Logrank test
In statistics, the log-rank test is a hypothesis test to compare the survival distributions of two samples. It is a nonparametric test and appropriate to use when the data are right skewed and censored (technically, the censoring must be non-informative). It is widely used in clinical trials to establish the efficacy of a new treatment in comparison with a control treatment when the measurement is the time to event (such as the time from initial treatment to a heart attack). The test is sometimes called the Mantel–Cox test, named after Nathan Mantel and David Cox. The log-rank test can also be viewed as a time-stratified Cochran–Mantel–Haenszel test.
The test was first proposed by Nathan Mantel and was named the log-rank test by Richard and Julian Peto.[1][2][3]
Definition
The log-rank test statistic compares estimates of the hazard functions of the two groups at each observed event time. It is constructed by computing the observed and expected number of events in one of the groups at each observed event time and then adding these to obtain an overall summary across all time points where there is an event.
Let j = 1, ..., J be the distinct times of observed events in either group. For each time  , let
, let  and
and 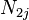 be the number of subjects "at risk" (have not yet had an event or been censored) at the start of period in the two groups (often treatment vs. control), respectively. Let
be the number of subjects "at risk" (have not yet had an event or been censored) at the start of period in the two groups (often treatment vs. control), respectively. Let 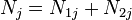 . Let
. Let  and
and 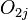 be the observed number of events in the groups respectively at time , and define
be the observed number of events in the groups respectively at time , and define 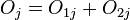 .
.
Given that 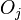 events happened across both groups at time , under the null hypothesis (of the two groups having identical survival and hazard functions) has the hypergeometric distribution with parameters
events happened across both groups at time , under the null hypothesis (of the two groups having identical survival and hazard functions) has the hypergeometric distribution with parameters  , , and . This distribution has expected value
, , and . This distribution has expected value 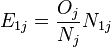 and variance
and variance 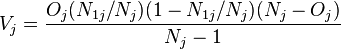 .
.
The log-rank statistic compares each to its expectation  under the null hypothesis and is defined as
under the null hypothesis and is defined as
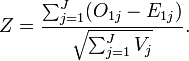
Asymptotic distribution
If the two groups have the same survival function, the log-rank statistic is approximately standard normal. A one-sided level  test will reject the null hypothesis if
test will reject the null hypothesis if  where
where 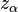 is the upper quantile of the standard normal distribution. If the hazard ratio is
is the upper quantile of the standard normal distribution. If the hazard ratio is 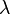 , there are
, there are  total subjects,
total subjects,  is the probability a subject in either group will eventually have an event (so that
is the probability a subject in either group will eventually have an event (so that  is the expected number of events at the time of the analysis), and the proportion of subjects randomized to each group is 50%, then the log-rank statistic is approximately normal with mean
is the expected number of events at the time of the analysis), and the proportion of subjects randomized to each group is 50%, then the log-rank statistic is approximately normal with mean 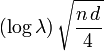 and variance 1.[4] For a one-sided level test with power
and variance 1.[4] For a one-sided level test with power 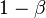 , the sample size required is
, the sample size required is
 where and
where and 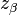 are the quantiles of the standard normal distribution.
are the quantiles of the standard normal distribution.
Joint distribution
Suppose  and
and  are the log-rank statistics at two different time points in the same study ( earlier). Again, assume the hazard functions in the two groups are proportional with hazard ratio and
are the log-rank statistics at two different time points in the same study ( earlier). Again, assume the hazard functions in the two groups are proportional with hazard ratio and 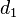 and
and  are the probabilities that a subject will have an event at the two time points where
are the probabilities that a subject will have an event at the two time points where  . and are approximately bivariate normal with means
. and are approximately bivariate normal with means 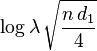 and
and 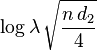 and correlation
and correlation 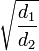 . Calculations involving the joint distribution are needed to correctly maintain the error rate when the data are examined multiple times within a study by a Data Monitoring Committee.
. Calculations involving the joint distribution are needed to correctly maintain the error rate when the data are examined multiple times within a study by a Data Monitoring Committee.
Relationship to other statistics
- The log-rank test has been shown to be too permissive a test, allowing significant results for survivorship prediction models that have low accuracy. The F* test was developed in response to these observations and has been shown to be more critical and to track accuracy of the prediction models with higher fidelity.[5]
- The log-rank statistic can be derived as the score test for the Cox proportional hazards model comparing two groups. It is therefore asymptotically equivalent to the likelihood ratio test statistic based from that model.
- The log-rank statistic is asymptotically equivalent to the likelihood ratio test statistic for any family of distributions with proportional hazard alternative. For example, if the data from the two samples have exponential distributions.
- If
 is the log-rank statistic,
is the log-rank statistic,  is the number of events observed, and
is the number of events observed, and 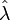 is the estimate of the hazard ratio, then
is the estimate of the hazard ratio, then  . This relationship is useful when two of the quantities are known (e.g. from a published article), but the third one is needed.
. This relationship is useful when two of the quantities are known (e.g. from a published article), but the third one is needed.
- The log-rank statistic can be used when observations are censored. If censored observations are not present in the data then the Wilcoxon rank sum test is appropriate.
- The log-rank statistic gives all calculations the same weight, regardless of the time at which an event occurs. The Peto logrank statistic gives more weight to earlier events when there are a large number of observations.
See also
References
- ↑ Mantel, Nathan (1966). "Evaluation of survival data and two new rank order statistics arising in its consideration.". Cancer Chemotherapy Reports 50 (3): 163–70. PMID 5910392.
- ↑ Peto, Richard; Peto, Julian (1972). "Asymptotically Efficient Rank Invariant Test Procedures". Journal of the Royal Statistical Society, Series A (Blackwell Publishing) 135 (2): 185–207. doi:10.2307/2344317. JSTOR 2344317.
- ↑ Harrington, David (2005). "Linear Rank Tests in Survival Analysis". Encyclopedia of Biostatistics. Wiley Interscience. doi:10.1002/0470011815.b2a11047.
- ↑ Schoenfeld, D (1981). "The asymptotic properties of nonparametric tests for comparing survival distributions". Biometrika 68: 316–319. JSTOR 2335833.
- ↑ Berty, H. P.; Shi, H.; Lyons-Weiler, J. (2010). "Determining the statistical significance of survivorship prediction models". J Eval Clin Pract 16 (1): 155–165. doi:10.1111/j.1365-2753.2009.01199.x. PMID 20367827.
External links
- Bland, J. M.; Altman, D. G. (2004). "The logrank test". BMJ 328 (7447): 1073. doi:10.1136/bmj.328.7447.1073. PMC 403858. PMID 15117797.