Lyapunov vector
In applied mathematics and dynamical system theory, Lyapunov vectors, named after Aleksandr Lyapunov, describe characteristic expanding and contracting directions of a dynamical system. They have been used in predictability analysis and as initial perturbations for ensemble forecasting in numerical weather prediction.[1] In modern practice they are often replaced by bred vectors for this purpose.[2]
Mathematical description

- Lyapunov vectors are defined along the trajectories of a dynamical system. If the system can be described by a d-dimensional state vector
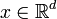 the Lyapunov vectors
the Lyapunov vectors  ,
, 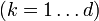 point in the directions in which an infinitesimal perturbation will grow asymptotically, exponentially at an average rate given by the Lyapunov exponents
point in the directions in which an infinitesimal perturbation will grow asymptotically, exponentially at an average rate given by the Lyapunov exponents 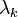 . When expanded in terms of Lyapunov vectors a perturbation asymptotically aligns with the Lyapunov vector in that expansion corresponding to the largest Lyapunov exponent as this direction outgrows all others. Therefore almost all perturbations align asymptotically with the Lyapunov vector corresponding to the largest Lyapunov exponent in the system.[3]
. When expanded in terms of Lyapunov vectors a perturbation asymptotically aligns with the Lyapunov vector in that expansion corresponding to the largest Lyapunov exponent as this direction outgrows all others. Therefore almost all perturbations align asymptotically with the Lyapunov vector corresponding to the largest Lyapunov exponent in the system.[3] - In some cases Lyapunov vectors may not exist.[4]
- Lyapunov vectors are not necessarily orthogonal.
- Lyapunov vectors are not identical with the local principal expanding and contracting directions, i.e. the eigenvectors of the Jacobian. While the latter require only local knowledge of the system, the Lyapunov vectors are influenced by all Jacobians along a trajectory.
- The Lyapunov vectors for a periodic orbit are the Floquet vectors of this orbit.
Numerical method
If the dynamical system is differentiable and the Lyapunov vectors exist, they can be found by forward and backward iterations of the linearized system along a trajectory.[5] Let 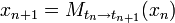 map the system with state vector
map the system with state vector  at time
at time  to the state
to the state 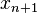 at time
at time 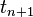 . The linearization of this map, i.e. the Jacobian matrix
. The linearization of this map, i.e. the Jacobian matrix 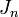 describes the change of an infinitesimal perturbation
describes the change of an infinitesimal perturbation  . That is
. That is
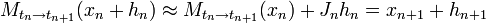
Starting with an identity matrix 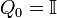 the iterations
the iterations
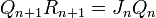
where  is given by the Gram-Schmidt QR decomposition of
is given by the Gram-Schmidt QR decomposition of 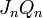 , will asymptotically converge to matrices that depend only on the points of a trajectory but not on the initial choice of
, will asymptotically converge to matrices that depend only on the points of a trajectory but not on the initial choice of  . The rows of the orthogonal matrices
. The rows of the orthogonal matrices  define a local orthogonal reference frame at each point and the first
define a local orthogonal reference frame at each point and the first  rows span the same space as the Lyapunov vectors corresponding to the largest Lyapunov exponents. The upper triangular matrices
rows span the same space as the Lyapunov vectors corresponding to the largest Lyapunov exponents. The upper triangular matrices 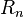 describe the change of an infinitesimal perturbation from one local orthogonal frame to the next. The diagonal entries
describe the change of an infinitesimal perturbation from one local orthogonal frame to the next. The diagonal entries 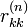 of are local growth factors in the directions of the Lyapunov vectors. The Lyapunov exponents are given by the average growth rates
of are local growth factors in the directions of the Lyapunov vectors. The Lyapunov exponents are given by the average growth rates

and by virtue of stretching, rotating and Gram-Schmidt orthogonalization the Lyapunov exponents are ordered as 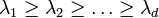 . When iterated forward in time a random vector contained in the space spanned by the first columns of will almost surely asymptotically grow with the largest Lyapunov exponent and align with the corresponding Lyapunov vector. In particular, the first column of will point in the direction of the Lyapunov vector with the largest Lyapunov exponent if
. When iterated forward in time a random vector contained in the space spanned by the first columns of will almost surely asymptotically grow with the largest Lyapunov exponent and align with the corresponding Lyapunov vector. In particular, the first column of will point in the direction of the Lyapunov vector with the largest Lyapunov exponent if  is large enough. When iterated backward in time a random vector contained in the space spanned by the first columns of
is large enough. When iterated backward in time a random vector contained in the space spanned by the first columns of 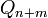 will almost surely, asymptotically align with the Lyapunov vector corresponding to the th largest Lyapunov exponent, if and
will almost surely, asymptotically align with the Lyapunov vector corresponding to the th largest Lyapunov exponent, if and  are sufficiently large. Defining
are sufficiently large. Defining 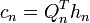 we find
we find 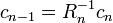 . Choosing the first entries of
. Choosing the first entries of 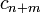 randomly and the other entries zero, and iterating this vector back in time, the vector
randomly and the other entries zero, and iterating this vector back in time, the vector 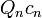 aligns almost surely with the Lyapunov vector
aligns almost surely with the Lyapunov vector  corresponding to the th largest Lyapunov exponent if and are sufficiently large. Since the iterations will exponentially blow up or shrink a vector it can be re-normalized at any iteration point without changing the direction.
corresponding to the th largest Lyapunov exponent if and are sufficiently large. Since the iterations will exponentially blow up or shrink a vector it can be re-normalized at any iteration point without changing the direction.
References
- ↑ Kalnay, E. (2007), "Atmospheric Modeling, Data Assimilation and Predictability", Cambridge: Cambridge University Press
- ↑ Kalnay E, Corazza M, Cai M. "Are Bred Vectors the same as Lyapunov Vectors?", EGS XXVII General Assembly, (2002)
- ↑ Edward Ott (2002), "Chaos in Dynamical Systems", second edition, Cambridge University Press.
- ↑ W. Ott and J. A. Yorke, "When Lyapunov exponents fail to exist", Phys. Rev. E 78, 056203 (2008)
- ↑ F Ginelli, P Poggi, A Turchi, H Chaté, R Livi, and A Politi, "Characterizing Dynamics with Covariant Lyapunov Vectors", Phys. Rev. Lett. 99, 130601 (2007), arXiv