Monte Carlo localization
Monte Carlo localization (MCL), also known as particle filter localization,[1] is an application of the particle filter, a Monte Carlo method, for robot localization.[2][3][4][5] Given a map of the environment, the algorithm estimates the position and orientation of a robot as it moves and senses the environment.[4] The algorithm uses a particle filter to represent the distribution of likely states, with each particle representing a possible state, i.e. a hypothesis of where the robot is.[4] The algorithm typically starts with a uniform random distribution of particles over the configuration space, meaning the robot has no information about where it is and assumes it is equally likely to be at any point in space.[4] Whenever the robot moves, it shifts the particles to predict its new state after the movement. Whenever the robot senses something, the particles are resampled based on recursive Bayesian estimation, i.e. how well the actual sensed data correlate with the predicted state. Ultimately, the particles should converge towards the actual pose of the robot.[4]
State representation
The state of the robot depends on the application and design. For example, the state of a typical 2D robot may consist of a tuple 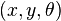 for position
for position 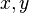 and orientation
and orientation 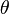 . For a robotic arm with 10 joints, it may be a tuple containing the angle at each joint:
. For a robotic arm with 10 joints, it may be a tuple containing the angle at each joint: 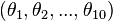 .
.
The belief, which is the robot's estimate of its current state, is a probability density function distributed over the state space.[1][4] In the MCL algorithm, the belief at a time 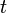 is represented by a set of
is represented by a set of  particles
particles ![X_{t}=\lbrace x_{t}^{{[1]}},x_{t}^{{[2]}},\ldots ,x_{t}^{{[M]}}\rbrace](/2014-wikipedia_en_all_02_2014/I/media/4/7/c/f/47cff9e73f0633b5580123724a1b0c7c.png) .[4] Each particle contains a state, and can thus be considered a hypothesis of the robot's state. Regions in the state space with many particles correspond to a greater probability that the robot will be there; and regions with few particles are unlikely to be where the robot is.
.[4] Each particle contains a state, and can thus be considered a hypothesis of the robot's state. Regions in the state space with many particles correspond to a greater probability that the robot will be there; and regions with few particles are unlikely to be where the robot is.
The algorithm assumes the Markov property that the current state's probability distribution depends only on the previous state (and not any ones before that), i.e.  depends only on
depends only on 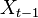 .[4] This only works if the environment is static and does not change with time.[4] Typically, on start up, the robot has no information on its current pose so the particles are uniformly distributed over the configuration space.[4]
.[4] This only works if the environment is static and does not change with time.[4] Typically, on start up, the robot has no information on its current pose so the particles are uniformly distributed over the configuration space.[4]
Overview
Given a map of the environment, the goal of the algorithm is for the robot to determine its pose within the environment.
At every time the algorithm takes as input the previous belief ![X_{{t-1}}=\lbrace x_{{t-1}}^{{[1]}},x_{{t-1}}^{{[2]}},\ldots ,x_{{t-1}}^{{[M]}}\rbrace](/2014-wikipedia_en_all_02_2014/I/media/c/b/a/2/cba2beb04bd8466a6135a9cf032370f6.png) , an actuation command
, an actuation command 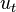 , and data received from sensors
, and data received from sensors 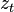 ; and the algorithm outputs the new belief .[4]
; and the algorithm outputs the new belief .[4]
Algorithm MCL:
for
to
motion_update
![(u_{t},x_{{t-1}}^{{[m]}})](/2014-wikipedia_en_all_02_2014/I/media/e/0/2/5/e025e112c02c30aecc8c9e66d51fe7af.png)
sensor_update
![(z_{t},x_{t}^{{[m]}})](/2014-wikipedia_en_all_02_2014/I/media/2/5/0/b/250b64d6732f7d01d522f89ba7eaeb16.png)
endfor for
from
with probability
![\propto w_{t}^{{[i]}}](/2014-wikipedia_en_all_02_2014/I/media/8/4/e/2/84e23169fa741cb7c54b9f8cae29d206.png)
endfor return
Example for 1D robot


Consider a robot in a one-dimensional circular corridor with three identical doors, using a sensor that returns either true or false depending on whether there is a door.
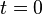 | ||
|---|---|---|
 The algorithm initializes with a uniform distribution of particles. The robot considers itself equally likely to be at any point in space along the corridor, even though it is physically at the first door. |
 Sensor update: the robot detects a door. It assigns a weight to each of the particles. The particles which are likely to give this sensor reading receive a higher weight. |
 Resampling: the robot generates a set of new particles, with most of them generated around the previous particles with more weight. It now believes it is at one of the three doors. |
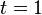 | ||
|---|---|---|
 Motion update: the robot moves some distance to the right. All particles also move right, and some noise is applied. The robot is physically between the second and third doors. |
 Sensor update: the robot detects no door. It assigns a weight to each of the particles. The particles which are likely to give this sensor reading receive a higher weight. |
 Resampling: the robot generates a set of new particles, with most of them generated around the previous particles with more weight. It now believes it is at one of two locations. |
 | ||
|---|---|---|
 Motion update: the robot moves some distance to the left. All particles also move left, and some noise is applied. The robot is physically at the second door. |
 Sensor update: the robot detects a door. It assigns a weight to each of the particles. The particles which are likely to give this sensor reading receive a higher weight. |
 Resampling: the robot generates a set of new particles, with most of them generated around the previous particles with more weight. The robot has successfully localized itself. |
At the end of the three iterations, most of the particles are converged on the actual position of the robot as desired.
Motion update
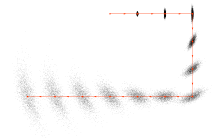
During the motion update, the robot predicts its new location based on the actuation command given, by applying the simulated motion to each of the particles.[1] For example, if a robot moves forward, all particles will move forward in their own direction no matter which ways they are pointing. If a robot rotates 90 degrees clockwise, all particles will rotate 90 degrees clockwise regardless of where they are. However, in the real world, no actuator is perfect: they may overshoot or undershoot the desired amount of motion; when a robot tries to drive in a straight line, it will inevitably curve to one side or the other due to minute differences in wheel radius.[1] Hence, the motion model must be designed to include noise as necessary. Inevitably, the particles will diverge during the motion update as a consequence. This is expected since a robot becomes less sure of its position if it moves blindly without sensing the environment.
Sensor update
When the robot senses its environment, it will update its particles to more accurately reflect where it is. For each particle, the robot computes the probability that, had it been at the state of the particle, it would perceive what its sensors have actually sensed. It assigns a weight ![w_{t}^{{[i]}}](/2014-wikipedia_en_all_02_2014/I/media/9/6/4/6/9646725259ffc91ac3f674a1709f3b78.png) for each particle proportional to the said probability. Then, it randomly draws new particles from the previous belief, with probability proportional to . Particles which were consistent with sensor readings are more likely to be chosen (possibly more than once) and particles which are inconsistent with sensor readings are rarely picked. As such, particles converge towards a better estimate of the robot's state. This is expected since a robot becomes increasingly sure of its position as it senses its environment.
for each particle proportional to the said probability. Then, it randomly draws new particles from the previous belief, with probability proportional to . Particles which were consistent with sensor readings are more likely to be chosen (possibly more than once) and particles which are inconsistent with sensor readings are rarely picked. As such, particles converge towards a better estimate of the robot's state. This is expected since a robot becomes increasingly sure of its position as it senses its environment.
Properties
Non-parametricity
The particle filter central to MCL can approximate multiple different kinds of probability distributions, since it is a non-parametric representation.[4] Some other Bayesian localization algorithms, such as the Kalman filter (and variants, the extended Kalman filter and the unscented Kalman filter), assume the belief of the robot is close to being a Gaussian distribution and do not perform well for situations where the belief is multimodal.[4] For example, a robot in a long corridor with many similar-looking doors may arrive at a belief that has a peak for each door, but the robot is unable to distinguish which door it is at. In such situations, the particle filter can give better performance than parametric filters.[4]
Another non-parametric approach to Markov localization is the grid-based localization, which uses a histogram to represent the belief distribution. Compared with the grid-based approach, the Monte Carlo localization is more accurate because the state represented in samples is not discretized.[2]
Computational requirements
The particle filter's time complexity is linear with respect to the number of particles. Naturally, the more particles, the better the accuracy, so there is a compromise between speed and accuracy and it is desired to find an optimal value of . One strategy to select is to continuously generate additional particles until the next pair of command and sensor reading has arrived.[4] This way, the greatest possible number of particles is obtained while not impeding the function of the rest of the robot. As such, the implementation is adaptive to available computational resources: the faster the processor, the more particles can be generated and therefore the more accurate the algorithm is.[4]
Compared to grid-based Markov localization, Monte Carlo localization has reduced memory usage since memory usage only depends on number of particles and does not scale with size of the map,[2] and can integrate measurements at a much higher frequency.[2]
Particle deprivation
A drawback of the naive implementation of Monte Carlo localization occurs in a scenario where a robot sits at one spot and repeatedly senses the environment without moving.[4] Suppose that the particles all converge towards an erroneous state, or if an occult hand picks up the robot and moves it to a new location after particles have already converged. As particles far away from the converged state are rarely selected for the next iteration, they become scarcer on each iteration until they disappear altogether. At this point, the algorithm is unable to recover.[4] This problem is more likely to occur for small number of particles, e.g.  , and when the particles are spread over a large state space.[4] In fact, any particle filter algorithm may accidentally discard all particles near the correct state during the resampling step.[4]
, and when the particles are spread over a large state space.[4] In fact, any particle filter algorithm may accidentally discard all particles near the correct state during the resampling step.[4]
One way to mitigate this issue is to randomly add extra particles on every iteration.[4] This is equivalent to assuming that, at any point in time, the robot has some small probability of being kidnapped to a random position in the map, thus causing a fraction of random states in the motion model.[4] By guaranteeing that no area in the map will be totally deprived of particles, the algorithm is now robust against particle deprivation.
References
- ↑ 1.0 1.1 1.2 1.3 Ioannis M. Rekleitis. "A Particle Filter Tutorial for Mobile Robot Localization." Centre for Intelligent Machines, McGill University, Tech. Rep. TR-CIM-04-02 (2004).
- ↑ 2.0 2.1 2.2 2.3 Frank Dellaert, Dieter Fox, Wolfram Burgard, Sebastian Thrun. "Monte Carlo Localization for Mobile Robots." Proc. of the IEEE International Conference on Robotics and Automation Vol. 2. IEEE, 1999.
- ↑ Dieter Fox, Wolfram Burgard, Frank Dellaert, and Sebastian Thrun, "Monte Carlo Localization: Efficient Position Estimation for Mobile Robots." Proc. of the Sixteenth National Conference on Artificial Intelligence John Wiley & Sons Ltd, 1999.
- ↑ 4.0 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 4.10 4.11 4.12 4.13 4.14 4.15 4.16 4.17 4.18 4.19 4.20 4.21 Sebastian Thrun, Wolfram Burgard, Dieter Fox. Probabilistic Robotics MIT Press, 2005. Ch. 8.3 ISBN 9780262201629.
- ↑ Sebastian Thrun, Dieter Fox, Wolfram Burgard, Frank Dellaert. "Robust monte carlo localization for mobile robots." Artificial Intelligence 128.1 (2001): 99–141.