Katz's back-off model
Katz back-off is a generative n-gram language model that estimates the conditional probability of a word given its history in the n-gram. It accomplishes this estimation by "backing-off" to models with smaller histories under certain conditions. By doing so, the model with the most reliable information about a given history is used to provide the better results.
The method
The equation for Katz's back-off model is: [1]
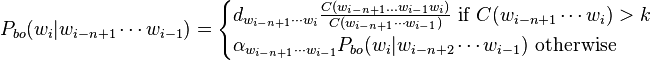
where,
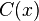 = number of times x appears in training
= number of times x appears in training = ith word in the given context
= ith word in the given context
Essentially, this means that if the n-gram has been seen more than k times in training, the conditional probability of a word given its history is proportional to the maximum likelihood estimate of that n-gram. Otherwise, the conditional probability is equal to the back-off conditional probability of the "(n-1)-gram".
The more difficult part is determining the values for k, d and α.
 is the least important of the parameters. It is usually chosen to be 0. However, empirical testing may find better values for k.
is the least important of the parameters. It is usually chosen to be 0. However, empirical testing may find better values for k.
 is typically the amount of discounting found by Good-Turing estimation. In other words, if Good-Turing estimates
is typically the amount of discounting found by Good-Turing estimation. In other words, if Good-Turing estimates  as
as 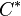 , then
, then 
To compute  , it is useful to first define a quantity β, which is the left-over probability mass for the (n-1)-gram:
, it is useful to first define a quantity β, which is the left-over probability mass for the (n-1)-gram:
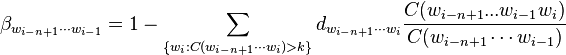
Then the back-off weight, α, is computed as follows:

Discussion
This model generally works well in practice, but fails in some circumstances. For example, suppose that the bigram "a b" and the unigram "c" are very common, but the trigram "a b c" is never seen. Since "a b" and "c" are very common, it may be significant (that is, not due to chance) that "a b c" is never seen. Perhaps it's not allowed by the rules of the grammar. Instead of assigning a more appropriate value of 0, the method will back off to the bigram and estimate P(c | b), which may be too high.[2]
References
- ↑ Katz, S. M. (1987). Estimation of probabilities from sparse data for the language model component of a speech recogniser. IEEE Transactions on Acoustics, Speech, and Signal Processing, 35(3), 400–401.
- ↑ Manning and Schütze, Foundations of Statistical Natural Language Processing, MIT Press (1999), ISBN 978-0-262-13360-9.