stacked into column vectors, and these latter column vectors are combined into a matrix X of observations on the independent variables. Then the following regression equation is postulated as a description of the process that generated the data:
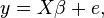
where β is a postulated fixed but unknown vector of k response coefficients, and e is an unknown random vector reflecting random influences on the dependent variable. By some chosen technique such as ordinary least squares, a vector  is chosen as an estimate of β, and the estimate of the vector e, denoted
is chosen as an estimate of β, and the estimate of the vector e, denoted 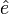 , is computed as
, is computed as
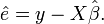
Then the statistician must analyze the properties of and , which are viewed as random vectors since a randomly different selection of n cases to observe would have resulted in different values for them.
References