Kernel trick
For machine learning algorithms, the kernel trick is a way of mapping observations from a general set S into an inner product space V (equipped with its natural norm), without having to compute the mapping explicitly, because the observations will gain meaningful linear structure in V. Linear classifications in V are equivalent to generic classifications in S. The trick or method used to avoid the explicit mapping is to use learning algorithms that only require dot products between the vectors in V, and choose the mapping such that these high-dimensional dot products can be computed within the original space, by means of a kernel function.
For 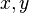 on
on 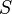 , certain functions
, certain functions 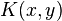 can be expressed as an inner product (usually in a different space). K is often referred to as a kernel or a kernel function. The word kernel is used in different ways throughout mathematics.
can be expressed as an inner product (usually in a different space). K is often referred to as a kernel or a kernel function. The word kernel is used in different ways throughout mathematics.
If one is insightful regarding a particular machine learning problem, one may manually construct 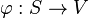 such that
such that
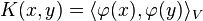
and verify that 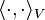 is indeed an inner product.
is indeed an inner product.
Furthermore, an explicit representation for  is not required: it suffices to know that V is an inner product space. Conveniently, based on Mercer's theorem, it suffices to equip S with one's choice of measure and verify that in fact,
is not required: it suffices to know that V is an inner product space. Conveniently, based on Mercer's theorem, it suffices to equip S with one's choice of measure and verify that in fact,  satisfies Mercer's condition.
satisfies Mercer's condition.
Mercer's theorem is stated in a general mathematical setting with implications in the theory of integral equations. However, the general statement is more than what is required for understanding the kernel trick. Given a finite observation set S, one can select the counting measure 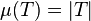 for all
for all 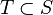 . Then the integral in Mercer's theorem reduces to a simple summation
. Then the integral in Mercer's theorem reduces to a simple summation
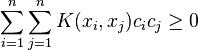
for all finite sequences of points x1, ..., xn of S and all choices of real numbers c1, ..., cn (cf. positive definite kernel).
Some algorithms that depend on arbitrary relationships in the native space would, in fact, have a linear interpretation in a different setting: the range space of . The linear interpretation gives us insight about the algorithm. Furthermore, there is often no need to compute directly during computation, as is the case with support vector machines. Some cite this running time shortcut as the primary benefit. Researchers also use it to justify the meanings and properties of existing algorithms.
The kernel trick was first published in 1964 by Aizerman et al.[1]
Theoretically, a kernel matrix K must be positive semi-definite (PSD).[2] Empirically, for machine learning heuristics, choices of K that do not satisfy Mercer's condition may still perform reasonably if K at least approximates the intuitive idea of similarity.[3] Regardless of whether K is a Mercer kernel, K can still be referred to a "kernel". Suppose K is any square matrix, then 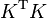 is a PSD matrix.
is a PSD matrix.
Applications
It has been applied to several kinds of algorithm in machine learning and statistics, including:
- Perceptrons
- Support vector machines
- Principal component analysis
- Canonical correlation analysis
- Fisher's linear discriminant analysis
- Cluster analysis
Commonly used kernels in such algorithms include the RBF and polynomial kernels, representing a mapping of vectors in  into a much richer feature space over degree-
into a much richer feature space over degree- polynomials of the original variables:[4]
polynomials of the original variables:[4]
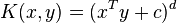
where  is a constant trading off the influence of higher-order versus lower-order terms in the polynomial.
For
is a constant trading off the influence of higher-order versus lower-order terms in the polynomial.
For  , this
, this  is the inner product in a feature space induced by the mapping
is the inner product in a feature space induced by the mapping
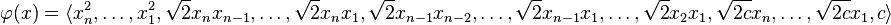
The kernel trick here lies in working in an  -dimensional space, without ever explicitly transforming the original data points into that space, but instead relying on algorithms that only need to compute inner products
-dimensional space, without ever explicitly transforming the original data points into that space, but instead relying on algorithms that only need to compute inner products 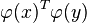 within that space, which are identical to and can thus cheaply be computed in the original space using only
within that space, which are identical to and can thus cheaply be computed in the original space using only  multiplications.
multiplications.
References
- ↑ M. Aizerman, E. Braverman, and L. Rozonoer (1964). "Theoretical foundations of the potential function method in pattern recognition learning". Automation and Remote Control 25: 821–837.
- ↑ Mehryar Mohri, Afshin Rostamizadeh, Ameet Talwalkar (2012) Foundations of Machine Learning, The MIT Press ISBN 9780262018258.
- ↑ http://www.svms.org/mercer/
- ↑ http://www.cs.tufts.edu/~roni/Teaching/CLT2008S/LN/lecture18.pdf
External links
See also
- Kernel methods
- Polynomial kernel
- Integral transforms
- Hilbert space, specifically Reproducing kernel Hilbert space
- Mercer's theorem