LINPACK benchmarks
| Original author(s) | Jack Dongarra, Jim Bunch, Cleve Moler, and Gilbert Stewart |
|---|---|
| Initial release | 1979 |
| Website | www.netlib.org/benchmark/performance.ps |
The LINPACK Benchmarks are a measure of a system's floating point computing power. Introduced by Jack Dongarra, they measure how fast a computer solves a dense n by n system of linear equations Ax = b, which is a common task in engineering.
The latest version of these benchmarks is used to build the Top500 list, ranking the world's most powerful supercomputers.[1]
The aim is to approximate how fast a computer will perform when solving real problems. It is a simplification, since no single computational task can reflect the overall performance of a computer system. Nevertheless, the LINPACK benchmark performance can provide a good correction over the peak performance provided by the manufacturer. The peak performance is the maximal theoretical performance a computer can achieve, calculated as the machine's frequency, in cycles per second, times the number of operations per cycle it can perform. The actual performance will always be lower than the peak performance.[2] The performance of a computer is a complex issue that depends on many interconnected variables. The performance measured by the LINPACK benchmark consists of the number of 64-bit floating-point operations, generally additions and multiplications, a computer can perform per second, also known as FLOPS. However, a computer's performance when running actual applications is likely to be far behind the maximal performance it achieves running the appropriate LINPACK benchmark .[3]
The name of these benchmarks comes from the LINPACK package, a collection of algebra Fortran subroutines widely used in the 80s, and initially tightly linked to the LINPACK benchmark. The LINPACK package has been since then replaced by other libraries.
History
The LINPACK benchmark report appeared first in 1979 as an appendix to the LINPACK user's manual .[4] It was designed to help users estimate the time required by their systems to solve a problem using the LINPACK package, by extrapolating the performance results obtained by 23 different computers solving a matrix problem of size 100. This size was chosen due to memory limitations at that time. 10000 floating-point entries from -1 to 1 are randomly generated to fill in a general, dense matrix. Then, LU decomposition with partial pivoting is used for the timing. Over the years, additional versions with different problem sizes, like matrices of order 300 and 1000, and constraints were released, allowing new optimization opportunities as hardware architectures started to implement matrix-vector and matrix-matrix operations .[5] Parallel processing was also introduced in the LINPACK Parallel benchmark .[2] Finally, 1991 [6] saw the appearance of a version of the benchmark that allowed solving problems of arbitrary size, enabling High Performance Computers to get near to their asymptotic performance. Two years later this benchmark was used for the first Top500 list.
The benchmarks
LINPACK 100
LINPACK 100 is very similar to the original benchmark published in 1979 along with the LINPACK users' manual. The solution is obtained by Gaussian elimination with partial pivoting, with 2/3n³ + 2n² floating point operations where n is 100, the order of the dense matrix A that defines the problem. Its small size and the lack of software flexibility doesn't allow most modern computers to reach their performance limits. However, it can still be useful to predict performances in numerically intensive user written code using compiler optimization.[2]
LINPACK 1000
LINPACK 1000 can provide a performance nearer to the machine's limit because, in addition to offering a bigger problem size, a matrix of order 1000, changes in the algorithm are possible. The only constraints are that the relative accuracy can't be reduced and the number of operations will always be considered to be 2/3n³ + 2n², with n = 1000.[2]
HPLinpack
The previous benchmarks are not suitable for testing parallel computers, [7] and the so-called Linpack’s Highly Parallel Computing benchmark, or HPLinpack benchmark, was introduced. In HPLinpack the size n of the problem can be made as large as it is needed to optimize the performance results of the machine. Once again, 2/3n³ + 2n² will be taken as the operation count, with independence of the algorithm used. Strassen algorithm is not allowed because it distorts the real execution rate .[8] The accuracy must be such that the following expression is satisfied:
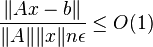 , where
, where  is the machine's precision, and n is the size of the problem
,[9]
is the machine's precision, and n is the size of the problem
,[9]  is the matrix norm and
is the matrix norm and 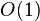 corresponds to the big-O notation.
corresponds to the big-O notation.
For each computer system, the following quantities are reported:[2]
- Rmax: the performance in Gflop/s for the largest problem run on a machine .
- Nmax: the size of the largest problem run on a machine .
- N1/2: the size where half the Rmax execution rate is achieved.
- Rpeak: the theoretical peak performance Gflop/s for the machine.
These results are used to compile the Top500 list twice a year, with the world's most powerful computers .[1]
LINPACK benchmark implementations
The previous section describes the ground rules for the benchmarks. The actual implementation of the program can diverge, with some examples being available in Fortran ,[10] C [11] or Java .[12]
HPL
HPL is a portable implementation of HPLinpack that was written in C, originally as a guideline, but that is now widely used to provide data for the Top500 list, though other technologies and packages can be used. HPL generates a linear system of equations of order n and solves it using LU decomposition with partial row pivoting. It requires installed implementations of either MPI and BLAS or VSIPL to run .[13]
Coarsely, the algorithm has the following characteristics:[14][15]
- Cyclic data distribution in 2D blocks.
- LU factorization using the right-looking variant with various depths of look-ahead.
- Recursive panel factorization.
- Six different panel broadcasting variants.
- Bandwidth reducing swap-broadcast algorithm.
- Backward substitution with look-ahead of depth 1.
Criticism
The LINPACK benchmark is said to have succeeded because of the scalability[16] of HPLinpack, the fact that it generates a single number, making the results easily comparable and the extensive historical data base it has associated.[17] However, soon after its release, the LINPACK benchmark was criticized for providing performance levels "generally unobtainable by all but a very few programmers who tediously optimize their code for that machine and that machine alone",[18] because it only tests the resolution of dense linear systems, what is not representative of all the operations usually performed in scientific computing.[19] Jack Dongarra, the main driving force behind the LINPACK benchmarks, said that, while they only emphasize "peak" CPU speed and number of CPUs, not enough stress is given to local bandwidth and the network.[20] Thom Dunning, director of the National Center for Supercomputing Applications, had this to say about the LINPACK benchmark: "The Linpack benchmark is one of those interesting phenomena -- almost anyone who knows about it will deride its utility. They understand its limitations but it has mindshare because it's the one number we've all bought into over the years."[21] According to Dongarra, "the organizers of the Top500 are actively looking to expand the scope of the benchmark reporting" because "it is important to include more performance characteristic and signatures for a given system".[22] One of the possibilities that is being considered to extend the benchmark for the Top500 is the HPC Challenge Benchmark Suite. [23] With the advent of petascale computers, traversed edges per second have started to emerge as an alternative metric to FLOPS measured by LINPACK.
The running time issue
According to Jack Dongarra, the running time required to obtain good performance results with HPLinpack are expected to increase. In a conference held in 2010, he said he expects running times of 2.5 days in "a few years".[24]
See also
References
- ↑ 1.0 1.1 "The Linpack Benchmark, TOP500 Supercomputing Sites". Retrieved 11-01-2012.
- ↑ 2.0 2.1 2.2 2.3 2.4 Dongarra, Jack J.; Luszczek, Piotr; Petitet, Antoine (2003), "The LINPACK Benchmark: past, present and future", Concurrency and Computation: Practice and Experience (John Wiley & Sons, Ltd.): 803–820
- ↑ Jack Dongarra interview by Sander Olson
- ↑ Dongarra, J.J.; Moler, C.B.; Bunch, J.R.; Stewart, G.W. (1979), LINPACK: users' guide, SIAM
- ↑ Dongarra, Jack (1988), "The LINPACK benchmark: An explanation", Supercomputing (Springer Berlin/Heidelberg): 456–474
- ↑ High Performance Linpack Benchmark, retrieved 10-01-2012
- ↑ Bailey, D.H.; Barszcz, E.; Barton, J.T.; Browning, D.S.; Carter, R.L.; Dagum, L.; Fatoohi, R.A.; Frederickson, P.O.; Lasinski, T.A.; Schreiber, R.S.; Simon, H.D.; Venkatakrishnan, V.; Weeratunga, S.K. (1991), The NAS parallel benchmarks summary and preliminary results, "Supercomputing '91. Proceedings of the 1991 ACM/IEEE Conference", Supercomputing: 158–165
- ↑ "LINPACK FAQ - Can I use Strassen’s Method when doing the matrix multiples in the HPL benchmark or for the Top500 run?". Retrieved 12-01-2012.
- ↑ "LINPACK FAQ - To what accuracy must be the solution conform?". Retrieved 12-01-2012.
- ↑ "Linpack benchmark program in Fortran". Retrieved 12-01-2012.
- ↑ "Linpack benchmark program in C". Retrieved 12-01-2012.
- ↑ "Linpack benchmark program in Java". Retrieved 12-01-2012.
- ↑ "HPL - A Portable Implementation of the High-Performance Linpack Benchmark for Distributed-Memory Computers". Retrieved 12-01-2012.
- ↑ "HPL algorithm". 12-01-2012.
- ↑ "HPL overview". Retrieved 12-01-2012.
- ↑ "An interview with supercomputer legend Jack Dongarra". 2012-01-13.
- ↑ Haigh, Thomas (2004), An interview with Jack J. Dongarra, "LINPACK is a benchmark that people often cite because there’s such a historical data base of information there, because it’s fairly easy to run, it’s fairly easy to understand, and it captures in some sense the best and worst of programming."
- ↑ Hammond, Steven (1995), Beyond Machoflops: Getting MPPs Into the Production Environment
- ↑ Gahvari, Hormozd; Hoemmen, Mark; Demmel, James; Yelick, Katherine (2006), "Benchmarking Sparse Matrix-Vector Multiply in Five Minutes", SPEC Benchmark Workshop
- ↑ Dongarra, Jack J. (2007), "The HPC Challenge Benchmark: A Candidate for Replacing Linpack in the Top500?", SPEC Benchmark Workshop
- ↑ Christopher Mims (2010-11-08). "Why China's New Supercomputer Is Only Technically the World's Fastest". Retrieved 2011-09-22.
- ↑ Meuer, Martin (2002-05-24), An interview with supercomputing legend jack dongarra, retrieved 11-01-2012
- ↑ Luszczek, Piotr; Dongarra, Jack J.; Koester, David; Rabenseifner, Rolf; Lucas, Bob; Kepner, Jeremy; Mccalpin, John; Bailey, David et al. (2005), Introduction to the HPC Challenge Benchmark Suite
- ↑ Dongarra, Jack J. (2010), "LINPACK Benchmark with Time Limits on Multicore & GPU Based Accelerators", International Supercomputing Conference
External links
- http://www.netlib.org/benchmark/linpackjava/ a web-based LINPACK benchmark
- http://www.netlib.org/benchmark/hpl/ The HPL benchmark used in the TOP500