Matrix calculus
| Calculus |
|---|
|
Integral calculus
|
|
Specialized calculi |
In mathematics, matrix calculus is a specialized notation for doing multivariable calculus, especially over spaces of matrices. It collects the various partial derivatives of a single function with respect to many variables, and/or of a multivariate function with respect to a single variable, into vectors and matrices that can be treated as single entities. This greatly simplifies operations such as finding the maximum or minimum of a multivariate function and solving systems of differential equations. The notation used here is commonly used in statistics and engineering, while the tensor index notation is preferred in physics.
Two competing notational conventions split the field of matrix calculus into two separate groups. The two groups can be distinguished by whether they write the derivative of a scalar with respect to a vector as a column vector or a row vector. Both of these conventions are possible even when the common assumption is made that vectors should be treated as column vectors when combined with matrices (rather than row vectors). A single convention can be somewhat standard throughout a single field that commonly use matrix calculus (e.g. econometrics, statistics, estimation theory and machine learning). However, even within a given field different authors can be found using competing conventions. Authors of both groups often write as though their specific convention is standard. Serious mistakes can result when combining results from different authors without carefully verifying that compatible notations are used. Therefore great care should be taken to ensure notational consistency. Definitions of these two conventions and comparisons between them are collected in the layout conventions section.
Scope
Matrix calculus refers to a number of different notations that use matrices and vectors to collect the derivative of each component of the dependent variable with respect to each component of the independent variable. In general, the independent variable can be a scalar, a vector, or a matrix while the dependent variable can be any of these as well. Each different situation will lead to a different set of rules, or a separate calculus, using the broader sense of the term. Matrix notation serves as a convenient way to collect the many derivatives in an organized way.
As a first example, consider the gradient from vector calculus. For a scalar function of three independent variables,  , the gradient is given by the vector equation
, the gradient is given by the vector equation
 ,
,
where 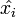 represents a unit vector in the
represents a unit vector in the  direction for
direction for  . This type of generalized derivative can be seen as the derivative of a scalar, f, with respect to a vector,
. This type of generalized derivative can be seen as the derivative of a scalar, f, with respect to a vector,  and its result can be easily collected in vector form.
and its result can be easily collected in vector form.
 [citation needed]
[citation needed]
More complicated examples include the derivative of a scalar function with respect to a matrix, known as the gradient matrix, which collects the derivative with respect to each matrix element in the corresponding position in the resulting matrix. In that case the scalar must be a function of each of the independent variables in the matrix. As another example, if we have an n-vector of dependent variables, or functions, of m independent variables we might consider the derivative of the dependent vector with respect to the independent vector. The result could be collected in an m×n matrix consisting of all of the possible derivative combinations. There are, of course, a total of nine possibilities using scalars, vectors, and matrices. Notice that as we consider higher numbers of components in each of the independent and dependent variables we can be left with a very large number of possibilities.
The six kinds of derivatives that can be most neatly organized in matrix form are collected in the following table.[1]
| Types | Scalar | Vector | Matrix |
|---|---|---|---|
| Scalar | 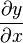 |  |  |
| Vector | 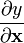 | 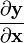 | |
| Matrix |  |
Here, we have used the term "matrix" in its most general sense, recognizing that vectors and scalars are simply matrices with one column and then one row respectively. Moreover, we have used bold letters to indicate vectors and bold capital letters for matrices. This notation is used throughout.
Notice that we could also talk about the derivative of a vector with respect to a matrix, or any of the other unfilled cells in our table. However, these derivatives are most naturally organized in a tensor of rank higher than 2, so that they do not fit neatly into a matrix. In the following three sections we will define each one of these derivatives and relate them to other branches of mathematics. See the layout conventions section for a more detailed table.
Relation to other derivatives
The matrix derivative is a convenient notation for keeping track of partial derivatives for doing calculations. The Fréchet derivative is the standard way in the setting of functional analysis to take derivatives with respect to vectors. In the case that a matrix function of a matrix is Fréchet differentiable, the two derivatives will agree up to translation of notations. As is the case in general for partial derivatives, some formulae may extend under weaker analytic conditions than the existence of the derivative as approximating linear mapping.
Usages
Matrix calculus is used for deriving optimal stochastic estimators, often involving the use of Lagrange multipliers. This includes the derivation of:
- Kalman filter
- Wiener filter
- Expectation-maximization algorithm for Gaussian mixture
Notation
The vector and matrix derivatives presented in the sections to follow take full advantage of matrix notation, using a single variable to represent a large number of variables. In what follows we will distinguish scalars, vectors and matrices by their typeface. We will let M(n,m) denote the space of real n×m matrices with n rows and m columns. Such matrices will be denoted using bold capital letters: A, X, Y, etc. An element of M(n,1), that is, a column vector, is denoted with a boldface lowercase letter: a, x, y, etc. An element of M(1,1) is a scalar, denoted with lowercase italic typeface: a, t, x, etc. XT denotes matrix transpose, tr(X) is the trace, and det(X) is the determinant. All functions are assumed to be of differentiability class C1 unless otherwise noted. Generally letters from first half of the alphabet (a, b, c, …) will be used to denote constants, and from the second half (t, x, y, …) to denote variables.
NOTE: As mentioned above, there are competing notations for laying out systems of partial derivatives in vectors and matrices, and no standard appears to be emerging yet. The next two introductory sections use the numerator layout convention simply for the purposes of convenience, to avoid overly complicating the discussion. The section after them discusses layout conventions in more detail. It is important to realize the following:
- Despite the use of the terms "numerator layout" and "denominator layout", there are actually more than two possible notational choices involved. The reason is that the choice of numerator vs. denominator (or in some situations, numerator vs. mixed) can be made independently for scalar-by-vector, vector-by-scalar, vector-by-vector, and scalar-by-matrix derivatives, and a number of authors mix and match their layout choices in various ways.
- The choice of numerator layout in the introductory sections below does not imply that this is the "correct" or "superior" choice. There are advantages and disadvantages to the various layout types. Serious mistakes can result from carelessly combining formulas written in different layouts, and converting from one layout to another requires care to avoid errors. As a result, when working with existing formulas the best policy is probably to identify whichever layout is used and maintain consistency with it, rather than attempting to use the same layout in all situations.
Alternatives
The tensor index notation with its Einstein summation convention is very similar to the matrix calculus, except one writes only a single component at a time. It has the advantage that one can easily manipulate arbitrarily high rank tensors, whereas tensors of rank higher than two are quite unwieldy with matrix notation. All of the work here can be done in this notation without use of the single-variable matrix notation. However, many problems in estimation theory and other areas of applied mathematics would result in too many indices to properly keep track of, pointing in favor of matrix calculus in those areas. Also, Einstein notation can be very useful in proving the identities presented here, as an alternative to typical element notation, which can become cumbersome when the explicit sums are carried around. Note that a matrix can be considered a tensor of rank two.
Derivatives with vectors
Because vectors are matrices with only one column, the simplest matrix derivatives are vector derivatives.
The notations developed here can accommodate the usual operations of vector calculus by identifying the space M(n,1) of n-vectors with the Euclidean space Rn, and the scalar M(1,1) is identified with R. The corresponding concept from vector calculus is indicated at the end of each subsection.
NOTE: The discussion in this section assumes the numerator layout convention for pedagogical purposes. Some authors use different conventions. The section on layout conventions discusses this issue in greater detail. The identities given further down are presented in forms that can be used in conjunction with all common layout conventions.
Vector-by-scalar
The derivative of a vector
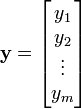 ,
by a scalar x is written (in numerator layout notation) as
,
by a scalar x is written (in numerator layout notation) as
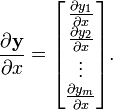
In vector calculus the derivative of a vector y with respect to a scalar x is known as the tangent vector of the vector y, . Notice here that y:R  Rm.
Rm.
Example Simple examples of this include the velocity vector in Euclidean space, which is the tangent vector of the position vector (considered as a function of time). Also, the acceleration is the tangent vector of the velocity.
Scalar-by-vector
The derivative of a scalar y by a vector
 ,
is written (in numerator layout notation) as
,
is written (in numerator layout notation) as
![{\frac {\partial y}{\partial {\mathbf {x}}}}=\left[{\frac {\partial y}{\partial x_{1}}}\ \ {\frac {\partial y}{\partial x_{2}}}\ \ \cdots \ \ {\frac {\partial y}{\partial x_{n}}}\right].](/2014-wikipedia_en_all_02_2014/I/media/7/f/5/2/7f52f0b5c0cd27fbeaccc76745c1a2a7.png)
In vector calculus the gradient of a scalar field y, in the space Rn whose independent coordinates are the components of x is the derivative of a scalar by a vector. In physics, the electric field is the vector gradient of the electric potential.
The directional derivative of a scalar function f(x) of the space vector x in the direction of the unit vector u is defined using the gradient as follows.

Using the notation just defined for the derivative of a scalar with respect to a vector we can re-write the directional derivative as
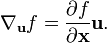 This type of notation will be nice when proving product rules and chain rules that come out looking similar to what we are familiar with for the scalar derivative.
This type of notation will be nice when proving product rules and chain rules that come out looking similar to what we are familiar with for the scalar derivative.
Vector-by-vector
Each of the previous two cases can be considered as an application of the derivative of a vector with respect to a vector, using a vector of size one appropriately. Similarly we will find that the derivatives involving matrices will reduce to derivatives involving vectors in a corresponding way.
The derivative of a vector function (a vector whose components are functions)
,
of an independent vector
,
is written (in numerator layout notation) as
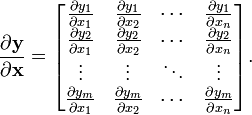
In vector calculus, the derivative of a vector function y with respect to a vector x whose components represent a space is known as the pushforward or differential, or the Jacobian matrix.
The pushforward along a vector function f with respect to vector v in Rm is given by

Derivatives with matrices
There are two types of derivatives with matrices that can be organized into a matrix of the same size. These are the derivative of a matrix by a scalar and the derivative of a scalar by a matrix respectively. These can be useful in minimization problems found many areas of applied mathematics and have adopted the names tangent matrix and gradient matrix respectively after their analogs for vectors.
NOTE: The discussion in this section assumes the numerator layout convention for pedagogical purposes. Some authors use different conventions. The section on layout conventions discusses this issue in greater detail. The identities given further down are presented in forms that can be used in conjunction with all common layout conventions.
Matrix-by-scalar
The derivative of a matrix function Y by a scalar x is known as the tangent matrix and is given (in numerator layout notation) by
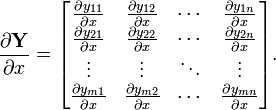
Scalar-by-matrix
The derivative of a scalar y function of a matrix X of independent variables, with respect to the matrix X, is given (in numerator layout notation) by
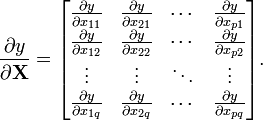
Notice that the indexing of the gradient with respect to X is transposed as compared with the indexing of X. Important examples of scalar functions of matrices include the trace of a matrix and the determinant.
In analog with vector calculus this derivative is often written as the following.
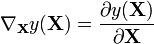
Also in analog with vector calculus, the directional derivative of a scalar f(X) of a matrix X in the direction of matrix Y is given by
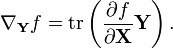
It is the gradient matrix, in particular, that finds many uses in minimization problems in estimation theory, particularly in the derivation of the Kalman filter algorithm, which is of great importance in the field.
Other matrix derivatives
The three types of derivatives that have not been considered are those involving vectors-by-matrices, matrices-by-vectors, and matrices-by-matrices. These are not as widely considered and a notation is not widely agreed upon. As for vectors, the other two types of higher matrix derivatives can be seen as applications of the derivative of a matrix by a matrix by using a matrix with one column in the correct place. For this reason, in this subsection we consider only how one can write the derivative of a matrix by another matrix.
The differential or the matrix derivative of a matrix function F(X) that maps from n×m matrices to p×q matrices, F : M(n,m)  M(p,q), is an element of M(p,q) ? M(m,n), a fourth-rank tensor (the reversal of m and n here indicates the dual space of M(n,m)). In short it is an m×n matrix each of whose entries is a p×q matrix.[citation needed]
M(p,q), is an element of M(p,q) ? M(m,n), a fourth-rank tensor (the reversal of m and n here indicates the dual space of M(n,m)). In short it is an m×n matrix each of whose entries is a p×q matrix.[citation needed]

and note that each 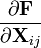 is a p×q matrix defined as above. Note also that this matrix has its indexing transposed; m rows and n columns. The pushforward along F of an n×m matrix Y in M(n,m) is then
is a p×q matrix defined as above. Note also that this matrix has its indexing transposed; m rows and n columns. The pushforward along F of an n×m matrix Y in M(n,m) is then
 as formal block matrices.
as formal block matrices.
Note that this definition encompasses all of the preceding definitions as special cases.
According to Jan R. Magnus and Heinz Neudecker, the following notations are both unsuitable, as the determinant of the second resulting matrix would have "no interpretation" and "a useful chain rule does not exist" if these notations are being used:[2]
- Given
 , a differentiable function of an
, a differentiable function of an  matrix
matrix  ,
,
- Given
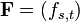 , a differentiable
, a differentiable 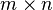 function of an matrix
function of an matrix 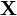 ,
,
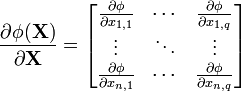
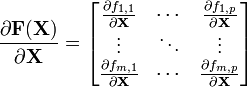
The Jacobian matrix, according to Magnus and Neudecker,[2] is
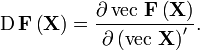
Layout conventions
This section discusses the similarities and differences between notational conventions that are used in the various fields that take advantage of matrix calculus. Although there are largely two consistent conventions, some authors find it convenient to mix the two conventions in forms that are discussed below. After this section equations will be listed in both competing forms separately.
The fundamental issue is that the derivative of a vector with respect to a vector, i.e. , is often written in two competing ways. If the numerator y is of size m and the denominator x of size n, then the result can be laid out as either an m×n matrix or n×m matrix, i.e. the elements of y laid out in columns and the elements of x laid out in rows, or vice-versa. This leads to the following possibilities:
- Numerator layout, i.e. lay out according to y and xT (i.e. contrarily to x). This is sometimes known as the Jacobian formulation.
- Denominator layout, i.e. lay out according to yT and x (i.e. contrarily to y). This is sometimes known as the Hessian formulation. Some authors term this layout the gradient, in distinction to the Jacobian (numerator layout), which is its transpose. (However, "gradient" more commonly means the derivative
 regardless of layout.)
regardless of layout.) - A third possibility sometimes seen is to insist on writing the derivative as
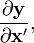 (i.e. the derivative is taken with respect to the transpose of x) and follow the numerator layout. This makes it possible to claim that the matrix is laid out according to both numerator and denominator. In practice this produces results the same as the numerator layout.
(i.e. the derivative is taken with respect to the transpose of x) and follow the numerator layout. This makes it possible to claim that the matrix is laid out according to both numerator and denominator. In practice this produces results the same as the numerator layout.
When handling the gradient and the opposite case  we have the same issues. To be consistent, we should do one of the following:
we have the same issues. To be consistent, we should do one of the following:
- If we choose numerator layout for
 we should lay out the gradient as a row vector, and as a column vector.
we should lay out the gradient as a row vector, and as a column vector. - If we choose denominator layout for we should lay out the gradient as a column vector, and as a row vector.
- In the third possibility above, we write
 and and use numerator layout.
and and use numerator layout.
Not all math textbooks and papers are consistent in this respect throughout the entire paper. That is, sometimes different conventions are used in different contexts within the same paper. For example, some choose denominator layout for gradients (laying them out as column vectors), but numerator layout for the vector-by-vector derivative 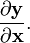
Similarly, when it comes to scalar-by-matrix derivatives and matrix-by-scalar derivatives  then consistent numerator layout lays out according to Y and XT, while consistent denominator layout lays out according to YT and X. In practice, however, following a denominator layout for and laying the result out according to YT, is rarely seen because it makes for ugly formulas that do not correspond to the scalar formulas. As a result, the following layouts can often be found:
then consistent numerator layout lays out according to Y and XT, while consistent denominator layout lays out according to YT and X. In practice, however, following a denominator layout for and laying the result out according to YT, is rarely seen because it makes for ugly formulas that do not correspond to the scalar formulas. As a result, the following layouts can often be found:
- Consistent numerator layout, which lays out according to Y and according to XT.
- Mixed layout, which lays out according to Y and according to X.
- Use the notation
 with results the same as consistent numerator layout.
with results the same as consistent numerator layout.
In the following formulas, we handle the five possible combinations  and separately. We also handle cases of scalar-by-scalar derivatives that involve an intermediate vector or matrix. (This can arise, for example, if a multi-dimensional parametric curve is defined in terms of a scalar variable, and then a derivative of a scalar function of the curve is taken with respect to the scalar that parameterizes the curve.) For each of the various combinations, we give numerator-layout and denominator-layout results, except in the cases above where denominator layout rarely occurs. In cases involving matrices where it makes sense, we give numerator-layout and mixed-layout results. As noted above, cases where vector and matrix denominators are written in transpose notation are equivalent to numerator layout with the denominators written without the transpose.
and separately. We also handle cases of scalar-by-scalar derivatives that involve an intermediate vector or matrix. (This can arise, for example, if a multi-dimensional parametric curve is defined in terms of a scalar variable, and then a derivative of a scalar function of the curve is taken with respect to the scalar that parameterizes the curve.) For each of the various combinations, we give numerator-layout and denominator-layout results, except in the cases above where denominator layout rarely occurs. In cases involving matrices where it makes sense, we give numerator-layout and mixed-layout results. As noted above, cases where vector and matrix denominators are written in transpose notation are equivalent to numerator layout with the denominators written without the transpose.
Keep in mind that various authors use different combinations of numerator and denominator layouts for different types of derivatives, and there is no guarantee that an author will consistently use either numerator or denominator layout for all types. Match up the formulas below with those quoted in the source to determine the layout used for that particular type of derivative, but be careful not to assume that derivatives of other types necessarily follow the same kind of layout.
When taking derivatives with an aggregate (vector or matrix) denominator in order to find a maximum or minimum of the aggregate, it should be kept in mind that using numerator layout will produce results that are transposed with respect to the aggregate. For example, in attempting to find the maximum likelihood estimate of a multivariate normal distribution using matrix calculus, if the domain is a kx1 column vector, then the result using the numerator layout will be in the form of a 1xk row vector. Thus, either the results should be transposed at the end or the denominator layout (or mixed layout) should be used.
Result of differentiating various kinds of aggregates with other kinds of aggregates Scalar y Vector y (size m) Matrix Y (size m×n) Notation Type Notation Type Notation Type Scalar x scalar (numerator layout) size-m column vector
(denominator layout) size-m row vector
(numerator layout) m×n matrix Vector x (size n) (numerator layout) size-n row vector
(denominator layout) size-n column vector
(numerator layout) m×n matrix
(denominator layout) n×m matrix

? Matrix X (size p×q) (numerator layout) q×p matrix
(denominator layout) p×q matrix

? 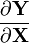
?
The results of operations will be transposed when switching between numerator-layout and denominator-layout notation.
Numerator-layout notation
Using numerator-layout notation, we have:[1]
![{\frac {\partial y}{\partial {\mathbf {x}}}}=\left[{\frac {\partial y}{\partial x_{1}}}{\frac {\partial y}{\partial x_{2}}}\cdots {\frac {\partial y}{\partial x_{n}}}\right].](/2014-wikipedia_en_all_02_2014/I/media/0/5/8/a/058a849a9a78fddbf1e59bcc4fa1f47c.png)
The following definitions are only provided in numerator-layout notation:
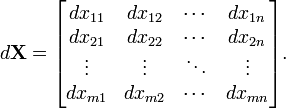
Denominator-layout notation
Using denominator-layout notation, we have:[3]

![{\frac {\partial {\mathbf {y}}}{\partial x}}=\left[{\frac {\partial y_{1}}{\partial x}}{\frac {\partial y_{2}}{\partial x}}\cdots {\frac {\partial y_{m}}{\partial x}}\right].](/2014-wikipedia_en_all_02_2014/I/media/b/4/b/5/b4b563beb83701f5f3854e277f4f4f6e.png)

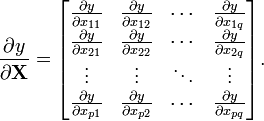
Identities
As noted above, in general, the results of operations will be transposed when switching between numerator-layout and denominator-layout notation.
To help make sense of all the identities below, keep in mind the most important rules: the chain rule, product rule and sum rule. The sum rule applies universally, and the product rule applies in most of the cases below, provided that the order of matrix products is maintained, since matrix products are not commutative. The chain rule applies in some of the cases, but unfortunately does not apply in matrix-by-scalar derivatives or scalar-by-matrix derivatives (in the latter case, mostly involving the trace operator applied to matrices). In the latter case, the product rule can't quite be applied directly, either, but the equivalent can be done with a bit more work using the differential identities.
Vector-by-vector identities
This is presented first because all of the operations that apply to vector-by-vector differentiation apply directly to vector-by-scalar or scalar-by-vector differentiation simply by reducing the appropriate vector in the numerator or denominator to a scalar.
Identities: vector-by-vector Condition Expression Numerator layout, i.e. by y and xT Denominator layout, i.e. by yT and x a is not a function of x 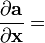
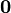


A is not a function of x 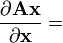

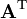
A is not a function of x 
a is not a function of x,
u = u(x)
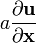
a = a(x), u = u(x) 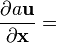
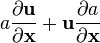

A is not a function of x,
u = u(x)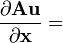
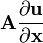

u = u(x), v = v(x) 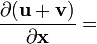
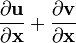
u = u(x) 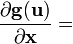


u = u(x) 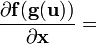
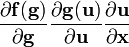

Scalar-by-vector identities
The fundamental identities are placed above the thick black line.
Identities: scalar-by-vector 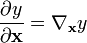
Condition Expression Numerator layout,
i.e. by xT; result is row vectorDenominator layout,
i.e. by x; result is column vectora is not a function of x 
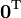 [4] [4]
[4] [4]a is not a function of x,
u = u(x)

u = u(x), v = v(x) 
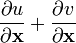
u = u(x), v = v(x) 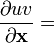
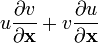
u = u(x) 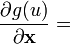
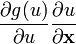
u = u(x) 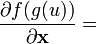
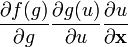
u = u(x), v = v(x) 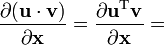
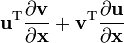
- assumes numerator layout of

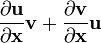
- assumes denominator layout of
u = u(x), v = v(x),
A is not a function of x

- assumes numerator layout of
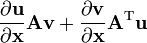
- assumes denominator layout of
a is not a function of x 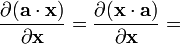
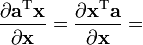

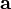
A is not a function of x
b is not a function of x


A is not a function of x 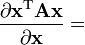
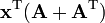

A is not a function of x
A is symmetric 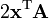
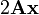
A is not a function of x 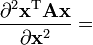

A is not a function of x
A is symmetric 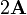
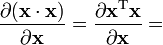
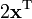
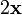
a is not a function of x,
u = u(x)
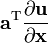
- assumes numerator layout of

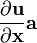
- assumes denominator layout of
a, b are not functions of x 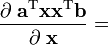


A, b, C, D, e are not functions of x 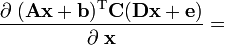
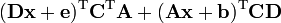

a is not a function of x 
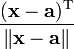
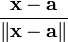
- assumes numerator layout of
Vector-by-scalar identities
Identities: vector-by-scalar Condition Expression Numerator layout, i.e. by y,
result is column vectorDenominator layout, i.e. by yT,
result is row vectora is not a function of x  [4]
[4]a is not a function of x,
u = u(x)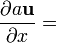
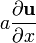
A is not a function of x,
u = u(x)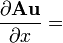
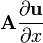
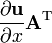
u = u(x) 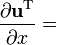
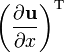
u = u(x), v = v(x) 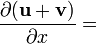

u = u(x), v = v(x) 
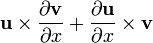
u = u(x) 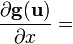
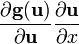
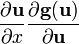
Assumes consistent matrix layout; see below. u = u(x) 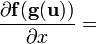
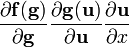

Assumes consistent matrix layout; see below.
NOTE: The formulas involving the vector-by-vector derivatives 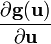 and
and  (whose outputs are matrices) assume the matrices are laid out consistent with the vector layout, i.e. numerator-layout matrix when numerator-layout vector and vice-versa; otherwise, transpose the vector-by-vector derivatives.
(whose outputs are matrices) assume the matrices are laid out consistent with the vector layout, i.e. numerator-layout matrix when numerator-layout vector and vice-versa; otherwise, transpose the vector-by-vector derivatives.
Scalar-by-matrix identities
Note that exact equivalents of the scalar product rule and chain rule do not exist when applied to matrix-valued functions of matrices. However, the product rule of this sort does apply to the differential form (see below), and this is the way to derive many of the identities below involving the trace function, combined with the fact that the trace function allows transposing and cyclic permutation, i.e.:

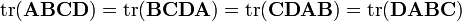
For example, to compute 

Therefore,
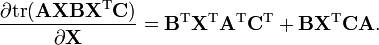
Identities: scalar-by-matrix Condition Expression Numerator layout, i.e. by XT Denominator layout, i.e. by X a is not a function of X 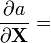 [5] [5]
[5] [5]a is not a function of X, u = u(X) 
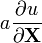
u = u(X), v = v(X) 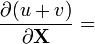

u = u(X), v = v(X) 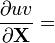

u = u(X) 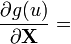
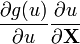
u = u(X) 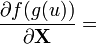
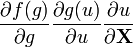
U = U(X) [6] 
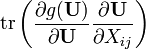
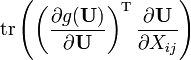
Both forms assume numerator layout for 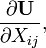
i.e. mixed layout if denominator layout for X is being used.

U = U(X), V = V(X) 

a is not a function of X,
U = U(X)

g(X) is any polynomial with scalar coefficients, or any matrix function defined by an infinite polynomial series (e.g. eX, sin(X), cos(X), ln(X), etc. using a Taylor series); g(x) is the equivalent scalar function, g′(x) is its derivative, and g′(X) is the corresponding matrix function 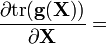

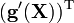
A is not a function of X [7] 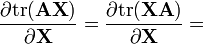
A is not a function of X [6] 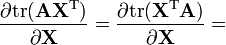
A is not a function of X [6] 

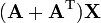
A is not a function of X [6] 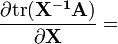
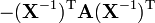
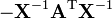
A, B are not functions of X 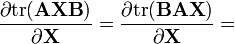

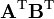
A, B, C are not functions of X 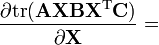
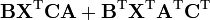

n is a positive integer [6] 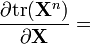

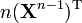
A is not a function of X,
n is a positive integer[6] 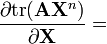

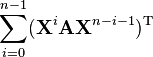
[6] 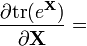
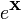

[6] 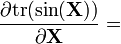

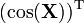
[8] 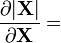

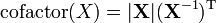
a is not a function of X [6] 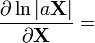 [9]
[9]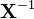

A, B are not functions of X [6] 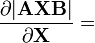
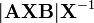
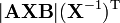
n is a positive integer [6] 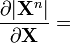
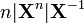

(see pseudo-inverse) [6] 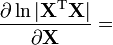

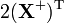
(see pseudo-inverse) [6] 
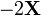
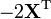
A is not a function of X,
X is square and invertible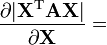

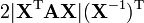
A is not a function of X,
X is non-square,
A is symmetric 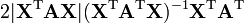
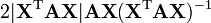
A is not a function of X,
X is non-square,
A is non-symmetric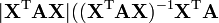
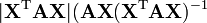
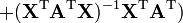
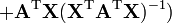
Matrix-by-scalar identities
Identities: matrix-by-scalar Condition Expression Numerator layout, i.e. by Y U = U(x) 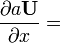

A, B are not functions of x,
U = U(x)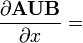

U = U(x), V = V(x) 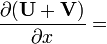
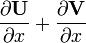
U = U(x), V = V(x) 

U = U(x), V = V(x) 

U = U(x), V = V(x) 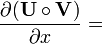

U = U(x) 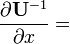
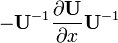
U = U(x,y) 
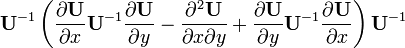
A is not a function of x, g(X) is any polynomial with scalar coefficients, or any matrix function defined by an infinite polynomial series (e.g. eX, sin(X), cos(X), ln(X), etc.); g(x) is the equivalent scalar function, g′(x) is its derivative, and g′(X) is the corresponding matrix function 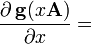

A is not a function of x 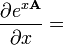

Scalar-by-scalar identities
With vectors involved
Identities: scalar-by-scalar, with vectors involved Condition Expression Any layout (assumes dot product ignores row vs. column layout) u = u(x) 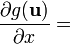
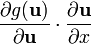
u = u(x), v = v(x) 
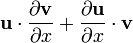
With matrices involved
Identities: scalar-by-scalar, with matrices involved[6] Condition Expression Consistent numerator layout,
i.e. by Y and XTMixed layout,
i.e. by Y and XU = U(x) 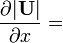

U = U(x) 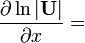
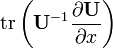
U = U(x) 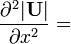
![|{\mathbf {U}}|\left[{{\rm {tr}}}\left({\mathbf {U}}^{{-1}}{\frac {\partial ^{2}{\mathbf {U}}}{\partial x^{2}}}\right)+\left({{\rm {tr}}}\left({\mathbf {U}}^{{-1}}{\frac {\partial {\mathbf {U}}}{\partial x}}\right)\right)^{2}-{{\rm {tr}}}\left(\left({\mathbf {U}}^{{-1}}{\frac {\partial {\mathbf {U}}}{\partial x}}\right)\left({\mathbf {U}}^{{-1}}{\frac {\partial {\mathbf {U}}}{\partial x}}\right)\right)\right]](/2014-wikipedia_en_all_02_2014/I/media/8/f/b/5/8fb5efb6de1f63e377271b882adf1196.png)
U = U(x) 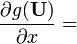
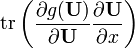
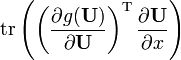
A is not a function of x, g(X) is any polynomial with scalar coefficients, or any matrix function defined by an infinite polynomial series (e.g. eX, sin(X), cos(X), ln(X), etc.); g(x) is the equivalent scalar function, g′(x) is its derivative, and g′(X) is the corresponding matrix function. 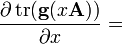
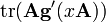
A is not a function of x 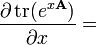
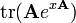
Identities in differential form
It is often easier to work in differential form and then convert back to normal derivatives. This only works well using the numerator layout.
Differential identities: scalar involving matrix [1][6] Condition Expression Result (numerator layout) 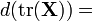

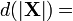

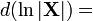
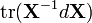
Differential identities: matrix [1][6] Condition Expression Result (numerator layout) A is not a function of X 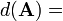

a is not a function of X 
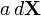



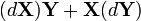
(Kronecker product) 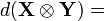
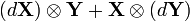
(Hadamard product) 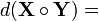

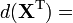

(conjugate transpose) 
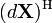
To convert to normal derivative form, first convert it to one of the following canonical forms, and then use these identities:
Conversion from differential to derivative form [1] Canonical differential form Equivalent derivative form 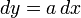

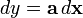



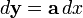
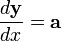
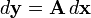
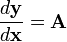
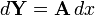

See also
- Derivative (generalizations)
- Product integral
Notes
- ↑ 1.0 1.1 1.2 1.3 1.4 Minka, Thomas P. "Old and New Matrix Algebra Useful for Statistics." December 28, 2000.
- ↑ 2.0 2.1 Magnus, Jan R.; Neudecker, Heinz (1999). Matrix Differential Calculus with Applications in Statistics and Econometrics. Wiley Series in Probability and Statistics (2nd ed.). Wiley. pp. 171–173.
- ↑
- ↑ 4.0 4.1 4.2 Here, refers to a column vector of all 0's, of size n, where n is the length of x.
- ↑ 5.0 5.1 Here, refers to a matrix of all 0's, of the same shape as X.
- ↑ 6.0 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9 6.10 6.11 6.12 6.13 6.14 6.15 Petersen, Kaare Brandt and Michael Syskind Pedersen. The Matrix Cookbook. November 14, 2008. http://matrixcookbook.com. This book uses a mixed layout, i.e. by Y in by X in

- ↑ Duchi, John C. "Properties of the Trace and Matrix Derivatives". University of California at Berkeley. Retrieved 19 July 2011.
- ↑ See Determinant#Derivative for the derivation.
- ↑ The constant a disappears in the result. This is intentional. In general,

External links
- Linear Algebra: Determinants, Inverses, Rank appendix D from Introduction to Finite Element Methods book on University of Colorado at Boulder. Uses the Hessian (transpose to Jacobian) definition of vector and matrix derivatives.
- Matrix Reference Manual, Mike Brookes, Imperial College London.
- The Matrix Cookbook, with a derivatives chapter. Uses the Hessian definition.
- Linear Algebra and its Applications (author information page; see Chapter 9 of book), Peter Lax, Courant Institute.
- Matrix Differentiation (and some other stuff), Randal J. Barnes, Department of Civil Engineering, University of Minnesota.
- Notes on Matrix Calculus, Paul L. Fackler, North Carolina State University.
- Matrix Differential Calculus (slide presentation), Zhang Le, University of Edinburgh.
- Introduction to Vector and Matrix Differentiation (notes on matrix differentiation, in the context of Econometrics), Heino Bohn Nielsen.
- A note on differentiating matrices (notes on matrix differentiation), Pawel Koval, from Munich Personal RePEc Archive.
- Vector/Matrix Calculus More notes on matrix differentiation.
- Matrix Identities (notes on matrix differentiation), Sam Roweis.