Matrix Chernoff bound
For certain applications in linear algebra, it is useful to know properties of the probability distribution of the largest eigenvalue of a finite sum of random matrices. Suppose  is a finite sequence of random matrices. Analogous to the well-known Chernoff bound for sums of scalars, a bound on the following is sought for a given parameter t:
is a finite sequence of random matrices. Analogous to the well-known Chernoff bound for sums of scalars, a bound on the following is sought for a given parameter t:
The following theorems answer this general question under various assumptions; these assumptions are named below by analogy to their classical, scalar counterparts. All of these theorems can be found in (Tropp 2010), as the specific application of a general result which is derived below. A summary of related works is given.
Matrix Gaussian and Rademacher series
Self-adjoint matrices case
Consider a finite sequence  of fixed,
self-adjoint matrices with dimension
of fixed,
self-adjoint matrices with dimension  , and let
, and let  be a finite sequence of independent standard normal or independent Rademacher random variables.
be a finite sequence of independent standard normal or independent Rademacher random variables.
Then, for all  ,
,
where
Rectangular case
Consider a finite sequence  of fixed, self-adjoint matrices with dimension
of fixed, self-adjoint matrices with dimension 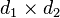 , and let be a finite sequence of independent standard normal or independent Rademacher random variables.
Define the variance parameter
, and let be a finite sequence of independent standard normal or independent Rademacher random variables.
Define the variance parameter
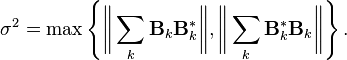
Then, for all ,
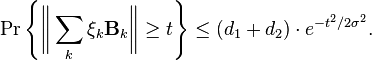
Matrix Chernoff inequalities
The classical Chernoff bounds concerns the sum of independent, nonnegative, and uniformly bounded random variables. In the matrix setting, the analogous theroem concerns a sum of positive-semidefinite random matrices subjected to a uniform eigenvalue bound.
Matrix Chernoff I
Consider a finite sequence of independent, random, self-adjoint matrices with dimension .
Assume that each random matrix satisfies

almost surely.
Define

Then
![\Pr \left\{\lambda _{{{\text{min}}}}\left(\sum _{k}{\mathbf {X}}_{k}\right)\leq (1-\delta )\mu _{{{\text{min}}}}\right\}\leq d\cdot \left[{\frac {e^{{-\delta }}}{(1-\delta )^{{1-\delta }}}}\right]^{{\mu _{{{\text{min}}}}/R}}\quad {\text{for }}\delta \in [0,1]{\text{, and}}](/2014-wikipedia_en_all_02_2014/I/media/5/6/3/b/563b1195f9300a4ec5c4c470ccfbc59b.png)
![\Pr \left\{\lambda _{{{\text{max}}}}\left(\sum _{k}{\mathbf {X}}_{k}\right)\geq (1+\delta )\mu _{{{\text{max}}}}\right\}\leq d\cdot \left[{\frac {e^{{\delta }}}{(1+\delta )^{{1+\delta }}}}\right]^{{\mu _{{{\text{max}}}}/R}}\quad {\text{for }}\delta \geq 0.](/2014-wikipedia_en_all_02_2014/I/media/e/c/5/1/ec51975319cf057dcf0ced94b4bba94c.png)
Matrix Chernoff II
Consider a sequence  of independent, random, self-adjoint matrices that satisfy
of independent, random, self-adjoint matrices that satisfy

almost surely.
Compute the minimum and maximum eigenvalues of the average expectation,

Then
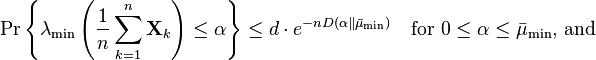

The binary information divergence is defined as
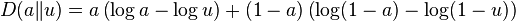
for ![a,u\in [0,1]](/2014-wikipedia_en_all_02_2014/I/media/8/c/f/4/8cf48aca754f557b747522378965bcc7.png) .
.
Matrix Bennett and Bernstein inequalities
In the scalar setting, Bennett and Bernstein inequalities describe the upper tail of a sum of independent, zero-mean random variables that are either bounded or subexponential. In the matrix case, the analogous results concern a sum of zero-mean random matrices.
Bounded case
Consider a finite sequence of independent, random, self-adjoint matrices with dimension .
Assume that each random matrix satisfies
almost surely.
Compute the norm of the total variance,
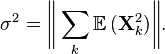
Then, the following chain of inequalities holds for all :

The function 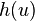 is defined as
is defined as  for
for 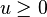 .
.
Subexponential case
Consider a finite sequence of independent, random, self-adjoint matrices with dimension .
Assume that

for  .
.
Compute the variance parameter,
Then, the following chain of inequalities holds for all :
Rectangular case
Consider a finite sequence  of independent, random, matrices with dimension .
Assume that each random matrix satisfies
of independent, random, matrices with dimension .
Assume that each random matrix satisfies
almost surely. Define the variance parameter
Then, for all
Matrix Azuma, Hoeffding, and McDiarmid inequalities
Matrix Azuma
The scalar version of Azuma's inequality states that a scalar martingale exhibits normal concentration about its mean value, and the scale for deviations is controlled by the total maximum squared range of the difference sequence. The following is the extension in matrix setting.
Consider a finite adapted sequence of self-adjoint matrices with dimension , and a fixed sequence of self-adjoint matrices that satisfy
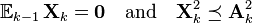
almost surely.
Compute the variance parameter
Then, for all
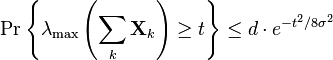
The constant 1/8 can be improved to 1/2 when there is additional information available. One case occurs when each summand  is conditionally symmetric.
Another example requires the assumption that commutes almost surely with
is conditionally symmetric.
Another example requires the assumption that commutes almost surely with  .
.
Matrix Hoeffding
Placing addition assumption that the summands in Matrix Azuma are independent gives a matrix extension of Hoeffding's inequalities.
Consider a finite sequence of independent, random, self-adjoint matrices with dimension , and let be a sequence of fixed self-adjoint matrices.
Assume that each random matrix satisfies
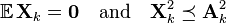
almost surely.
Then, for all
where
An improvement of this result was established in (Mackey et al. 2012):
for all
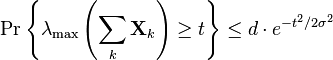
where
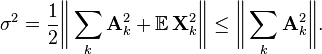
Matrix bounded difference (McDiarmid)
In scalar setting, McDiarmid's inequality provides one common way of bounding the differences by applying Azuma's inequality to a Doob martingale. A version of the bounded differences inequality holds in the matrix setting.
Let  be an independent, family of random variables, and let
be an independent, family of random variables, and let  be a function that maps
be a function that maps  variables to a self-adjoint matrix of dimension .
Consider a sequence of fixed self-adjoint matrices that satisfy
variables to a self-adjoint matrix of dimension .
Consider a sequence of fixed self-adjoint matrices that satisfy
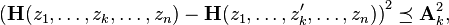
where  and
and 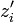 range over all possible values of
range over all possible values of 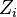 for each index
for each index  .
Compute the variance parameter
.
Compute the variance parameter
Then, for all
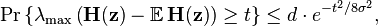
where 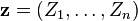 .
.
Survey of related theorems
The first bounds of this type were derived by (Ahlswede & Winter 2003). Recall the theorem above for self-adjoint matrix Gaussian and Rademacher bounds:
For a finite sequence of fixed,
self-adjoint matrices with dimension and for a finite sequence of independent standard normal or independent Rademacher random variables, then
where
Ahlswede and Winter would give the same result, except with
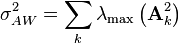 .
.
By comparison, the  in the theorem above commutes
in the theorem above commutes  and
and  ; that is, it is the largest eigenvalue of the sum rather than the sum of the largest eigenvalues. It is never larger than the Ahlswede–Winter value (by the norm triangle inequality), but can be much smaller. Therefore, the theorem above gives a tighter bound than the Ahlswede–Winter result.
; that is, it is the largest eigenvalue of the sum rather than the sum of the largest eigenvalues. It is never larger than the Ahlswede–Winter value (by the norm triangle inequality), but can be much smaller. Therefore, the theorem above gives a tighter bound than the Ahlswede–Winter result.
The chief contribution of (Ahlswede & Winter 2003) was the extension of the Laplace-transform method used to prove the scalar Chernoff bound (see Chernoff bound#Theorem for additive form (absolute error)) to the case of self-adjoint matrices. The procedure given in the derivation below. All of the recent works on this topic follow this same procedure, and the chief differences follow from subsequent steps. Ahlswede & Winter use the Golden–Thompson inequality to proceed, whereas Tropp (Tropp 2010) uses Lieb's Theorem.
Suppose one wished to vary the length of the series (n) and the dimensions of the matrices (d) while keeping the right-hand side approximately constant. Then n must vary approximately as the log of d. Several papers have attempted to establish a bound without a dependence on dimensions. Rudelson and Vershynin (Rudelson & Vershynin 2007) give a result for matrices which are the outer product of two vectors. (Magen & Zouzias 2010) provide a result without the dimensional dependence for low rank matrices. The original result was derived independently from the Ahlswede–Winter approach, but (Oliveira 2010b) proves a similar result using the Ahlswede–Winter approach.
Finally, Oliveira (Oliviera 2010a) proves a result for matrix martingales independently from the Ahlswede–Winter framework. Tropp (Tropp 2011) slightly improves on the result using the Ahlswede–Winter framework. Neither result is presented in this article.
Derivation and proof
Ahlswede and Winter
The Laplace transform argument found in (Ahlswede & Winter 2003) is a significant result in its own right:
Let 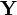 be a random self-adjoint matrix. Then
be a random self-adjoint matrix. Then
![\Pr \left\{\lambda _{\max(}Y)\geq t\right\}\leq \inf _{{\theta >0}}\left\{e^{{-\theta t}}\cdot \operatorname {E}\left[\operatorname {tr}e^{{\theta {\mathbf {Y}}}}\right]\right\}.](/2014-wikipedia_en_all_02_2014/I/media/e/c/9/1/ec913388419f9db6dd56a3b4e6fddfee.png)
To prove this, fix 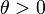 . Then
. Then
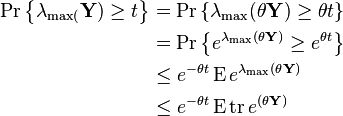
The second-to-last inequality is Markov's inequality. The last inequality holds since 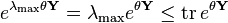 . Since the left-most quantity is independent of
. Since the left-most quantity is independent of 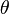 , the infimum over remains an upper bound for it.
, the infimum over remains an upper bound for it.
Thus, our task is to understand 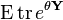 Nevertheless, since trace and expectation are both linear, we can commute them, so it is sufficient to consider
Nevertheless, since trace and expectation are both linear, we can commute them, so it is sufficient to consider  , which we call the matrix generating function. This is where the methods of (Ahlswede & Winter 2003) and (Tropp 2010) diverge. The immediately following presentation follows (Ahlswede & Winter 2003).
, which we call the matrix generating function. This is where the methods of (Ahlswede & Winter 2003) and (Tropp 2010) diverge. The immediately following presentation follows (Ahlswede & Winter 2003).
The Golden–Thompson inequality implies that
![\operatorname {tr}{\mathbf {M}}_{{{\mathbf {X}}_{1}+{\mathbf {X}}_{2}}}(\theta )\leq \operatorname {tr}\left[\left(\operatorname {E}e^{{\theta {\mathbf {X}}_{1}}}\right)\left(\operatorname {E}e^{{\theta {\mathbf {X}}_{2}}}\right)\right]=\operatorname {tr}{\mathbf {M}}_{{{\mathbf {X}}_{1}}}(\theta ){\mathbf {M}}_{{{\mathbf {X}}_{2}}}(\theta )](/2014-wikipedia_en_all_02_2014/I/media/3/0/6/8/3068c95b54b72c960ca2e9393245ce37.png) , where we used the linearity of expectation several times.
, where we used the linearity of expectation several times.
Suppose 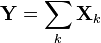 . We can find an upper bound for
. We can find an upper bound for 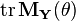 by iterating this result. Noting that
by iterating this result. Noting that 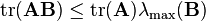 , then
, then
![\operatorname {tr}{\mathbf {M}}_{{\mathbf {Y}}}(\theta )\leq \operatorname {tr}\left[\left(\operatorname {E}e^{{\sum _{{k=1}}^{{n-1}}\theta {\mathbf {X}}_{k}}}\right)\left(\operatorname {E}e^{{\theta {\mathbf {X}}_{n}}}\right)\right]\leq \operatorname {tr}\left(\operatorname {E}e^{{\sum _{{k=1}}^{{n-1}}\theta {\mathbf {X}}_{k}}}\right)\lambda _{{\max }}(\operatorname {E}e^{{\theta {\mathbf {X}}_{n}}}).](/2014-wikipedia_en_all_02_2014/I/media/b/0/4/d/b04da6be7ccb81307672ca0300fff150.png)
Iterating this, we get
![\operatorname {tr}{\mathbf {M}}_{{\mathbf {Y}}}(\theta )\leq (\operatorname {tr}{\mathbf {I}})\left[\Pi _{k}\lambda _{\max(}\operatorname {E}e^{{\theta {\mathbf {X}}_{k}}})\right]=de^{{\sum _{k}\lambda _{\max }\left(\log \operatorname {E}e^{{\theta {\mathbf {X}}_{k}}}\right)}}](/2014-wikipedia_en_all_02_2014/I/media/4/d/1/3/4d13d3694d51ce81ba7acfe7bdecfe48.png)
So far we have found a bound with an infimum over . In turn, this can be bounded. At any rate, one can see how the Ahlswede–Winter bound arises as the sum of largest eigenvalues.
Tropp
The major contribution of (Tropp 2010) is the application of Lieb's theorem where (Ahlswede & Winter 2003) had applied the Golden–Thompson inequality. Tropp's corollary is the following: If 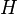 is a fixed self-adjoint matrix and
is a fixed self-adjoint matrix and  is a random self-adjoint matrix, then
is a random self-adjoint matrix, then
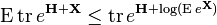
Proof: Let  . Then Lieb's theorem tells us that
. Then Lieb's theorem tells us that

is concave. The final step is to use Jensen's inequality to move the expectation inside the function:

This gives us the major result of the paper: the subadditivity of the log of the matrix generating function.
Subadditivity of log mgf
Let be a finite sequence of independent, random self-adjoint matrices. Then for all 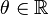 ,
,
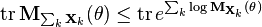
Proof: It is sufficient to let  . Expanding the definitions, we need to show that
. Expanding the definitions, we need to show that
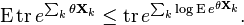
To complete the proof, we use the law of total expectation. Let 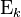 be the expectation conditioned on
be the expectation conditioned on  . Since we assume all the
. Since we assume all the 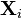 are independent,
are independent,
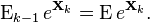
Define 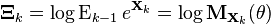 .
.
Finally, we have
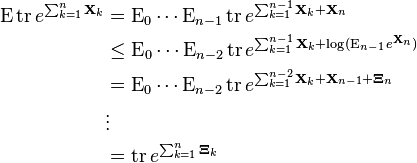
where at every step m we use Tropp's corollary with
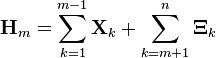
Master tail bound
The following is immediate from the previous result:
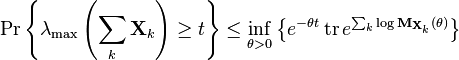
All of the theorems given above are derived from this bound; the theorems consist in various ways to bound the infimum. These steps are significantly simpler than the proofs given.
References
- Ahlswede, R.; Winter, A. (2003). "Strong Converse for Identification via Quantum Channels". IEEE Transactions on Information Theory 48 (3): 569–579. arXiv:quant-ph/0012127.
- Mackey, L.; Jordan, M. I.; Chen, R. Y.; Farrell, B.; Tropp, J. A. (2012). "Matrix Concentration Inequalities via the Method of Exchangeable Pairs". arXiv:1201.6002 [math.PR].
- Magen, A.; Zouzias, A. (2010). "Low-Rank Matrix-valued Chernoff Bounds and Approximate Matrix Multiplication". arXiv:1005.2724 [math].
- Oliveira, R.I. (2010). "Concentration of the adjacency matrix and of the Laplacian in random graphs with independent edges". arXiv:0911.0600 [math].
- Oliveira, R.I. (2010). "Sums of random Hermitian matrices and an inequality by Rudelson". arXiv:1004.3821 [math].
- Rudelson, M.; Vershynin, R. (2007). 21. "Sampling from large matrices: an approach through geometric functional analysis". J. Assoc. Comput. Mach. (4 ed.) 54. arXiv:math/9608208.
- Tropp, J. (2011). "Freedman's inequality for matrix martingales". arXiv:1101.3039 [math].
- Tropp, J. (2010). "User-friendly tail bounds for sums of random matrices". arXiv:1004.4389 [math].