Hinge loss
In machine learning, the hinge loss is a loss function used for training classifiers. The hinge loss is used for "maximum-margin" classification, most notably for support vector machines (SVMs).[1] For an intended output t = ±1 and a classifier score y, the hinge loss of the prediction y is defined as
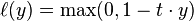
Note that y should be the "raw" output of the SVM's decision function, not the predicted class label. E.g., in linear SVMs, 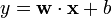 .
.
It can be seen that when 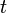 and
and  have the same sign (meaning predicts the right class) and
have the same sign (meaning predicts the right class) and 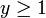 ,
, 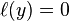 , but when they have opposite sign,
, but when they have opposite sign, 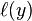 increases linearly with (one-sided error).
increases linearly with (one-sided error).
Extensions
While SVMs are commonly extended to multiclass classification in a one-vs.-all or one-vs.-one fashion,[2] there exists a "true" multiclass version of the hinge loss due to Crammer and Singer,[3] defined for a linear classifier as[4]

In structured prediction, the hinge loss can be further extended to structured output spaces. Structured SVMs use the following variant, where w denotes the SVM's parameters, φ the joint feature function, and Δ the Hamming loss:[5]
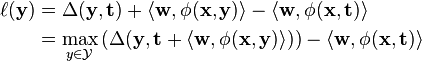
Optimization
The hinge loss is a convex function, so many of the usual convex optimizers used in machine learning can work with it. It is not differentiable, but has a subgradient with respect to model parameters 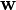 of a linear SVM with score function
of a linear SVM with score function 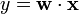 that is given by
that is given by
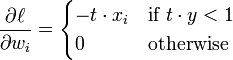
References
- ↑ Rosasco, L.; De Vito, E. D.; Caponnetto, A.; Piana, M.; Verri, A. (2004). "Are Loss Functions All the Same?". Neural Computation 16 (5): 1063–1076. doi:10.1162/089976604773135104. PMID 15070510.
- ↑ Duan, K. B.; Keerthi, S. S. (2005). "Which Is the Best Multiclass SVM Method? An Empirical Study". Multiple Classifier Systems. Lecture Notes in Computer Science 3541. p. 278. doi:10.1007/11494683_28. ISBN 978-3-540-26306-7.
- ↑ Crammer, Koby; and Singer, Yoram (2001). "On the algorithmic implementation of multiclass kernel-based vector machines". J. Machine Learning Research 2: 265–292.
- ↑ Robert C. Moore and John DeNero (2011). "L1 and L2 regularization for multiclass hinge loss models". Proc. Symp. on Machine Learning in Speech and Language Processing.
- ↑ Alex Spengler, Antoine Bordes and Patrick Gallinari (2010). "A comparison of discriminative classifiers for web news content extraction". RIAO.