Karush–Kuhn–Tucker conditions
In mathematics, the Karush–Kuhn–Tucker (KKT) conditions (also known as the Kuhn–Tucker conditions) are first order necessary conditions for a solution in nonlinear programming to be optimal, provided that some regularity conditions are satisfied. Allowing inequality constraints, the KKT approach to nonlinear programming generalizes the method of Lagrange multipliers, which allows only equality constraints. The system of equations corresponding to the KKT conditions is usually not solved directly, except in the few special cases where a closed-form solution can be derived analytically. In general, many optimization algorithms can be interpreted as methods for numerically solving the KKT system of equations.[1]
The KKT conditions were originally named after Harold W. Kuhn, and Albert W. Tucker, who first published the conditions in 1951.[2] Later scholars discovered that the necessary conditions for this problem had been stated by William Karush in his master's thesis in 1939.[3][4]
Nonlinear optimization problem
Consider the following nonlinear optimization problem:

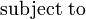

where x is the optimization variable,  is the objective or cost function,
is the objective or cost function,  are the inequality constraint functions, and
are the inequality constraint functions, and 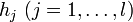 are the equality constraint functions. The numbers of inequality and equality constraints are denoted m and l, respectively.
are the equality constraint functions. The numbers of inequality and equality constraints are denoted m and l, respectively.
Necessary conditions
Suppose that the objective function 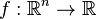 and the constraint functions
and the constraint functions 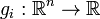 and
and 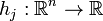 are continuously differentiable at a point
are continuously differentiable at a point  . If is a local minimum that satisfies some regularity conditions (see below), then there exist constants
. If is a local minimum that satisfies some regularity conditions (see below), then there exist constants  and
and 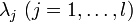 , called KKT multipliers, such that
, called KKT multipliers, such that

- Stationarity
- For maximizing f(x):

- For minimizing f(x):
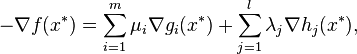
- Primal feasibility

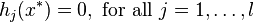
- Dual feasibility
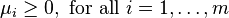
- Complementary slackness
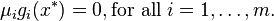
In the particular case 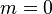 , i.e., when there are no inequality constraints, the KKT conditions turn into the Lagrange conditions, and the KKT multipliers are called Lagrange multipliers.
, i.e., when there are no inequality constraints, the KKT conditions turn into the Lagrange conditions, and the KKT multipliers are called Lagrange multipliers.
If some of the functions are non-differentiable, subdifferential versions of Karush–Kuhn–Tucker (KKT) conditions are available.[5]
Regularity conditions (or constraint qualifications)
In order for a minimum point to satisfy the above KKT conditions, the problem should satisfy some regularity conditions; the most used ones are listed below:
- Linearity constraint qualification: If
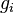 and
and 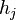 are affine functions, then no other condition is needed.
are affine functions, then no other condition is needed. - Linear independence constraint qualification (LICQ): the gradients of the active inequality constraints and the gradients of the equality constraints are linearly independent at .
- Mangasarian–Fromovitz constraint qualification (MFCQ): the gradients of the active inequality constraints and the gradients of the equality constraints are positive-linearly independent at .
- Constant rank constraint qualification (CRCQ): for each subset of the gradients of the active inequality constraints and the gradients of the equality constraints the rank at a vicinity of is constant.
- Constant positive linear dependence constraint qualification (CPLD): for each subset of the gradients of the active inequality constraints and the gradients of the equality constraints, if it is positive-linear dependent at then it is positive-linear dependent at a vicinity of .
- Quasi-normality constraint qualification (QNCQ): if the gradients of the active inequality constraints and the gradients of the equality constraints are positive-linearly dependent at with associated multipliers
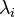 for equalities and
for equalities and  for inequalities, then there is no sequence
for inequalities, then there is no sequence  such that
such that  and
and 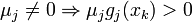 .
. - Slater condition: for a convex problem, there exists a point
 such that
such that  and
and 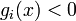 for all
for all  active in .
active in .
( ) is positive-linear dependent if there exists
) is positive-linear dependent if there exists  not all zero such that
not all zero such that  .
.
It can be shown that LICQ⇒MFCQ⇒CPLD⇒QNCQ, LICQ⇒CRCQ⇒CPLD⇒QNCQ (and the converses are not true), although MFCQ is not equivalent to CRCQ[6] . In practice weaker constraint qualifications are preferred since they provide stronger optimality conditions.
Sufficient conditions
In some cases, the necessary conditions are also sufficient for optimality. In general, the necessary conditions are not sufficient for optimality and additional information is necessary, such as the Second Order Sufficient Conditions (SOSC). For smooth functions, SOSC involve the second derivatives, which explains its name.
The necessary conditions are sufficient for optimality if the objective function is a concave function, the inequality constraints  are continuously differentiable convex functions and the equality constraints
are continuously differentiable convex functions and the equality constraints  are affine functions.
are affine functions.
It was shown by Martin in 1985 that the broader class of functions in which KKT conditions guarantees global optimality are the so-called Type 1 invex functions.[7][8]
Economics
Often in mathematical economics the KKT approach is used in theoretical models in order to obtain qualitative results. For example, consider a firm that maximizes its sales revenue subject to a minimum profit constraint. Letting Q be the quantity of output produced (to be chosen), R(Q) be sales revenue with a positive first derivative and with a zero value at zero output, C(Q) be production costs with a positive first derivative and with a non-negative value at zero output, and  be the positive minimal acceptable level of profit, then the problem is a meaningful one if the revenue function levels off so it eventually is less steep than the cost function. The problem expressed in the previously given minimization form is
be the positive minimal acceptable level of profit, then the problem is a meaningful one if the revenue function levels off so it eventually is less steep than the cost function. The problem expressed in the previously given minimization form is
- Minimize
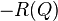 subject to
subject to  and
and 
and the KKT conditions are

![Q[({\text{d}}R/{\text{d}}Q)(1+\mu )-\mu ({\text{d}}C/{\text{d}}Q)]=0,](/2014-wikipedia_en_all_02_2014/I/media/c/8/7/5/c875e6be7b038166ef781634815dff69.png)


![\mu [R(Q)-C(Q)-G_{{min}}]=0.](/2014-wikipedia_en_all_02_2014/I/media/9/3/1/0/93108cbe94fcc21530d8fbf039a0225d.png)
Since Q=0 would violate the minimum profit constraint, we have Q>0 and hence the third condition implies that the first condition holds with equality. Solving that equality gives

Because it was given that 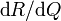 and
and 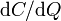 are strictly positive, this inequality along with the non-negativity condition on
are strictly positive, this inequality along with the non-negativity condition on  guarantees that is positive and so the revenue-maximizing firm operates at a level of output at which marginal revenue is less than marginal cost — a result that is of interest because it contrasts with the behavior of a profit maximizing firm, which operates at a level at which they are equal.
guarantees that is positive and so the revenue-maximizing firm operates at a level of output at which marginal revenue is less than marginal cost — a result that is of interest because it contrasts with the behavior of a profit maximizing firm, which operates at a level at which they are equal.
Value function
If we reconsider the optimization problem as a maximization problem with constant inequality constraints,

The value function is defined as
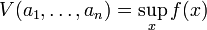
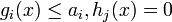

(So the domain of V is  )
)
Given this definition, each coefficient, 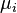 , is the rate at which the value function increases as
, is the rate at which the value function increases as  increases. Thus if each is interpreted as a resource constraint, the coefficients tell you how much increasing a resource will increase the optimum value of our function f. This interpretation is especially important in economics and is used, for instance, in utility maximization problems.
increases. Thus if each is interpreted as a resource constraint, the coefficients tell you how much increasing a resource will increase the optimum value of our function f. This interpretation is especially important in economics and is used, for instance, in utility maximization problems.
Generalizations
With an extra constant multiplier  , which may be zero, in front of
, which may be zero, in front of 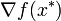 the KKT stationarity conditions turn into
the KKT stationarity conditions turn into
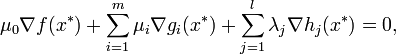
which are called the Fritz John conditions.
The KKT conditions belong to a wider class of the First Order Necessary Conditions (FONC), which allow for non-smooth functions using subderivatives.
See also
- Farkas' lemma
- Big M method - corresponding technique for linear optimization problems
References
- ↑ Boyd, Stephen; Vandenberghe, Lieven (2004). Convex Optimization. Cambridge: Cambridge University Press. p. 244. ISBN 0-521-83378-7. MR 2061575.
- ↑ Kuhn, H. W.; Tucker, A. W. (1951). "Nonlinear programming". Proceedings of 2nd Berkeley Symposium. Berkeley: University of California Press. pp. 481–492. MR 47303
- ↑ W. Karush (1939). Minima of Functions of Several Variables with Inequalities as Side Constraints. M.Sc. Dissertation. Dept. of Mathematics, Univ. of Chicago, Chicago, Illinois.
- ↑ Kjeldsen, Tinne Hoff (2000). "A contextualized historical analysis of the Kuhn-Tucker theorem in nonlinear programming: the impact of World War II". Historia Math. 27 (4): 331–361. MR 1800317.
- ↑ Ruszczyński, Andrzej (2006). Nonlinear Optimization. Princeton, NJ: Princeton University Press. pp. xii+454. ISBN 978-0691119151. MR 2199043.
- ↑ Rodrigo Eustaquio, Elizabeth Karas, and Ademir Ribeiro. Constraint Qualification for Nonlinear Programming (Technical report). Federal University of Parana.
- ↑ Martin, D. H. (1985). "The Essence of Invexity". J. Optim. Theory Appl. 47 (1): 65–76. doi:10.1007/BF00941316.
- ↑ Hanson, M. A. (1999). "Invexity and the Kuhn-Tucker Theorem". J. Math. Anal. Appl. 236 (2): 594–604. doi:10.1006/jmaa.1999.6484.
Further reading
- Andreani, R.; Martínez, J. M.; Schuverdt, M. L. (2005). "On the relation between constant positive linear dependence condition and quasinormality constraint qualification". Journal of Optimization Theory and Applications 125 (2): 473–485. doi:10.1007/s10957-004-1861-9.
- Avriel, Mordecai (2003). Nonlinear Programming: Analysis and Methods. Dover. ISBN 0-486-43227-0.
- Boyd, S.; Vandenberghe, L. (2004). Convex Optimization. Cambridge University Press. ISBN 0-521-83378-7.
- Nocedal, J.; Wright, S. J. (2006). Numerical Optimization. New York: Springer. ISBN 978-0-387-30303-1.
External links
- Karush–Kuhn–Tucker conditions with derivation and examples
- Examples and Tutorials on the KKT Conditions