Information geometry
Information geometry is a branch of mathematics that applies the techniques of differential geometry to the field of probability theory. This is done by taking probability distributions for a statistical model as the points of a Riemannian manifold, forming a statistical manifold. The Fisher information metric provides the Riemannian metric.
Information geometry reached maturity through the work of Shun'ichi Amari and other Japanese mathematicians in the 1980s. Amari and Nagaoka's book, Methods of Information Geometry,[1] is cited by most works of the relatively young field due to its broad coverage of significant developments attained using the methods of information geometry up to the year 2000. Many of these developments were previously only available in Japanese-language publications.
Introduction
The following introduction is based on Methods of Information Geometry.[1]
Information and probability
Define an n-set to be a set V with cardinality  . To choose an element v (value, state, point, outcome) from an n-set V, one needs to specify
. To choose an element v (value, state, point, outcome) from an n-set V, one needs to specify 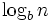 b-sets (default b=2), if one disregards all but the cardinality. That is,
b-sets (default b=2), if one disregards all but the cardinality. That is, 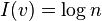 nats of information are required to specify v; equivalently,
nats of information are required to specify v; equivalently, 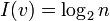 bits are needed.
bits are needed.
By considering the occurrences  of values from
of values from  , one has an alternate way to refer to
, one has an alternate way to refer to 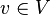 , through . First, one chooses an occurrence
, through . First, one chooses an occurrence 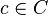 , which requires information of
, which requires information of  bits. To specify v, one subtracts the excess information used to choose one
bits. To specify v, one subtracts the excess information used to choose one  from all those
linked to
from all those
linked to  , this is
, this is 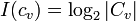 . Then,
. Then,  is the number of
is the number of 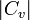 portions fitting into
portions fitting into  . Thus, one needs
. Thus, one needs  bits to choose one of them. So the information (variable size, code length, number of bits) needed to refer to , considering its occurrences in a message is
bits to choose one of them. So the information (variable size, code length, number of bits) needed to refer to , considering its occurrences in a message is
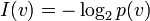
Finally,  is the normalized portion of information needed to code all occurrences of one . The averaged code length over all values is
is the normalized portion of information needed to code all occurrences of one . The averaged code length over all values is 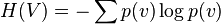 .
.
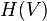 is called the entropy of a random variable .
is called the entropy of a random variable .
Statistical model, Parameters
With a probability distribution  one looks at a variable through an observation context like a message or an experimental setup.
one looks at a variable through an observation context like a message or an experimental setup.
The context can often be identified by a set of parameters through combinatorial reasoning. The parameters can have an arbitrary number of dimensions and can be very local or less so, as long as the context given by a certain ![\xi =[\xi ^{i}]\in {\mathbb {R}}^{n}](/2014-wikipedia_en_all_02_2014/I/media/4/b/4/4/4b440df4f6949dcc99c82ecdd4c14f79.png) produces every value of , i.e. the support
produces every value of , i.e. the support 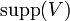 does not change as function of
does not change as function of  . Every determines one probability distribution for . Basically all distributions for which there exists an explicit analytical formula fall into this category (Binomial, Normal, Poisson, ...). The parameters in these cases have a concrete meaning in the underlying setup, which is a statistical model for the context of .
. Every determines one probability distribution for . Basically all distributions for which there exists an explicit analytical formula fall into this category (Binomial, Normal, Poisson, ...). The parameters in these cases have a concrete meaning in the underlying setup, which is a statistical model for the context of .
The parameters are quite different in nature from itself, because they do not describe , but the observation context for .
A parameterization of the form

with
 and
and 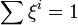 ,
,
that mixes different distributions 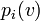 , is called a mixture distribution, mixture or
, is called a mixture distribution, mixture or  -parameterization or mixture for short. All such parameterizations are related through an affine transformation
-parameterization or mixture for short. All such parameterizations are related through an affine transformation 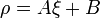 . A parameterization with such a transformation rule is called flat.
. A parameterization with such a transformation rule is called flat.
A flat parameterization for 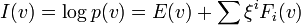 is an exponential or
is an exponential or  parameterization, because the parameters are in the exponent of
parameterization, because the parameters are in the exponent of 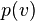 . There are several important distributions, like Normal and Poisson, that fall into this category. These distributions are collectively referred to as exponential family or -family. The -manifold for such distributions is not affine, but the
. There are several important distributions, like Normal and Poisson, that fall into this category. These distributions are collectively referred to as exponential family or -family. The -manifold for such distributions is not affine, but the 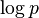 manifold is. This is called -affine. The parameterization
manifold is. This is called -affine. The parameterization 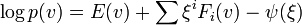 for the exponential family can be mapped to the one above by making
for the exponential family can be mapped to the one above by making  another parameter and extend
another parameter and extend ![[F_{i}]\rightarrow [F_{i},1]](/2014-wikipedia_en_all_02_2014/I/media/a/a/3/1/aa31359c1380f673205c94767f5c5321.png) .
.
Differential geometry applied to probability
In information geometry, the methods of differential geometry are applied to describe the space of probability distributions for one variable . This is done by using a coordinate or atlas 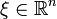 . Furthermore, the probability
. Furthermore, the probability  must be a differentiable and invertible function of . In this case, the
must be a differentiable and invertible function of . In this case, the ![[\xi ^{i}]](/2014-wikipedia_en_all_02_2014/I/media/2/f/4/9/2f499344a46c02d7899336e274b51de8.png) are coordinates of the -space, and the latter is a differential manifold
are coordinates of the -space, and the latter is a differential manifold  .
.
Derivatives are defined as is usual for a differentiable manifold:
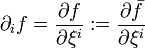
with  , for
, for 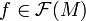 a real-valued function on .
a real-valued function on .
Given a function  on , one may "geometrize" it by taking it to define a new manifold. This is done by defining coordinate functions on this new manifold as
on , one may "geometrize" it by taking it to define a new manifold. This is done by defining coordinate functions on this new manifold as
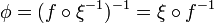 .
.
In this way one "geometricizes" a function , by encoding it into the coordinates used to describe the system.
For 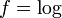 the inverse is
the inverse is  and the resulting manifold of points is called the -representation. The manifold itself is called the -representation. The
- or -representations, in the sense used here, does not refer to the parameterization families of the distribution.
and the resulting manifold of points is called the -representation. The manifold itself is called the -representation. The
- or -representations, in the sense used here, does not refer to the parameterization families of the distribution.
Tangent space
In standard differential geometry, the tangent space on a manifold at a point  is given by:
is given by:

In ordinary differential geometry, there is no canonical coordinate system on the manifold; thus, typically, all discussion must be with regard to an atlas, that is, with regard to functions on the manifold. As a result, tangent spaces and vectors are defined as operators acting on this space of functions. So, for example, in ordinary differential geometry, the basis vectors of the tangent space are the operators 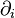 .
.
However, with probability distributions , one can calculate value-wise. So it is possible to express a tangent space vector directly as 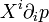 ( -representation ) or
( -representation ) or 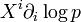 ( -representation ), and not as operators.
( -representation ), and not as operators.
alpha representation
Important functions of are coded by a parameter  with the important values
with the important values  ,
,  and
and  :
:
- mixed or -representation (
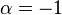 ):
): 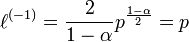
- exponential or -representation (
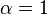 ):
): 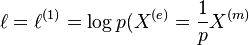 )
) - -representation (
 ):
): 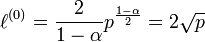 (
( 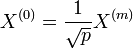 )
)
Distributions that allow a flat parameterization 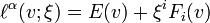 are called collectively -family ( -, - or -family ) of distributions and the according manifold is called -affine.
are called collectively -family ( -, - or -family ) of distributions and the according manifold is called -affine.
The tangent vector is 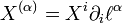 .
.
Inner product
One may introduce an inner product on the tangent space of manifold at point as a linear, symmetric and positive definite map
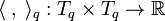 .
.
This allows a Riemannian metric to be defined; the resulting manifold is a Riemannian manifold. All of the usual concepts of ordinary differential geometry carry over, including the norm
 ,
,
the line element  , the volume element
, the volume element 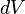 , and the cotangent space
, and the cotangent space
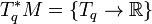
that is, the dual space to the tangent space  . From these, one may construct tensors, as usual.
. From these, one may construct tensors, as usual.
Fisher metric as inner product
For probability manifolds such an inner product is given by the Fisher information metric.
Here are equivalent formulas of the Fisher information metric.
-
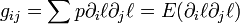
 , the
, the  base vector in the -representation, is also called the score.
base vector in the -representation, is also called the score. -
 ,
,
because

-
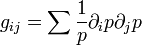
-
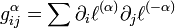 . This is the same for
. This is the same for 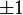 and families.
and families.
-
![g_{{ij}}=D[\partial _{i}\partial _{j}||]=D[||\partial _{i}\partial _{j}]=-D[\partial _{i}||\partial _{j}]](/2014-wikipedia_en_all_02_2014/I/media/e/0/8/3/e08385e2ef1db9023ab4b8ea486b32ac.png)
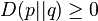 with mimimum for
with mimimum for  entails
entails ![D[\partial _{i}||]=\partial _{i}D(p||p)=0](/2014-wikipedia_en_all_02_2014/I/media/e/c/b/5/ecb58d7141cb8926e1f52271bf1ec3c5.png) and
and ![D[||\partial _{j}]=\partial '_{j}D(p||p)=0](/2014-wikipedia_en_all_02_2014/I/media/f/7/7/1/f7714e9f9f8ab9c72cb9a29ac22b8307.png)
is applied only to the first parameter, and 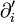 only to the second.
only to the second.
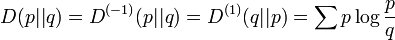 is the Kullback-Leibler divergence or relative entropy applicable to the -families.
is the Kullback-Leibler divergence or relative entropy applicable to the -families.
![g_{{ij}}=-D[\partial _{i}||\partial _{j}]=-\partial '_{j}\partial _{i}\sum {p(\log p-\log ;q)}=\sum {\frac {\partial _{i}p\partial _{j}q}{q}}=[p=q]=\sum {p\partial _{i}\ell \partial _{j}\ell }](/2014-wikipedia_en_all_02_2014/I/media/a/f/a/e/afae3bc9abf4183d0a3d44f89f015e28.png)
For one has
one has 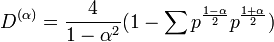 .
.
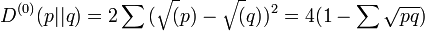 is the Hellinger distance applicable to the -family.
is the Hellinger distance applicable to the -family. ![-D^{{(0)}}[\partial _{i}||\partial _{j}]](/2014-wikipedia_en_all_02_2014/I/media/8/5/6/9/8569881e4b3891621171db787421b392.png) also evaluates to the Fisher metric.
also evaluates to the Fisher metric.
This relation with a divergence 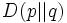 will be revisited further down.
will be revisited further down.
The Fisher metric is motivated by
- it satisfying the requirements for an inner product
- its invariance for a sufficient statistic deterministic mapping from one variable to another and more general
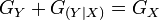 for
for 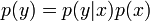 , i.e. a broadened distribution has smaller
, i.e. a broadened distribution has smaller 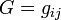 .
.
- it being the Cramér–Rao bound.
![E[X^{{(e)}}]=E[X^{i}\partial _{i}\log p]=0](/2014-wikipedia_en_all_02_2014/I/media/9/3/c/6/93c687acfd62c22437ab3275621e62f1.png) , therefore any
, therefore any 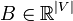 satisfying
satisfying ![E[B]=0](/2014-wikipedia_en_all_02_2014/I/media/a/c/e/f/acef7da72afd6b266999916544f71a69.png) belongs to
belongs to 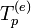 .
.
For any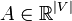 one has
one has ![E[A-E[A]]=0](/2014-wikipedia_en_all_02_2014/I/media/4/e/3/7/4e370a41a1efe0aadbafc1301ce739b6.png) , therefore
, therefore ![A-E[A]\in T_{p}^{{(e)}}](/2014-wikipedia_en_all_02_2014/I/media/4/c/2/0/4c201a6aab7a774320e5f7881969474e.png) .
.
![X(E[A])=\sum X^{{(m)}}A=\sum X^{i}\partial _{i}A=\sum X^{i}p\partial _{i}\log pA=E[X^{{(e)}}A]=E[X^{{(e)}}A]-0=E[X^{{(e)}}A]-E[X^{{(e)}}E[A]]=E[X^{{(e)}}(A-E[A])]=E[X^{{(e)}}Y^{{(e)}}]=\langle X,Y\rangle](/2014-wikipedia_en_all_02_2014/I/media/0/8/f/3/08f30ed2f346b4ca3af39a0a3ffe3470.png) .
.
So![Y^{{(e)}}=A-E[A]={\text{grad}}E[A]](/2014-wikipedia_en_all_02_2014/I/media/2/6/c/0/26c0861d61645f42f41e7f80b77885cc.png) and therefore
and therefore ![||dE[A]||^{2}=\langle Y^{{(e)}},Y^{{(e)}}\rangle =E[(A-E[A])^{2}]=V[A]](/2014-wikipedia_en_all_02_2014/I/media/5/a/7/0/5a70ae48a7d246b65dab641af5ec2c11.png) .
.
![||dE[A]||^{2}=G^{{-1}}](/2014-wikipedia_en_all_02_2014/I/media/9/6/2/9/9629c363a4b6eabac82dead7f5a70de5.png) and with inefficient estimator one gets the Cramér–Rao bound
and with inefficient estimator one gets the Cramér–Rao bound ![V[A]\geq G^{{-1}}](/2014-wikipedia_en_all_02_2014/I/media/4/d/7/e/4d7e1f8996e46f8650a87d896ea2265f.png) .
.
Affine connection
Like commonly done on Riemann manifolds, one may define an affine connection (or covariant derivative)
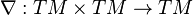
Given vector fields  and
and  lying in the tangent bundle
lying in the tangent bundle  , the affine connection
, the affine connection 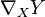 describes how to differentiate the vector field along the direction. It is itself a vector field; it is the sum of the infinitesimal change in the vector field , as one moves along the direction , plus the infinitessimal change of the vector due to its parallel transport along the direction . That is, it takes into account the changing nature of what it means to move a coordinate system in a "parallel" fashion, as one moves about in the manifold. In terms of the basis vectors
describes how to differentiate the vector field along the direction. It is itself a vector field; it is the sum of the infinitesimal change in the vector field , as one moves along the direction , plus the infinitessimal change of the vector due to its parallel transport along the direction . That is, it takes into account the changing nature of what it means to move a coordinate system in a "parallel" fashion, as one moves about in the manifold. In terms of the basis vectors  , one has the components:
, one has the components:
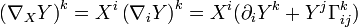
The  are Christoffel symbols. The affine connection may be used for defining curvature and torsion, like is usual in Riemannian geometry.
are Christoffel symbols. The affine connection may be used for defining curvature and torsion, like is usual in Riemannian geometry.
Alpha connection
A non-metric connection is not determined by a metric tensor  ; instead, it is and restricted by the requirement that the parallel transport
; instead, it is and restricted by the requirement that the parallel transport 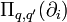 between points and
between points and  must be a linear combination of the base vectors in
must be a linear combination of the base vectors in 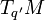 . Here,
. Here,

expresses the parallel transport of  as linear combination of the base vectors in , i.e. the new minus the change. Note that it is not a tensor (does not transform as a tensor).
as linear combination of the base vectors in , i.e. the new minus the change. Note that it is not a tensor (does not transform as a tensor).
For such a metric, one can construct a dual connection 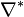 to make
to make
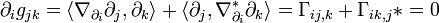 ,
,
for parallel transport using  and .
and .
For the mentioned -families the affine connection is called the -connection and can also be expressed in more ways.
![\Gamma _{{ij,k}}^{{(\alpha )}}=E[(\partial _{i}\partial _{j}\ell +{\frac {1-\alpha }{2}}\partial _{i}\ell \partial _{j}\ell )\partial _{k}\ell ]](/2014-wikipedia_en_all_02_2014/I/media/f/f/8/b/ff8b95e2322b30bdbff172f1f78b0e76.png)
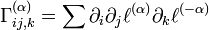
![\Gamma _{{ij,k}}^{{(\alpha )}}=-D^{{(\alpha )}}[\partial _{i}\partial _{j}||\partial _{k}]\;(D^{{(-\alpha )}}[p||q]=D^{{(\alpha )}}[q||p])](/2014-wikipedia_en_all_02_2014/I/media/5/7/5/f/575f56f5032d545f200f67ba2a80d53b.png)
For 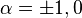 :
:
-
 is a metric connection and
is a metric connection and  with
with ![T_{{ijk}}={\frac {1}{2}}E[\partial _{i}l\partial _{j}l\partial _{k}l]](/2014-wikipedia_en_all_02_2014/I/media/5/c/9/e/5c9ec6535306b6dc98bdeee7806182a5.png) .
. -
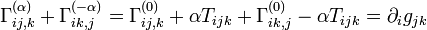 ,
,
i.e.
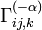 is dual to
is dual to 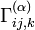 with respect to the Fisher metric.
with respect to the Fisher metric. - If
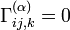 this is called -affine. Its dual is then
this is called -affine. Its dual is then  -affine.
-affine.
 ,
i.e. 0-affine, and hence
,
i.e. 0-affine, and hence  , i.e. 1-affine.
, i.e. 1-affine.
Divergence
A function of two distributions (points) with minimum for entails and .
is applied only to the first parameter, and only to the second.
is the direction, which brought the two points to be equal, when applied to the first parameter, and to diverge again, when applied to the second parameter,
i.e. ![D[\partial _{i}||]=-D[||\partial _{i}]](/2014-wikipedia_en_all_02_2014/I/media/0/6/b/9/06b99d1126294f79ef4eaa56d8110a2b.png) . The sign cancels in
. The sign cancels in ![D[\partial _{i}\partial _{j}||]=D[||\partial _{i}\partial _{j}]=-D[\partial _{i}||\partial _{j}]](/2014-wikipedia_en_all_02_2014/I/media/b/1/2/7/b127bee735837d00735441bcdd94c38f.png) ,
which we can define to be a metric
,
which we can define to be a metric ![g_{{ij}}=-D[\partial _{i}||\partial _{j}]](/2014-wikipedia_en_all_02_2014/I/media/9/4/8/a/948af412178118131188c0d3aa9ffd34.png) , if always positive.
, if always positive.
The absolute derivative of along yields candidates for dual connections
![\partial _{i}g_{{jk}}=-D[\partial _{i}\partial _{j}||\partial _{k}]-D[\partial _{j}||\partial _{i}\partial _{k}]=\Gamma _{{ij,k}}+\Gamma _{{ik,j}}^{*}](/2014-wikipedia_en_all_02_2014/I/media/b/3/2/a/b32a5a54037990cdcde2cea2207988dd.png) .
This metric and the connections relate to the Taylor series expansion for the first parameter or second parameter.
Here for the first parameter:
.
This metric and the connections relate to the Taylor series expansion for the first parameter or second parameter.
Here for the first parameter:
![{\begin{aligned}&D[p||q]={\frac {1}{2}}g_{{ij}}(q)\Delta \xi ^{i}\Delta \xi ^{j}+{\frac {1}{6}}h_{{ijk}}\Delta \xi ^{i}\Delta \xi ^{j}\Delta \xi ^{k}+o(||\Delta \xi ||^{3})\\&h_{{ijk}}=D[\partial _{i}\partial _{j}\partial _{k}||]\\&\partial _{i}g_{{jk}}=\partial _{i}D[\partial _{j}\partial _{k}||]=D[\partial _{i}\partial _{j}\partial _{k}||]+D[\partial _{j}\partial _{k}||\partial _{i}]=h_{{ijk}}-\Gamma _{{jk,i}}\\&h_{{ijk}}=\partial _{i}g_{{jk}}+\Gamma _{{jk,i}}.\end{aligned}}](/2014-wikipedia_en_all_02_2014/I/media/0/2/a/0/02a0c85169a0407ca65ea6ac334fb3c9.png)
The term is called the divergence or contrast function. A good choice is  with convex for
with convex for 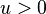 .
From Jensen's inequality it follows that
.
From Jensen's inequality it follows that 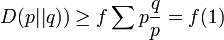 and, for
and, for  , we have
, we have
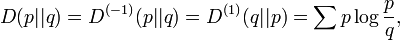
which is the Kullback-Leibler divergence or relative entropy
applicable to the -families.
In the above,
![g_{{ij}}=-D[\partial _{i}||\partial _{j}]=-\partial '_{j}\partial _{i}\sum {p(\log ;p-\log ;q)}=\sum {\frac {\partial _{i}p\partial _{j}q}{q}}=\sum \partial _{i}p\partial _{j}\log q=[p=q]=\sum {p\partial _{i}\ell \partial _{j}\ell }](/2014-wikipedia_en_all_02_2014/I/media/4/e/d/d/4eddcb45cdfb3a2838878bca74f3ec73.png)
is the Fisher metric.
For a different yields
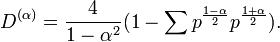
The Hellinger distance applicable to the -family is
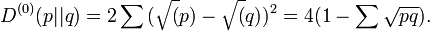
In this case, also evaluates to the Fisher metric.
Canonical divergence
We now consider two manifolds  and
and  , represented by two sets of coordinate functions
, represented by two sets of coordinate functions ![[\theta ^{i}]](/2014-wikipedia_en_all_02_2014/I/media/7/2/b/f/72bf799e9ff0181096459f5bd08d0c63.png) and
and ![[\eta _{j}]](/2014-wikipedia_en_all_02_2014/I/media/8/3/1/f/831f80fb1bc2351f71a7a22480897433.png) . The corresponding tangent space basis vectors will be denoted by
. The corresponding tangent space basis vectors will be denoted by
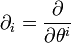 and
and 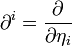 .
The bilinear map
.
The bilinear map 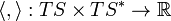 associates a quantity
associates a quantity  to the dual base vectors. This defines an affine connection for and affine connection for that keep
to the dual base vectors. This defines an affine connection for and affine connection for that keep 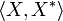 constant for parallel transport of
constant for parallel transport of 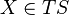 and
and 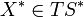 , defined through and .
, defined through and .
If is flat, then there exists a coordinate system , that does not change over .
In order to keep 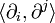 constant,
constant,  must not change either, i.e. is also flat. Furthermore, in this case, we can choose coordinate systems such that
must not change either, i.e. is also flat. Furthermore, in this case, we can choose coordinate systems such that
If results as a function on , then making 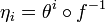 , both coordinate system function sets describe .
The connections are such, though, that makes flat and makes flat. This dual space is denoted as
, both coordinate system function sets describe .
The connections are such, though, that makes flat and makes flat. This dual space is denoted as 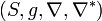 .
.
- Because of the linear transform between the flat coordinate systems, we have
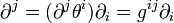 and
and  .
.
- Because
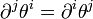 and so for
and so for  it is possible to define two potentials
it is possible to define two potentials  and
and 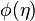 through
through
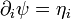 and
and 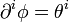 ( Legendre transform ).
These are
( Legendre transform ).
These are 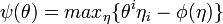 and
and 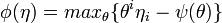 .
. - Then
 and
and
 .
.

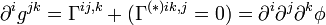
This naturally leads to the following definition of a canonical divergence:

Note the summation that is a representation of the metric due to 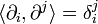 .
.
Properties of divergence
The meaning of the canonical divergence depends on the meaning of the metric
and vice versa ( ).
For the  metric (Fisher metric) with the dual connections this is the relative entropy.
For the self-dual Euclidian space
metric (Fisher metric) with the dual connections this is the relative entropy.
For the self-dual Euclidian space  leads to
leads to 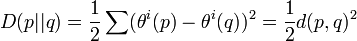
Similar to the Euclidian space the following holds:
- Triangular relation:
 (just substitute
(just substitute 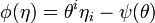 )
)
If
 is not dually flat then this generalizes to:
is not dually flat then this generalizes to:
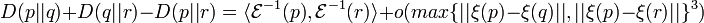
The last part drops in case of dual flatness. is the exponential map.
is the exponential map. - Pythagorean Theorem: For and
 meeting on orthogonal lines at (
meeting on orthogonal lines at ( 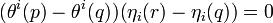 )
)
For
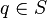 and
and  with a -autoparallel sub-manifold
with a -autoparallel sub-manifold 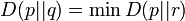 implies that the
-geodesic connecting and is orthogonal to .
implies that the
-geodesic connecting and is orthogonal to . - By projecting
 onto
onto 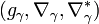 of a curve
of a curve ![\gamma :[a,b]\rightarrow S](/2014-wikipedia_en_all_02_2014/I/media/c/6/c/2/c6c2cdea6bada1ce7c180bc6c1393193.png) one can calculate
one can calculate
the divergence of the curve
 where
where 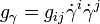 and
and  with
with 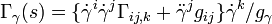 .
With
.
With 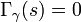 this becomes
this becomes 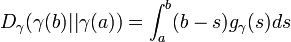 .
.
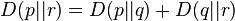
For an autoparallel sub-manifold parallel transport in it can be expressed with the sub-manifold's base vectors, i.e. 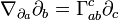 .
A one-dimensional autoparallel sub-manifold is a geodesic.
.
A one-dimensional autoparallel sub-manifold is a geodesic.
Canonical divergence for the exponential family
For the exponential family ![p(v;\theta )=exp[C(v)+\theta ^{i}F_{i}(v)-\psi (\theta )]](/2014-wikipedia_en_all_02_2014/I/media/b/b/f/9/bbf9be185a5ba848729f21285e93eb3a.png) one has
one has ![exp[\psi (\theta )]=\sum (C(v)+\theta ^{i}F_{i})](/2014-wikipedia_en_all_02_2014/I/media/c/4/0/8/c4080b01e797731981157e81242a9171.png) .
Applying on both sides yields
.
Applying on both sides yields ![\eta _{i}(\theta )=\partial _{i}\psi (\theta )=\sum F_{i}(v)p(v;\theta )=E[F_{i}]](/2014-wikipedia_en_all_02_2014/I/media/f/f/f/5/fff5033ce78d3a3d8b7ec1408e3d4f71.png) .
The other potential
.
The other potential ![\phi (\theta )=\theta ^{i}\eta _{i}(\theta )-\psi (\theta )=\theta ^{i}\sum pF_{i}-\psi =E[\log ;p-C]=-H(p)-E[C]](/2014-wikipedia_en_all_02_2014/I/media/4/b/f/1/4bf15d309aba2e1f179a836b9b68d12d.png) (
(  is entropy,
is entropy,
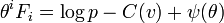 and
and ![E[\psi (\theta )]=\psi (\theta )](/2014-wikipedia_en_all_02_2014/I/media/a/f/6/8/af689a01d09fbe14a4760ed20f752c8b.png) was used).
was used).
![g_{{ij}}=E[\partial _{i}\ell \partial _{j}\ell ]=E[(F_{i}-\eta _{i})(F_{j}-\eta _{j})]=V[\eta ]](/2014-wikipedia_en_all_02_2014/I/media/1/d/3/2/1d32412442c5a21f3c17ce8d68b5d039.png) is the covariance of , the Cramér–Rao bound,
i.e. an efficient estimator must be exponential.
is the covariance of , the Cramér–Rao bound,
i.e. an efficient estimator must be exponential.
The canonical divergence is given by the Kullback-Leibler divergence  and the triangulation is
and the triangulation is  .
.
The minimal divergence to a sub-manifold given by a restriction like some constant 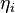 means maximizing
means maximizing ![H(p)+E[C]](/2014-wikipedia_en_all_02_2014/I/media/f/f/4/8/ff4839590e64201665493e6d48a65c66.png) .
With
.
With 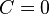 this corresponds to the maximum entropy principle.
this corresponds to the maximum entropy principle.
Canonical divergence for general alpha families
For general -affine manifolds with 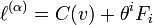 one has:
one has:
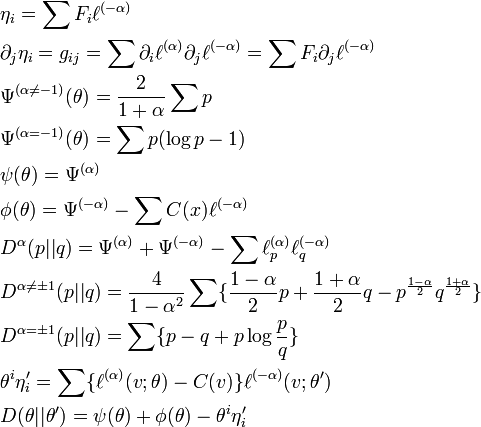
The connection induced by the divergence is not flat unless .
Then the Pythagorean theorem for two curves intersecting orthogonally at is:

History
The history of information geometry is associated with the discoveries of at least the following people, and many others
- Sir Ronald Aylmer Fisher
- Harald Cramér
- Calyampudi Radhakrishna Rao
- Harold Jeffreys
- Solomon Kullback
- Richard Leibler
- Claude Shannon
- Imre Csiszár
- Cencov
- Bradley Efron
- Paul Vos
- Shun'ichi Amari
- Hiroshi Nagaoka
- Robert Kass
- Shinto Eguchi
- Ole Barndorff-Nielsen
- Frank Nielsen
- Giovanni Pistone
- Bernard Hanzon
- Damiano Brigo
Applications
Information geometry can be applied where parametrized distributions play a role.
Here an incomplete list:
- statistical inference
- time series and linear systems
- quantum systems
- neuronal networks
- machine learning
- statistical mechanics
- biology
- statistics
- mathematical finance
See also
References
- ↑ 1.0 1.1 Shun'ichi Amari, Hiroshi Nagaoka - Methods of information geometry, Translations of mathematical monographs; v. 191, American Mathematical Society, 2000 (ISBN 978-0821805312)
Further reading
- Shun'ichi Amari, Hiroshi Nagaoka - Methods of information geometry, Translations of mathematical monographs; v. 191, American Mathematical Society, 2000 (ISBN 978-0821805312)
- Shun'ichi Amari - Differential-geometrical methods in statistics, Lecture notes in statistics, Springer-Verlag, Berlin, 1985.
- M. Murray and J. Rice - Differential geometry and statistics, Monographs on Statistics and Applied Probability 48, Chapman and Hall, 1993.
- R. E. Kass and P. W. Vos - Geometrical Foundations of Asymptotic Inference, Series in Probability and Statistics, Wiley, 1997.
- N. N. Cencov - Statistical Decision Rules and Optimal Inference, Translations of Mathematical Monographs; v. 53, American Mathematical Society, 1982
- Giovanni Pistone, and Sempi, C. (1995). "An infinitedimensional geometric structure on the space of all the probability measures equivalent to a given one", Annals of Statistics. 23 (5), 1543–1561.
- Brigo, D, Hanzon, B, Le Gland, F, "Approximate nonlinear filtering by projection on exponential manifolds of densities", Bernoulli, 1999, Vol: 5, Pages: 495 - 534, ISSN: 1350-7265
- Brigo, D, Diffusion Processes, "Manifolds of Exponential Densities, and Nonlinear Filtering", In: Ole E. Barndorff-Nielsen and Eva B. Vedel Jensen, editor, Geometry in Present Day Science, World Scientific, 1999
- Arwini, Khadiga, Dodson, C. T. J. Information Geometry - Near Randomness and Near Independence, Lecture Notes in Mathematics Vol. 1953, Springer 2008 ISBN 978-3-540-69391-8
- Th. Friedrich, "Die Fisher-Information und symplektische Strukturen", Math. Nachrichten 153 (1991), 273-296.
External links
- Manifold Learning and its Applications AAAI 2010
- Information Geometry overview by Cosma Rohilla Shalizi, July 2010
- blog Computational Information Geometry Wonderland by Frank Nielsen
- pdf Information geometry for neural networks by Daniel Wagenaar