Lexical density
In computational linguistics, lexical density constitutes the estimated measure of content per functional (grammatical) and lexical units (lexemes) in total. It is used in discourse analysis as a descriptive parameter which varies with register and genre. Spoken texts tend to have a lower lexical density than written ones, for example.
Lexical density may be determined thus:
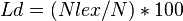
Where:
Ld = the analysed text's lexical density
NLex = the number of lexical word tokens (nouns, adjectives, verbs, adverbs) in the analysed text
N = the number of all tokens (total number of words) in the analysed text
(The variable symbols applied herein are by no means conventional, they are simply random chosen designations that serve to illustrate the example in question.)
See also
Further reading
- Ure, J (1971). Lexical density and register differentiation. In G. Perren and J.L.M. Trim (eds), Applications of Linguistics, London: Cambridge University Press. 443-452.
External links
- Lexical Density Test definition NOTE: This page gives an incorrect formula and confuses lexical density with type/token ratio.
- Lexical density 'Textalyser'