Index of dissimilarity
The index of dissimilarity is a demographic measure of the evenness with which two groups are distributed across the component geographic areas that make up a larger area. The index score can also be interpreted as the percentage of one of the two groups included in the calculation that would have to move to different geographic areas in order to produce a distribution that matches that of the larger area. The index of dissimilarity can also be used as a measure of inequality.
The basic formula for the index of dissimilarity is:
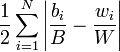
where (comparing a black and white population, for example):
- bi = the black population of the ith area, e.g. census tract
- B = the total black population of the large geographic entity for which the index of dissimilarity is being calculated.
- wi = the white population of the ith area
- W = the total white population of the large geographic entity for which the index of dissimilarity is being calculated.
The ID is applicable to any categorical variable (whether demographic or not) and because of its simple properties is useful for input into multidimensional scaling and clustering programs. It has been used extensively in the study of social mobility to compare distributions of origin (or destination) occupational categories.
See also
- Kullback-Leibler distance
- Isolation index